[PaperNotes]2020.DPLCF Differentially Private Local Collaborative Filtering

文章目录
[TOC]
文章地址:https://dl.acm.org/doi/abs/10.1145/3397271.3401053
作者:Chen Gao, Chao Huang, Dongsheng Lin, Depeng Jin, Yong Li
发表会议:SIGIR 2020
截止当前(2020.11.15)引用次数:1
写在前面
由于近期即将着手的内容与DP相关,碰巧关注到了今年的SIGIR有这样的一篇文章,因此来读下看看。目前就个人经验来看,RS上的隐私保护是一个可以继续跟的方向。
此份笔记目录依照原文,主要为个人关注以及一些值得进一步去研究的内容(不包含实验部分)。如有错误,欢迎拍砖交流~
如果对此方向感兴趣或者觉得不错的话,十分欢迎一起学习~
0. Abstract
大多现存的推荐系统利用用户完整的原始行为数据(从移动设备手机以及服务提供商储存然后投入到推荐模型中) ==» 因为推荐服务提供商的不可信可能导致隐私泄露的高风险。 尽管许多研究致力于隐私意识(privacy-aware)推荐,但是建立一个完全保护用户隐私的有效的推荐系统仍然未能解决。
本文作者 提出差分隐私协同过滤推荐的一种通用框架。
工作流分为以下三个步骤:
- 对于保存在用户设备中的累计行为日志记录,使用差分保护机制将真实互动(real interactions)混淆(即加噪声)后发送给服务器;
- 在收集到来自所有用户的所有混淆记录后,服务器在每一对items之间运行评估模型来计算相似度,在这一步不要求用户相关的数据,因此不会引入任何额外的隐私风险;
- 服务器将评估后用户不相关的物品相似度矩阵给每个用户设备,结合每个用户本地存储的原始行为数据在本地通过物品相似度的方法推断出推荐结果。
为了验证方法的有效性,本文在两个真实数据集中做了扩展实验,显示出提出的方法达到了最前沿方法的最好的表现。进一步地,该方法在多种隐私预算下都可以很有效。
1. Introduction
现存的隐私保护推荐工作将推荐端视作可信的并且只保护数据不被第三方攻击 ==» 这是不合理的,比如Fackbook数据泄露。
现存的两类解决方法:
- 基于数据保护机制, 即向原始用户数据中加噪声并将扰动数据发送给服务器;
- 去中心化矩阵分解,即通过潜在的表示或梯度进行通信,并通过多次参数更新,用户无需向外发送原始数据即可了解其嵌入内容
尽管上述方法的有效性,但本文作者提出仍然有三项主要限制:
- 无法处理隐式数据。对于去中心化矩阵分解方法,大多数研究的重点在于评分数据。但是,这些数据不是普遍的。举例,在当今的在线系统中普遍存在隐式行为数据,这些数据被广泛应用于训练推荐模型;
- 推荐结果中的隐私泄露。 在数据保护方法中,服务器端计算推荐结果并发送给用户设备。因为推荐结果是未来行为的估计,且与真是行为相似,这些估计行为可以用来推测敏感信息;
- 通信和计算成本高。去中心化方法中有频繁的数据转移和本地计算,这使得在真实应用中实用这些方法不是很实际。
总结关键挑战如下:
- 具有隐私保障的二进制数据保护机制;
- 从受保护的二进制数据学习是困难的;
- 以低计算机和通信费用做推荐。
本文工作主要贡献:
- 为隐式反馈提出一种差分隐私协同过滤的通用框架,在差分隐私机制下,隐私泄露受到严格保证。此外,这个框架仅依赖于交互数据并应用于各种推荐场景;
- 为从差分隐私保护的数据中提取物品相似度作为预测信号提出一种有效方法。然后将此信号与本地存储的原始数据结合做本地协同过滤推荐;
- 在两个真实世界数据集上存在高隐私泄露风险的典型推荐场景做扩展实验。实验结果显示提出的方法DPLCF在保护用户隐私时比最先进的方法表现更出色。进一步研究显示该方法在许多不同噪音级别下也能很好工作。
