[PaperNotes]2019.Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge

文章目录
Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge
Zotero链接: 从我的文库打开
| 标签1 | 标签2 | 标签3 | 标签4 |
|---|---|---|---|
| Federated Learning | Client Selection | FedCS | MEC |
回顾本文重点内容见Conclusion。论文阅读笔记仅供参考交流~
[TOC]
Abstract
虽然Google提出的Federated protocol中的客户端不需要公开自己的私有数据,但当某些客户端计算资源有限(例如,需要较长的更新时间)或无线信道条件较差(较长的上传时间)时,整个培训过程会变得低效。因此本文提出FedCS,其能够解决资源限制下的client selection问题,并能准许服务器聚合尽可能多的client updates以及提升ML模型的性能。
Contribution
FedCS – a protocol:该系统在MEC框架的操作人员积极地管理异类客户端的资源,能有效地运行FL。特别是FedCS为客户端在FL protocol下载、更新、上传ML模型设置了一个deadline。
Method

[6] T. Nishio, R. Shinkuma, T. Takahashi, and N. B. Mandayam, “Serviceoriented heterogeneous resource sharing for optimizing service latency in mobile cloud,” in Proc. of the International Workshop on Mobile Cloud Computing & Networking, July 2013, pp. 19–26. [7] S. Sardellitti, G. Scutari, and S. Barbarossa, “Joint optimization of radio and computational resources for multicell mobile-edge computing,” IEEE Transactions on Signal and Information Processing over Networks, vol. 1, no. 2, pp. 89–103, June 2015. [8] Y. Yu, J. Zhang, and K. B. Letaief, “Joint subcarrier and CPU time allocation for mobile edge computing,” in Proc. of the IEEE Globecom, Dec. 2016, pp. 1–6.
以上方法被设计用于最小化通用计算任务的计算时间 和/或 能耗。而本文方法针对最大化训练ML模型的效率。本文工作开始假设了一个不同的场景,即每个移动客户端在执行ML任务时都有数据和计算资源来保护客户端数据隐私。 这些不同点激发了我们提出一个新的定制的MEC协议和算法。
本文与其他已有方法的不同点在于考虑了客户端的异质计算与通信 和/或 数据资源。 模型压缩技术的使用能帮助提升本文协议的整体效率。
Assumption
我们假设每个客户端在考虑其信道状态的同时,适当地确定了无线电通信的调制和编码方案,使得包丢失率可以忽略不计。这导致每个客户端上载模型参数的吞吐量不同,尽管分配RBs(RBs:在LTE中定义的带宽资源的最小单位)的数量是恒定的。假设BS广播和组播传输的吞吐量为受最坏信道条件下客户端的吞吐量限制。尽管如此,我们仍然假设每个客户端的通道状态和吞吐量如上所述是稳定的。
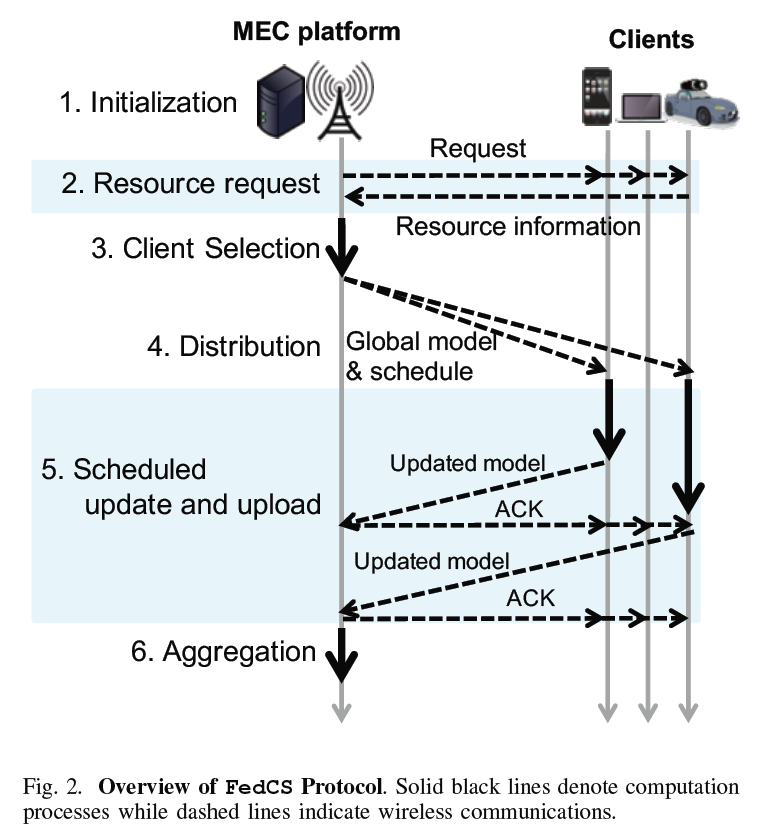
FedCS Protocol

