[PaperNotes]2020.A Systematic Literature Review on Federated Machine Learning: From A Software Engineering

文章目录
A Systematic Literature Review on Federated Machine Learning: From A Software Engineering Perspective
文献链接:https://arxiv.org/pdf/2007.11354.pdf
作者:Sin Kit Lo, Qinghua Lu, Chen Wang, Hye-Young Paik, Liming Zhu
发表:arXiv
截止当前(2020.12.17)被引次数:3
Zotero链接: 从我的文库打开
| 标签1 | 标签2 | 标签3 | 标签4 |
|---|---|---|---|
| Federated Learning | Software Engineering | Review |
[toc]
Conclusions
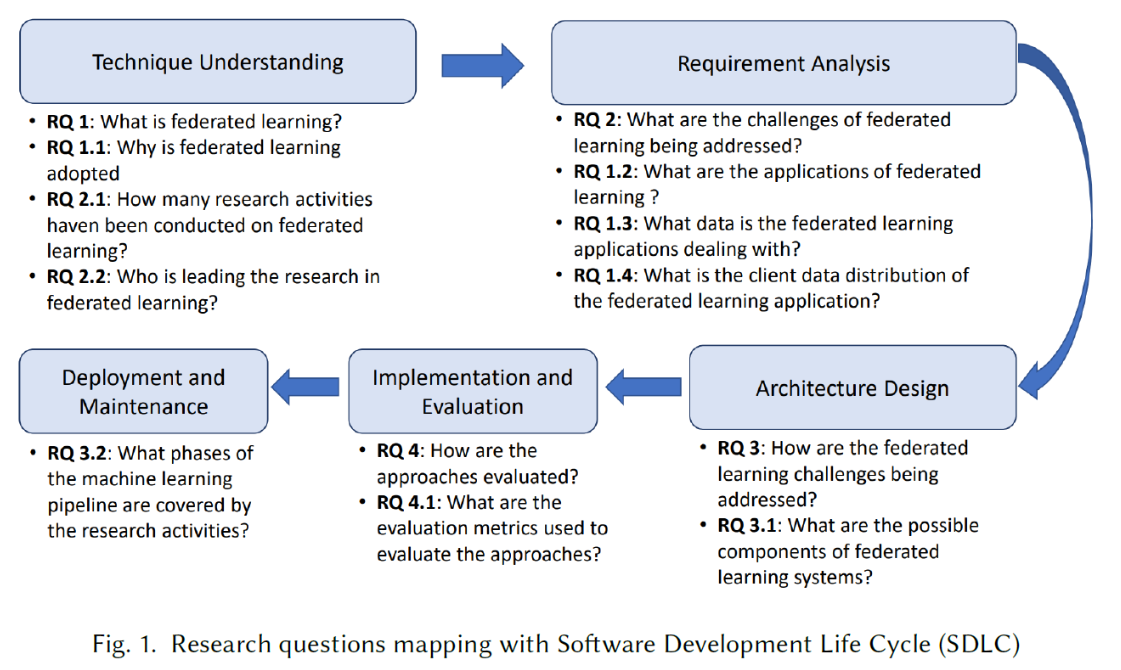
本文主要从软件工程角度来对Federated Machine Learning做了一个review,详细说明了其文献搜集及选取过程并有对应的参考文献【82】。其中,为了严谨采用了交叉验证。本文方法论为 技术理解 => 需求分析 => 架构设计 => 实现和评估 => 部署和maintenance,每个步骤下提出研究问题,主要通过231篇论文研究解答此问题。对FL领域研究可以有较为系统的了解,进一步的,可以通过其参考文献以及现存的技术方案对FL有更加深入的了解。 对本文做一个较为系统的梳理可以加深对FL全局的把握理解(涉及FL概念、应用、FL应用的数据形式-【图片、结构化、文字】、为何应用FL、FL面临的挑战以及对应的现存(指出尚缺少的)解决方法、已经做了多少研究、领先的研究单位、FL systems的主要成分、machine learning pipline phase各阶段研究数量情况、如何评估FL方法、开放性问题和未来研究、相关工作【7 surveys, 1 review】),展开下一步研究。另本文也是撰写综述论文的一个实例。
Abstract
Thus, the goal of this paper is to conduct a systematic literature review to provide an up-to-date holistic and comprehensive view of the state-of-the-art of federated learning research, especially from the software engineering perspective.