2. PRELIMINARIES
现存方法的问题及本文任务目标遵从的规则
现存的方法遵循这样的范式:收集所有的反馈并上传到服务器,然后部署model-based或者memory-based CF在服务器上做推荐。本文作者认为这是不合理的,因为服务提供者是不可靠的。
因此,对于隐式反馈的隐私保护协同过滤问题要求用户的真实数据仅存储在用户的个人设备上。进一步,推荐结果一定程度上反映了用户未来的行为,因此推荐过程(generating results)也只能在用户端执行。最后,诸如挖掘以及提取CF signal等大量的计算必须只集中在服务器执行,因为用户端的计算资源是极其受限的,并且在服务器与客户端的分布式计算具有很高的通信要求。
总之,本文任务目标是 获取模型来评估用户u与物品i互动的可能性,且遵从以下规则:
- 规则1:用户的真实历史互动数据只能存储在用户设备本地;
- 规则2:在差分隐私保证下用户上传的数据应被保护;
- 规则3:用户的推荐结果只能在用户设备本地推理。
3. SYSTEM OVERVIEW AND METHOD
3.1 System Overview
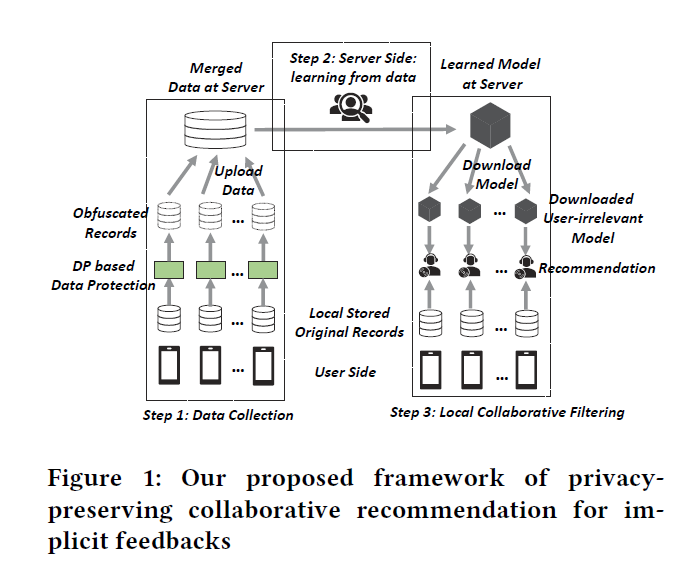
在本文提出的框架中,整合了两种主流隐b私保护方法的优势,即 数据保护[25,30] 和 去中心化推荐[20,21,27,41]。
分为三个步骤:
-
Data Collection:使用随机扰动作为数据保护机制。
Take user u as an example, we apply a random function f on each user’s historical behaviors $y_u = {j|y_{uj}=1}$ to obtain obfuscated images $\hat y_u=f(y_u)$ . 使用差分隐私确保隐私被保护
- Input:原始用户物品历史行为 $y_u$
- Output:混淆的用户物品历史行为 $\hat y_u$
-
Data Expoitation:服务器从每个用户处收集混淆互动数据并合并成混淆互动矩阵 $\hat R^2$。利用收集的矩阵我们开发一中有效的评估模型来利用噪声数据并提取有效的predictive signals。总之,这一步,我们获得能够用于生成推荐结果的模型参数。
-
Input:混淆的用户物品互动矩阵 $\hat R$
-
Output:推荐模型的参数
-
Recommendation:如上所述,一定程度上,推荐结果是对于用户未来行为的估计。因此,我们摈弃了传统方式 即服务器集中生成推荐结果,并且发送学习的模型参数给每个用户。然后每个用户的设备使用本地存储的原始行为数据作为推荐模型的输入,进一步的获得每个候选物品的预测分值。
- Input:一个推荐模型的参数 以及 原始用户物品的历史行为 $y_u$
- Output:对每个用户生成的推荐结果集 RecList(u)
3.2 The Proposed Method
在这个通用框架中,提出的方法成为DPLCF(Differentially Private Local Collaborative Filtering), 由三个阶段组成,即
(1)混淆报告上传(obfuscated reports uploading);(2)基于物品的邻域查找(item-based neighborhood finding);(3)本地推荐计算(local recommendation computing)
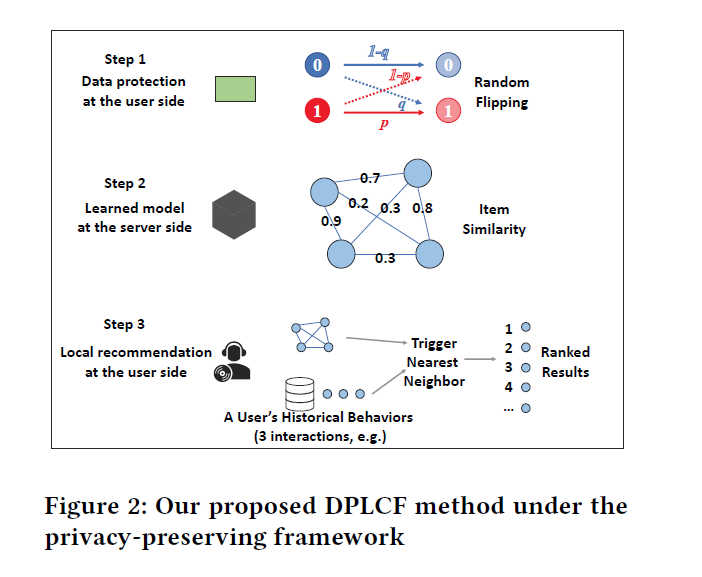
Obfuscated Reports Uploading(Client Side)
在传统推荐设置中,用户的设备不经任何处理上传用户的真实行为。 这里我们使用混淆的行为数据代替上传。