The key idea of FedCS:采用two-step client selection。
- step1:Resource Request,即 要求随机客户端通知MEC操作员他们的资源信息 如无限通道状态、计算能力、与当前训练任务相关的数据资源的大小
- step2:Client Selection,评估Distribution和Scheduled Update and Upload所需时间并确定哪个客户端执行这些步骤


Client Selection的目标为最大化选择客户端的数量,即 $max_S|S|$.
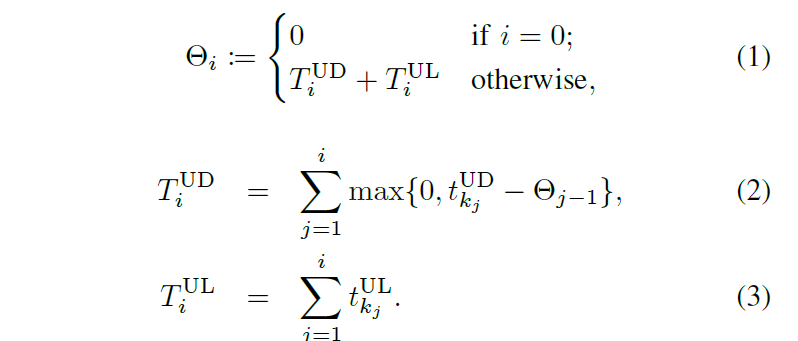
$T_{i}^{UL}$ 表示客户端upload模型更新时间的总和,$t_{k_j}^{UL}$表示第$k_j$个客户端upload模型更新的时间,当i != 0时,$\theta _i$ 表示update与upload model 过程的总时间。

Client Selection最大化|S|的形式化表示如下:
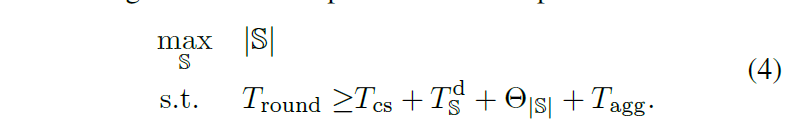
Optimization strategies
为了解决最大化问题,针对背包约束的最大化问题,提出基于贪心算法的启发式算法。
如上图Algorithm 3,step 3, 4, 9迭代加入模型上传与更新消耗最少时间的客户端 直至时间t达到**设定的deadline $T_{round}$** (step 5, 6, 7, 8)。该算法的复杂度为 $O(|K^{'}||S|)$
Selection of $T_{round}$
如果选取一个大的$T_{round}$, 则我们期望更多的客户端参与到每一轮模型更新与上传。然而,直到deadline时,这同时会减少更新聚合的可能次数(更多客户端消耗时间在上传更新模型上了)。 因此,在实验评估部分通过不同的 $T_{round}$选取展示对训练模型的最终表现的影响。
Experiment
Simulated Environment
基于假设部分,假设FL processes在网络条件稳定以及客户端设备可能在午夜或清晨未使用或stationary条件下进行。因此,本文作者将平均吞吐量视作稳定的。然而,考虑在Scheduled Update and Upload实践过程中可能短期吞吐量的小幅度变化,每次当客户端上传模型时,我们从高斯分布中采样吞吐量,其平均值和标准差分别由平均吞吐量和它的r%值给出。
$D_m$ 为全局模型的数据大小,upload模型所需时间可计算得 $t_{k}^{UL}=D_m / \theta_k$。model distribution所需时间建模为 $T_S^d = D_m / min_{k\in S}{\theta _k}$。另外,假设服务器得计算能力足够强 以忽略Client Selection and Aggregation的时间,即$T_{cs}=0, T_{agg}=0$。
Experimental Setup of ML Tasks
数据集:CIFAR-10,MNIST
对于两个任务,训练数据集分配给K=1000个客户端:首先,随机在100-1000中决定所属每个客户端的图像数据数目;然后将训练数据集划分为两个部分:1)idd setting,2)non-idd setting,划分方式为在统一数据集或多种不同数据集中随机选取样本图像数据;FL protocol的每一轮中,设置C=0.1以选择基于【FedAvg论文】中 $K \times C = 100$客户端K的最大值;最后测试数据集仅用于衡量分类的表现。
Global Models and Their Updates
【FedAvg论文】
Results and discussions
Details