Contributions
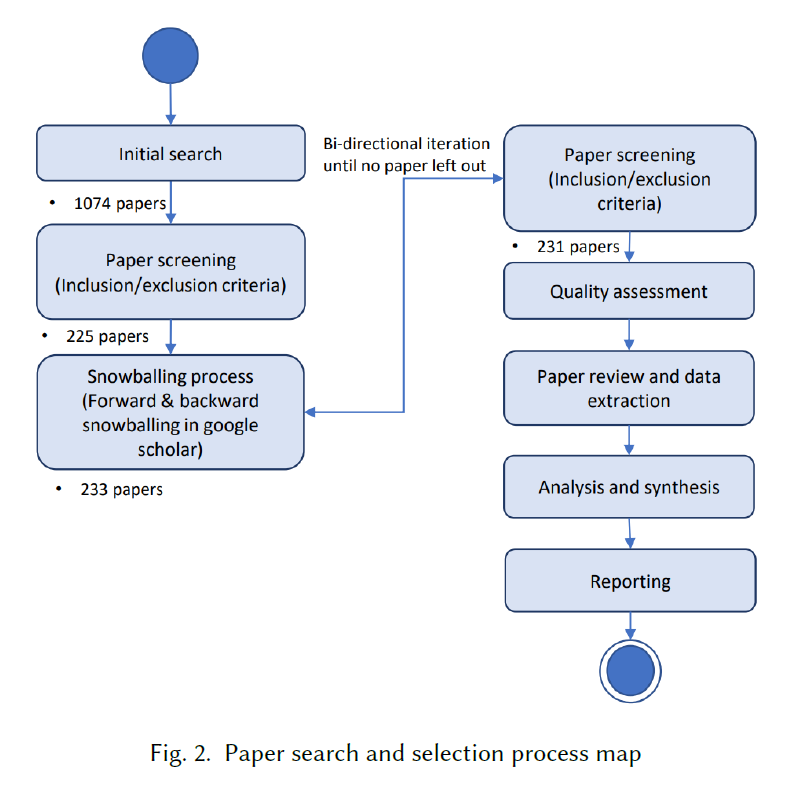
- identify a set of 231 primary studies related to federated learning published from 2016 to 2020 following the systematic literature review guideline.The community can use these studies as a starting point to conduct further investigation into federated learning
- present a comprehensive qualitative and quantitative synthesis reflecting the state-ofthe-art in federated learning with data extracted from the 231 studies.Our data synthesis covers the software engineering aspects of federated learning system development.
- We provide findings from the results and identify future trends to support further research in federated learning.
Methodology
Search terms
Key terms:Federated Learning,
Supplementary terms:Federated Machine Learning, Federated ML, Federated Artificial Intelligence, Federated AI, Federated Intelligence, Federated Training
Inclusion and Exclusion Criteria
这篇文献综述的重点是在联邦学习系统的软件工程视角。因此形成纳入和排除标准来有效选择相关论文。在完成标准的初稿后,使用最开始的20篇文献做初步研究。然后两个独立研究者交叉验证这些被其他研究者选择的论文并重新定制了标准。当两个研究者之间有分歧时,就会咨询第三个研究者。
Research Question,Results and discussions
RQ1. What is federated learning?

FL应用于mobile edge network中仍然存在的挑战:
-
模型更新(如DNN中的百万级参数)的高维度和参与移动设备的通信带宽
-
大的且负责的移动边缘网络中,就参与设备的数据质量、计算力、参与感(愿意参与)指标,由于这些异质性需要做很好的资源配置;
-
当恶意参与者或聚合服务器出现时,FL不保证隐私
-
Finding from RQ 1: What is federated learning (FL)?
Decentralised learning: There is a concern about the usage of a single central server for federated learning orchestration which could cause a single point of failure. Decentralised approaches (i.e., adoption of blockchain) for the exchange of model updates are studied. Cross-silo: Although federated learning was initially raised with an emphasis on cross-device scenarios, interests have been extended to cross-silo federated learning, where data sharing between organisations is restricted due to data privacy legislation and rules. Federated transfer learning: Apart from sample-based (horizontal) federated learning and feature-based (vertical) federated learning, federated transfer learning is also considered as a type of federated learning, which leverages transfer learning to provide solutions for the scenarios where there is a relatively small overlap in both sample and feature space.
-
Finding from RQ 1.1: Why is federated learning adopted? Motivation for adoption: Data privacy and communication efficiency are the two main motivations. Only a small number of studies adopt federated learning because of model performance. With large amounts of participating clients, federated learning is expected to achieve high model performance. However, the approach is still immature when dealing with non-IID and unbalanced data distribution.
-
Finding from RQ 1.2: What are the applications of federated learning? & RQ 1.3: What data is the federated learning applications dealing with? Applications and data: Federated learning is widely adopted in applications that deal with image data, structured data, and text data. More studies are needed for IoT time-series data. Both graph data and sequential data are not popularly used due to their data characteristics (e.g., non-linear data structure). Also, there is only a few production-level application. Most of the applications are still proof-of-concept prototypes or simulated examples.