为了保护离散行为数据,采用基于差分隐私保证的一种随机位翻转(random bit flipping)技术。

Item-based Neighborhood Finding(Server Side)
使用每个用户报告的混淆历史行为,这些噪声向量能在服务器合并成一个噪声互动矩阵。
传统的隐因子模型,如概率矩阵分解[24], 贝叶斯个性化排序[33], 或 神经矩阵分解[19], 以隐空间方式使用向量表征每个用户的兴趣。
然而,对于每个数据样本来说用户向量的学习的高度敏感的。 因为在服务器上收集的矩阵经过随机翻转的处理,有大量的假阴性(false negative)或假阳性(false postitive)样本会很大程度上恶化隐因子模型的学习过程。另一方面,在用户端接收到服务端的用户嵌入(user embedding)后本地存储的用户向量无法进一步利用。总之,对于隐式数据传统的因子模型无法解决在混淆的二进制互动矩阵学习过程的挑战。
本文作者从另一视角提出解决方法,因为是在每个用户设备本地做的推荐,那么利用基于物品的协同过滤方法充当服务端的模型。更具体地,基于物品的协同过滤模型的重要部分是 获取每个物品对的相似度分值,然后每个物品相似度可以结合用户历史来生成推荐列表(历史互动物品可以充当item-to-item trigger)。 我们提出基于评估的方法来尽可能地提取有用地相似性信号(similarity signals)。
Jaccard simmilarity between item i and j:

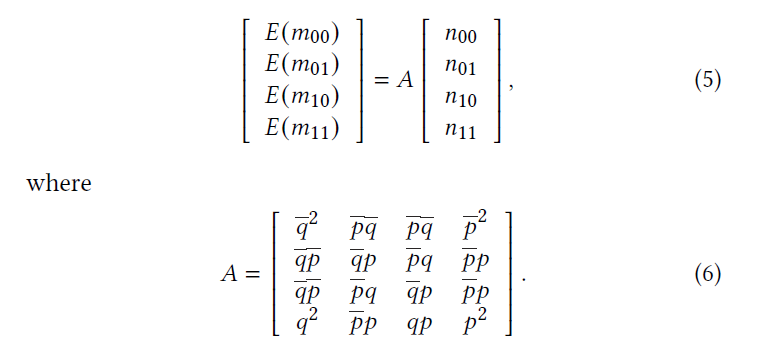
其中$V_i = R_{[:,i]}$ ,即真实互动矩阵的第i列;$n_{ij}$ 表示位置s的数量($\hat V_1[s] = i, \hat V_2[s] = j$),$\hat V$ 是原始位向量 V 经过随机翻转机制后得到的。$m_{ij}$ 表示对应的混淆记录 $\hat V_1, \hat V_2$ 。
集合并与交的技术可以用公式(5) 使用mean-field model估计。
取矩阵的逆,可得到$n_{ij}$ 的无偏估计,如下

第二步的计算部分还有些不太懂,明白后再加上。或者请大佬指教一二,谢谢
Local Recommendation Computing
通过第二阶段中计算物物相似度矩阵后,在第三部中,可以在本地计算处推荐结果来保护隐私。(每个用户的真实互动历史存储在用户设备中,并且接收物物相似度矩阵。)
对于物品j,使用KNN(j)计算出相似度(sim(j, .))最高的邻近物品数量。候选i的分数导出为领域内交互记录的加权和,如下:
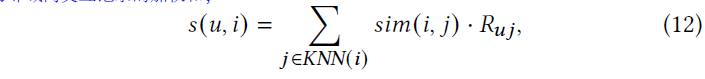
sim(i,j) 表示物品i和j的相似度度量。在本文中使用Jaccard similarity,在第二阶段的评估模型可以直接利用。
Complexity Analysis
对用户端,本地设备在步骤1和3中涉及到。对于第一步,数据保护的计算复杂度和通信费用是与每个用户的互动数量成线性关系的;对于第三步,计算复杂度是 O(log(N) * number_of_neighbour)。服务端在步骤2中涉及,在这一步中,计算复杂度为O(|R|),与所有的互动数量成线性关系。
对于去中心化算法,因为高时延会导致差的用户体验和算法的低表现,所以跨客户端 或 在客户端与服务器之间的通信效率 是 一个主要关注点。 在本文作者提出的解决方法中,在整个推荐中有一个上传和下载过程,这是比一些现存的需要多次数据或模型更新的去中心化方法更有效率的。 本地设备的计算消耗是另一个关注点,因为用户设备的计算能力通常是受限的。 本文作者表示提出的DPLCF中,这些关键的限制被良好的解决了。
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)