IID setting
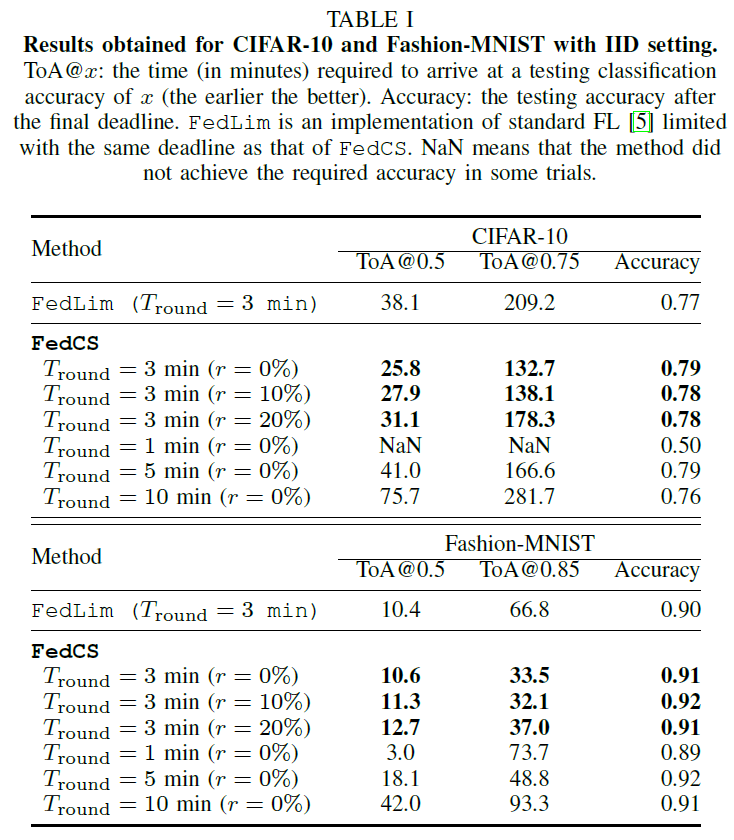
达到相同的精度(在设定时间内)FedCS的表现比FedLim更好,并且最终FedCS能达到的精度也比FedLim高。==» FedCS就训练过程能够提升效率。其中原因有:FedCS能够在每一轮训练中incorporate更多的客户端。
CIFAR-10和Fashion-MNIST当前的最好准确率分为为0.9769何0.967,而本文模型架构的选择充分表明此新的protocol能够在资源受限的设置下提升训练效率而不是达到最好的准确率。原始的FL【即FedAvg算法】没有deadline限制能够达到的最高准确率与FedCS的差不多。 因此,本文证实了用r参数化的吞吐量和计算能力的不确定性对FedCS的性能影响不大。
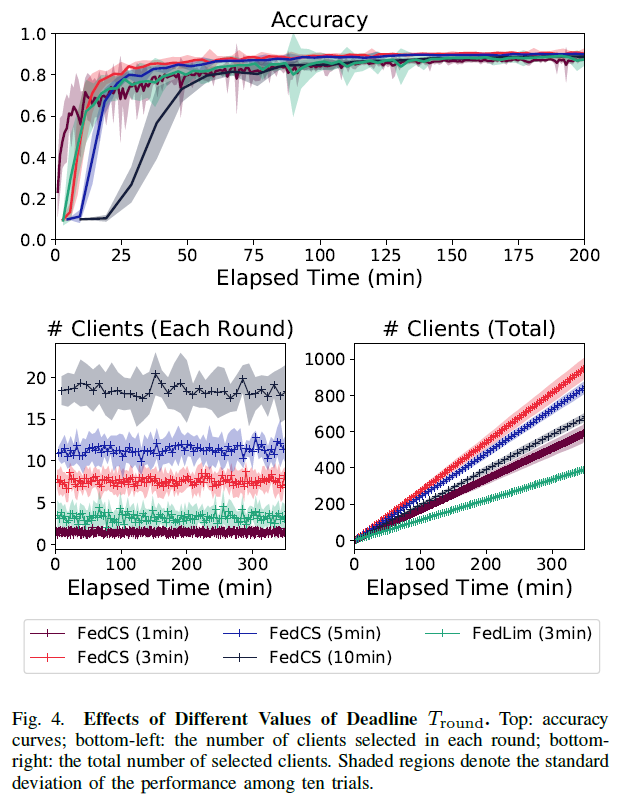
$T_{round}$的影响:由上图可知,$T_{round}$ 的选择不能太长也不能太短。
较长的deadline(如10mins)FedCS在每一轮训练中涉及到大量客户端,它们的表现极度受限更少次数的Aggregation步骤;较端的deadline(如1min),它们的表现受限于每一轮客户端的获取(参与),这也会降低分类准确率。 未来的工作可以有一种更好地方法选择$T_{round}$来**动态**改变每一轮足够的客户端参与数量。
Non-IID setting