-
Finding from RQ 1.4: What is the client data distribution of the federated learning applications? Client data distribution: Client data distribution is important to the model performance of federated learning. Model aggregation should consider the case when the distribution of the dataset on each client is different. Many studies work on Non-IID issues in federated learning, particularly on extensions of the FedAvg algorithm for model aggregation.
-
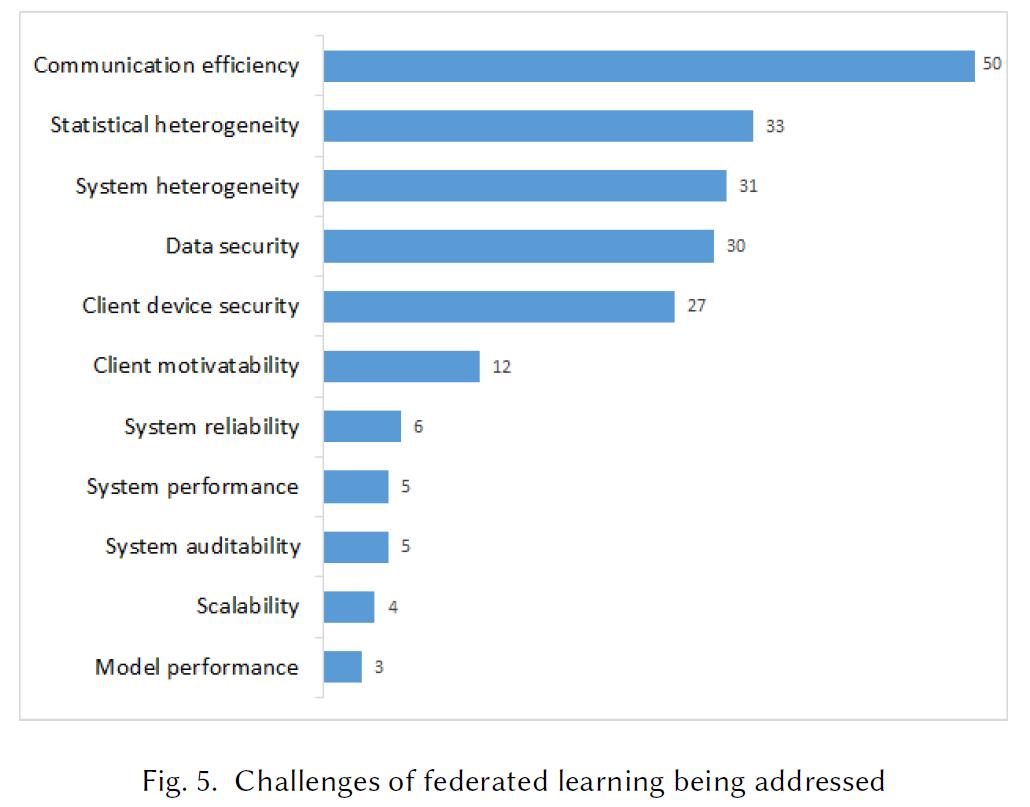
Finding from RQ 2: What are the challenges of federated learning being addressed? Motivation vs. challenges: Most of the known motivations of federated learning also appear to be the most studied federated learning limitations, including data privacy, communication efficiency, system and statistical heterogeneity, model performance, and scalability. This reflects that federated learning is still an under-explored approach.
RQ2.What are the challenges of federated learning being addressed? & RQ 2.1: How many research activities have been conducted on federated learning?
Motivation vs. challenges:FL大多已知的motivation包括communication efficiency, statistical heterogeneity, system heterogenetiy, data security, Client device security, Client motivatability, system reliability, system performance, system auditability, scalability, model performance. 这反映了FL仍然是正在探索的方法。
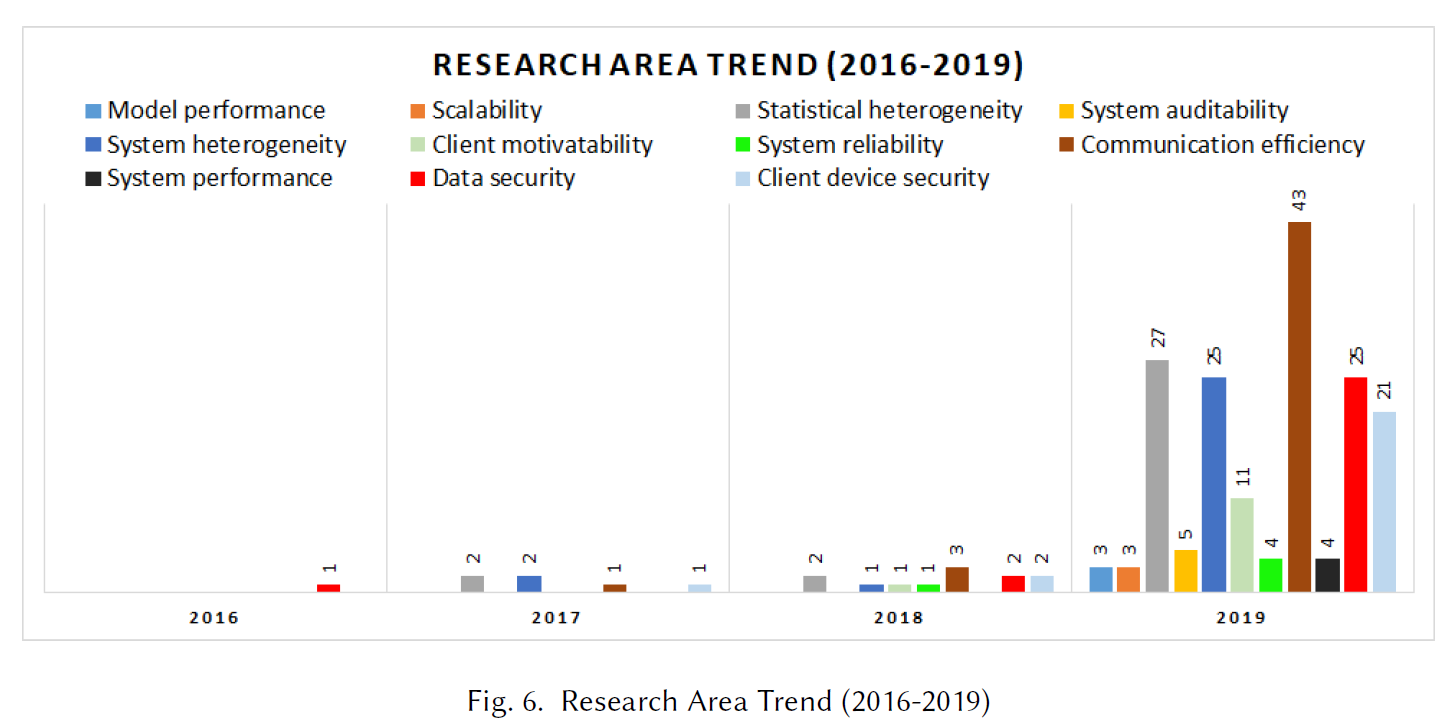
论文分类:
- evaluation research – 软件工程实践中一个问题的探讨,研究成果对现象之间的因果关系有了新认识
- philosophy paper – 提出了看待事物的新方法的论文,例如:一个新的概念框架,由概念框架的原创性,提案的合理性,以及框架是否有深刻见解来评估
- proposal of solution – 这类论文提出解决方案的技术,并争论其相关性,但没有一个全面的验证。其中技术必须是新颖的且对现存技术有重大改进提升
- validation research – 验证研究调查提出的解决方案尚未在实践中实现的特性。调查使用了一个彻底的,方法上合理的研究步骤。
研究分类结果如下表:
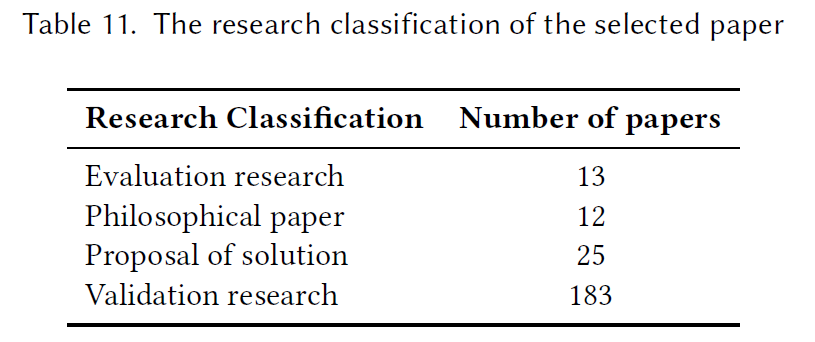
进行的最多的研究是validation researches, 其次是proposal of solution, evaluation research, philosophical paper.