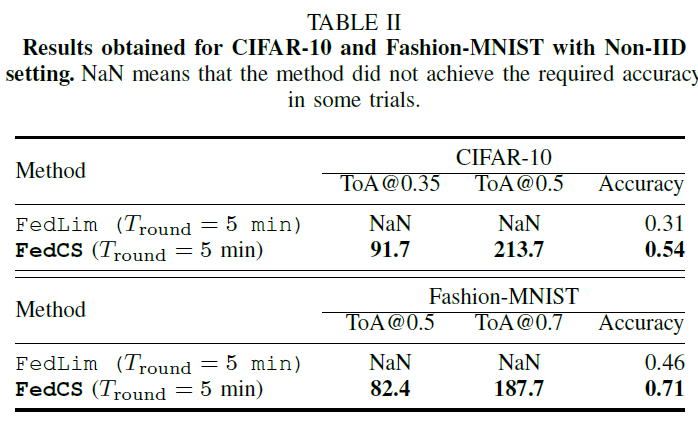

相比于iid setting,FedCS与FedAvg类似,都受限于Non-iid setting。能够缓解non-iid 问题的潜在扩展方法是使用model compression技术,在相同的 $T_{round}$限制下这能够增加被选择的客户端的数量(进而提升算法准确率)。
Conclusions
本文提出的FedCS,针对MEC框架下异质设备的FL效率提升。在本文的实验中分别将CIFAR-10、MNIST数据集划分为iid setting和non-iid setting,并将【FedAvg论文】中的算法做了小改动,即设定了deadline $T_{round}$;并做了对比实验,实验结论:FedCS能够在资源受限的条件下提升训练过程的效率,而不是最终的最佳准确率。对于non-iid setting,可使用model compression技术来间接提升算法准确率。
本文的关键思想在于 $T_{round}$的设定,未来工作的有趣方向在于处理更加动态的场景,其中资源的平均数量以及更新和上传所需的时间可以动态波动。
==»Model Compression + Deep Reinforcement Learning??? 大规模应用及效果如何?
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)