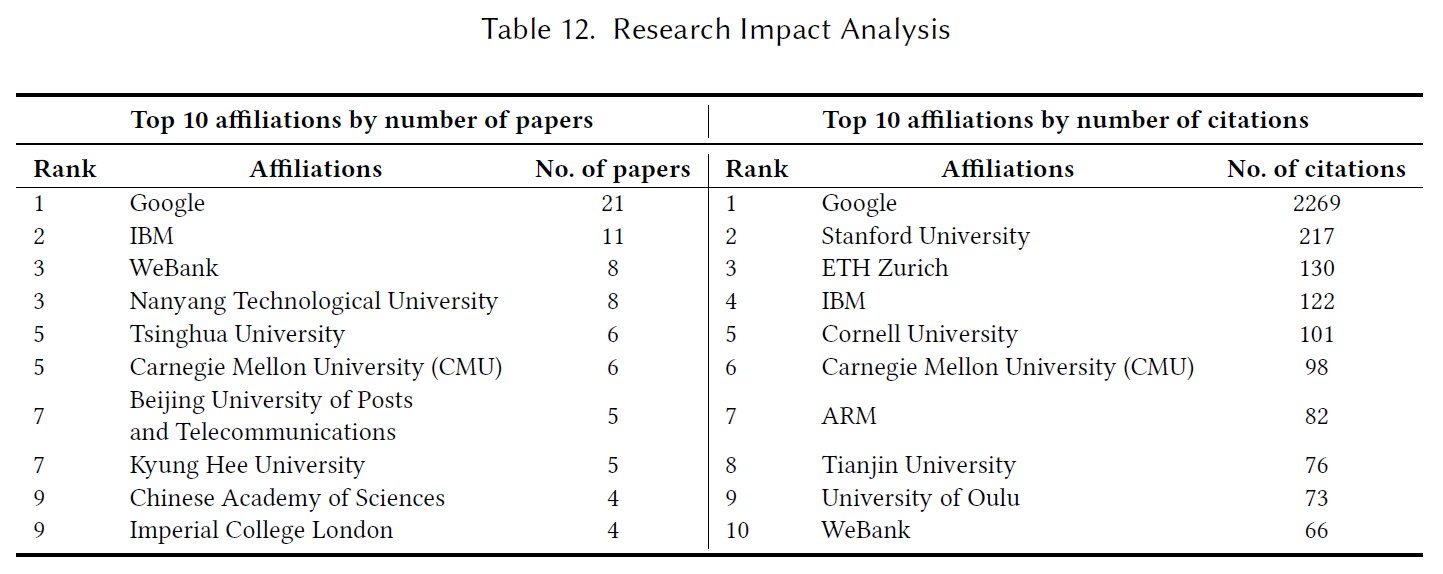
RQ2.2.Who is leading the research in federated learning?
Finding
论文数量以及引用量都排在前十的单位是Google,IBM,CMU,WeBank。
RQ3. How are the federated learning challenges being addressed?
应对FL挑战的现存方法:

从上图可知,Top 5 proposed approaches:model aggregation, training management, incentive mechanisms, privacy-preserving, resource management. 这些方法主要是为了解决communication efficiency, statistical and system heterogeneity, client motivatability, data privacy的问题。
表13中列出了应对联邦学习挑战的方法。注意:并没有涵盖收集的研究中提到的每一个挑战,而是只涵盖那些提出了解决方案的挑战。

RQ 3.1: What are the possible components of federated learning systems?
RQ3.1的动机是identify联邦学习系统中的组成部分及其职责。
本文中FL systems被划分为两类:1)central server;2)client devices。这两个组件皆是传统FL systems的基础,其中central server启动和orchestrate训练过程,而client devices执行实际的模型训练。
-
central server:形式多样,如 托管在local machine, the cloud, MEC platforms, edge gateways, base stations. 大多研究提出Central server在将模型分发到参与客户端之前通过随机初始化模型参数或梯度来创建第一个全局模型【27,56,89,114,115,199】;此外,Central Server有时对全局模型做预训练——使用self-generated sample dataset或者从每个client device手机的少量数据。 注意:在decentralised FL systems【14,111,144】中,是client device初始化全局模型。
在全局模型初始化后,central servers将广播全局模型(包括模型参数和梯度)给参与client devices(可能是所有参与的客户端设备或只是特定客户端设备或者随机 或者 基于模型训练表现以及通信和计算资源可用性)。 相似地,客户端训练后的模型收集后传回central server。模型的收集方式可以是同步的或者是异步的。最后,当中央服务器接收到全部或一定数量的更新时,它执行模型聚合,然后将更新后的全局模型重新分配到客户端设备。
除了orchestrate模型参数和梯度交换之外,central server还托管了其他的基本功能,如encryption/decryption mechanisms, resource management mechanism, evaluation framework, client and model selector, feature fusion mechanism, incentive mechanisms, anomaly detector, model compressor, communication coordinator, auditing mechanisms。
-
Client devices:负责使用本地可用数据集进行模型训练的组件。首先,接受来自central server用于sever-initialised model training setting 的初始化全局模型,然后在本地进行模型训练。 本地模型训练目标为:最小化损失函数和优化本地模型表现。在将模型更新传回server前,会进行多轮及多回合的训练过程。为了减少通信轮数,【52】提出multiple local minibatch of data上进行本地训练,在达到baseline表现后只与central server 通信一次。
其中,为了保护数据安全以及防止信息泄露,client devices的训练结果应该在上传到central server之前进行加密处理;为了减少通信费用,在上传到central server之前应该对模型或训练结果进行压缩。在某些场景中,只有被选择的client devices要求上传训练结果到server,这取决于central server设置的selection criteria。criteria包括客户端设备的可用资源和模型表现。除此之外,客户端设备还托管加密/解密机制、数据增强机制[69,156],以及与同一个FL系统中的中央服务器相关的特征融合机制。完成一轮模型训练后,将训练结果上传到中心服务器进行全局聚合。
在decentralised FL systems中,被移除的中心服务器主要被一个区块链作为模型和信息来源的组件所取代。区块链负责激励机制和差异私有多方数据模型共享。 没有了central server,初始模型可以由每个client device使用本地数据集在本地创建,然后通过 基于共识的方法更新模型,这使得设备能够发送模型更新以及从邻居结点接受梯度。client devies的通信是通过P2P网络实现的。每台设备有所有client devices的模型更新副本。达到共识后,所有的client devices使用新的梯度进行模型训练。
其中cross-device setting和cross-silo setting之间的client’s nature有不同点。主要是因为两者的数据异质性。
一些研究也加入edge devices到系统中作为作为central server和client devices的中间层。引入边缘设备通过减少训练数据样本大小来提高通信效率和更新速度。
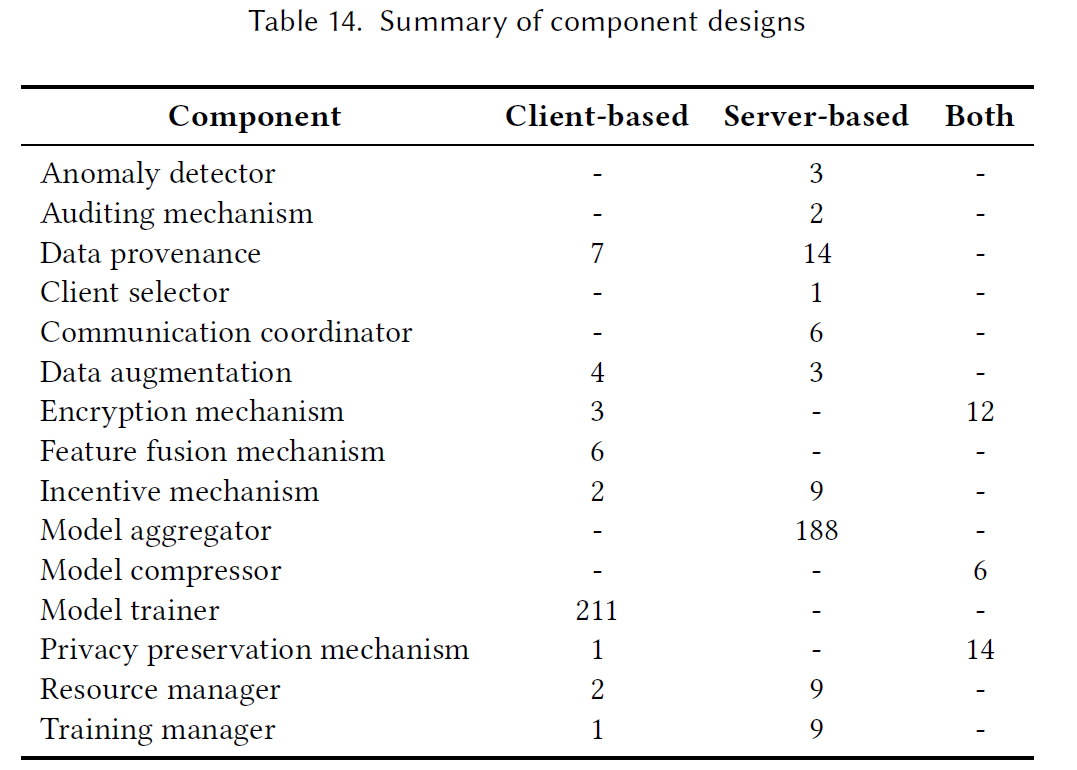
Finding
- Basic components on clients: data collection, data preprocessing, feature engineering, model training, and inference.
- Basic components on central server: model aggregation, evaluation.
- Advanced components on clients: anomaly detection, model compression, auditing mechanisms, data augmentation, feature fusion/selection, security protection, privacy preservation, data provernance.
- Advanced components on central server: advanced model aggregation, training management, incentive mechanism, resource management, communication coordination.
RQ 3.2: What phases of the machine learning pipeline are covered by the research activities?

Finding
讨论最多的阶段是model training. 少量研究涉及到 数据预处理,特征工程和模型评估。现存的研究中没有讨论Model deployment (e.g., deployment strategies), model monitoring (e.g., dealing with performance degradation), and project management (e.g., model versioning)。production-level federated learning systems的开发需要更多研究。
RQ 4: How are the approaches evaluated?

Finding
评估:研究者大多在隐私敏感场景下通过模拟来评估FL方法。只有少量现实案例研究,比如,Google的移动键盘预测。
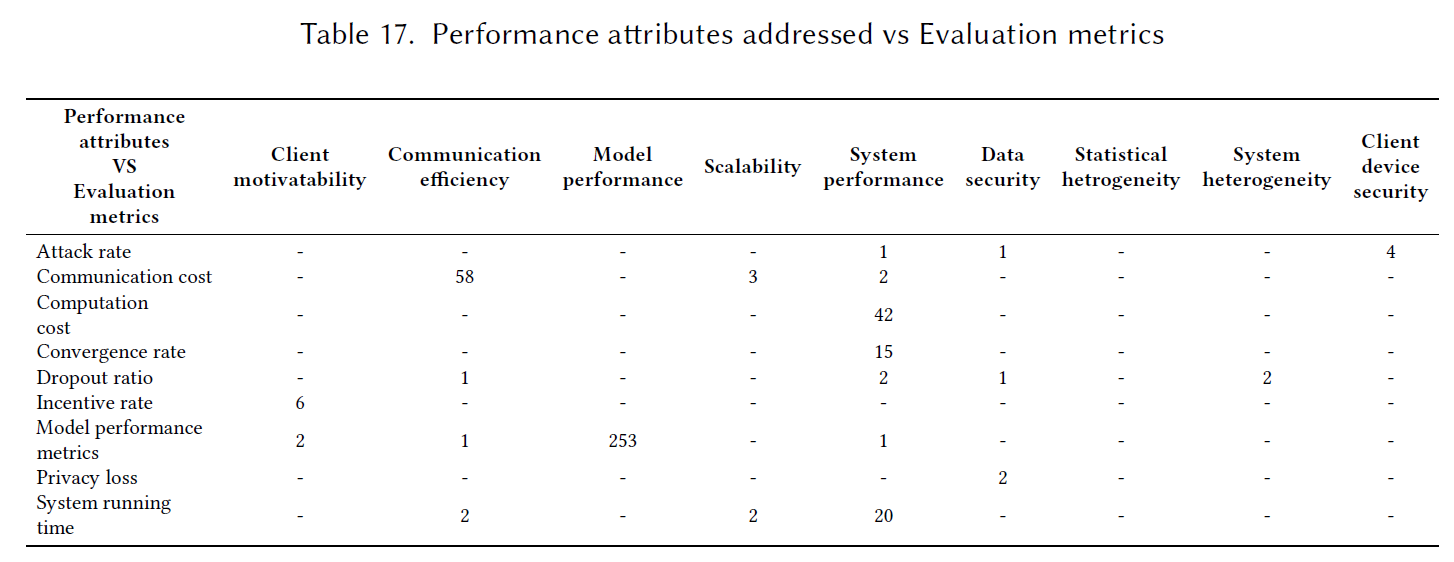
RQ 4.1: What are the evaluation metrics used to evaluate the approaches?
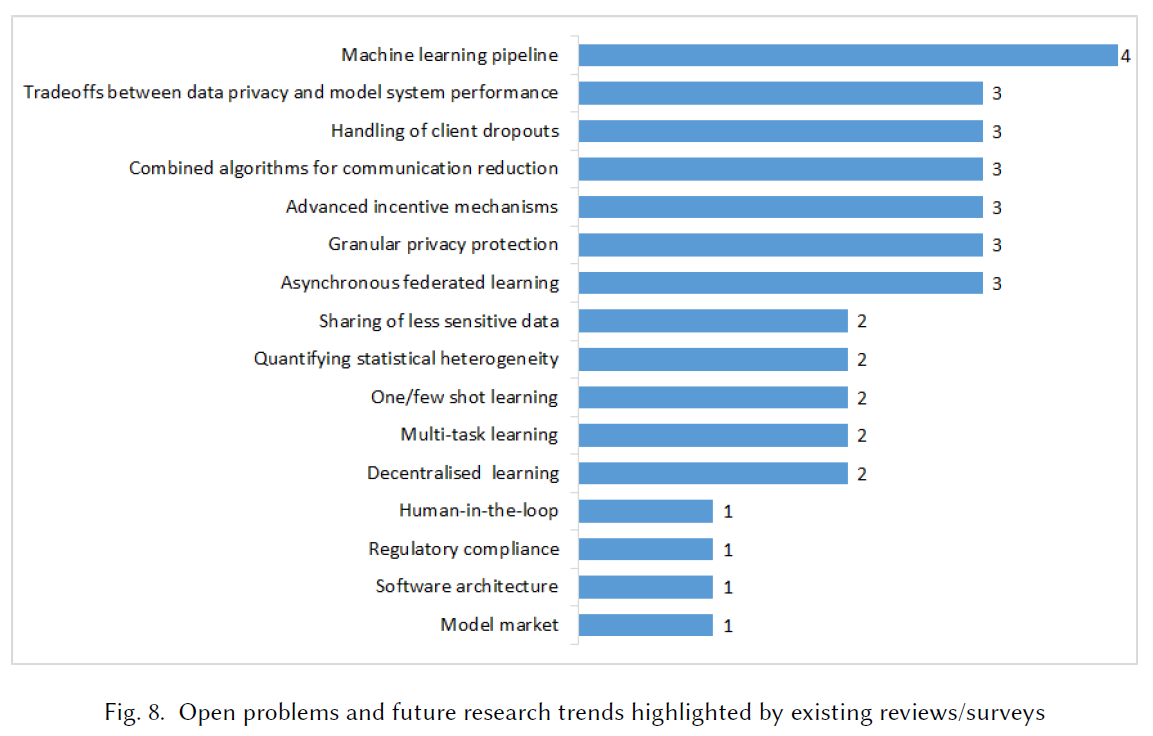
Open problems and future trends
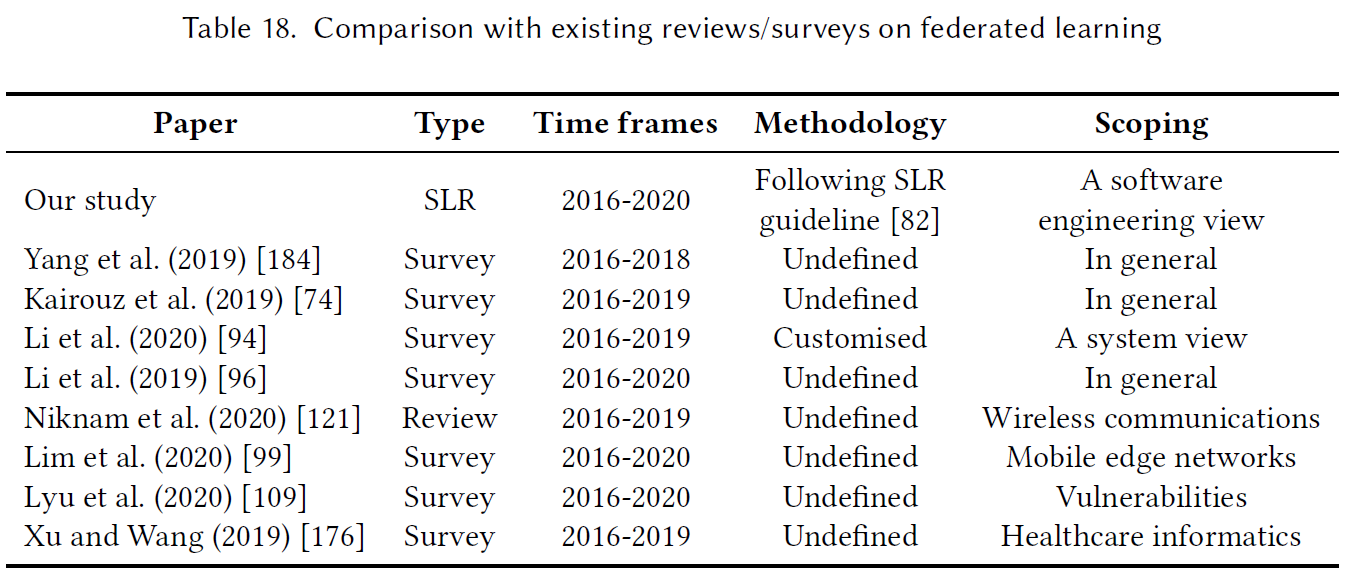
Related work
7 surveys and 1 review that cover the federated learning topic (2016-2020)
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)