[MIT 6.824]GFS

文章目录
分布式存储 why hard?
- high performance ==» shard data across servers 服务器分片存储
- many servers ==» constant faults 一致性错误
- fault tolerance ==» 经典方法:replication
- replication ==» potential inconsistencies
- better consistency ==» low performance
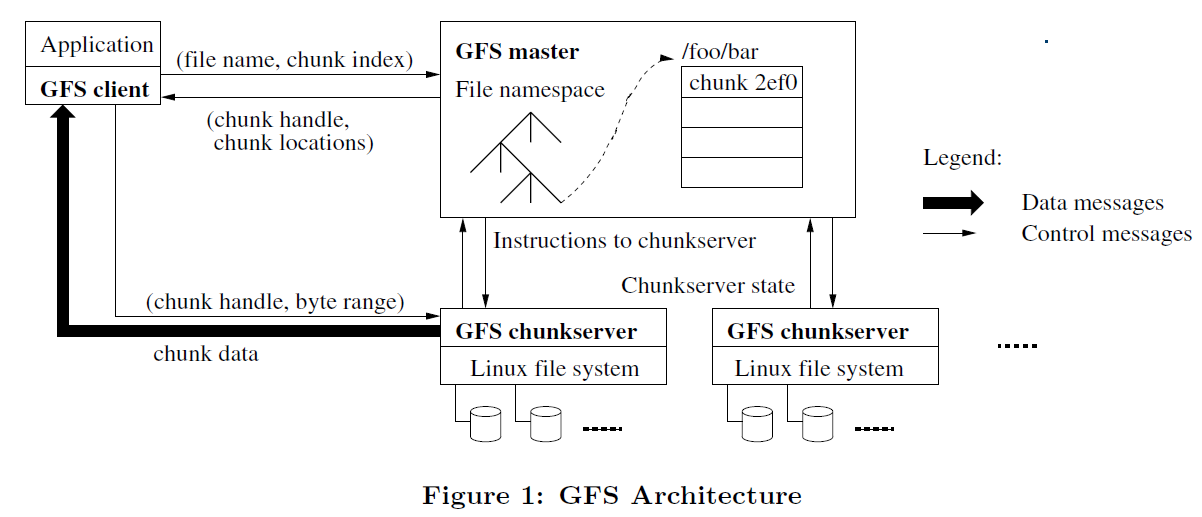
GFS架构
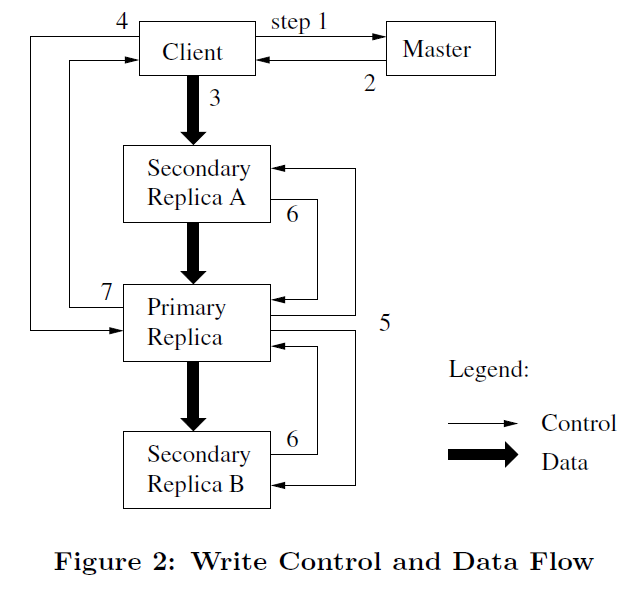
gfs写入控制与数据流
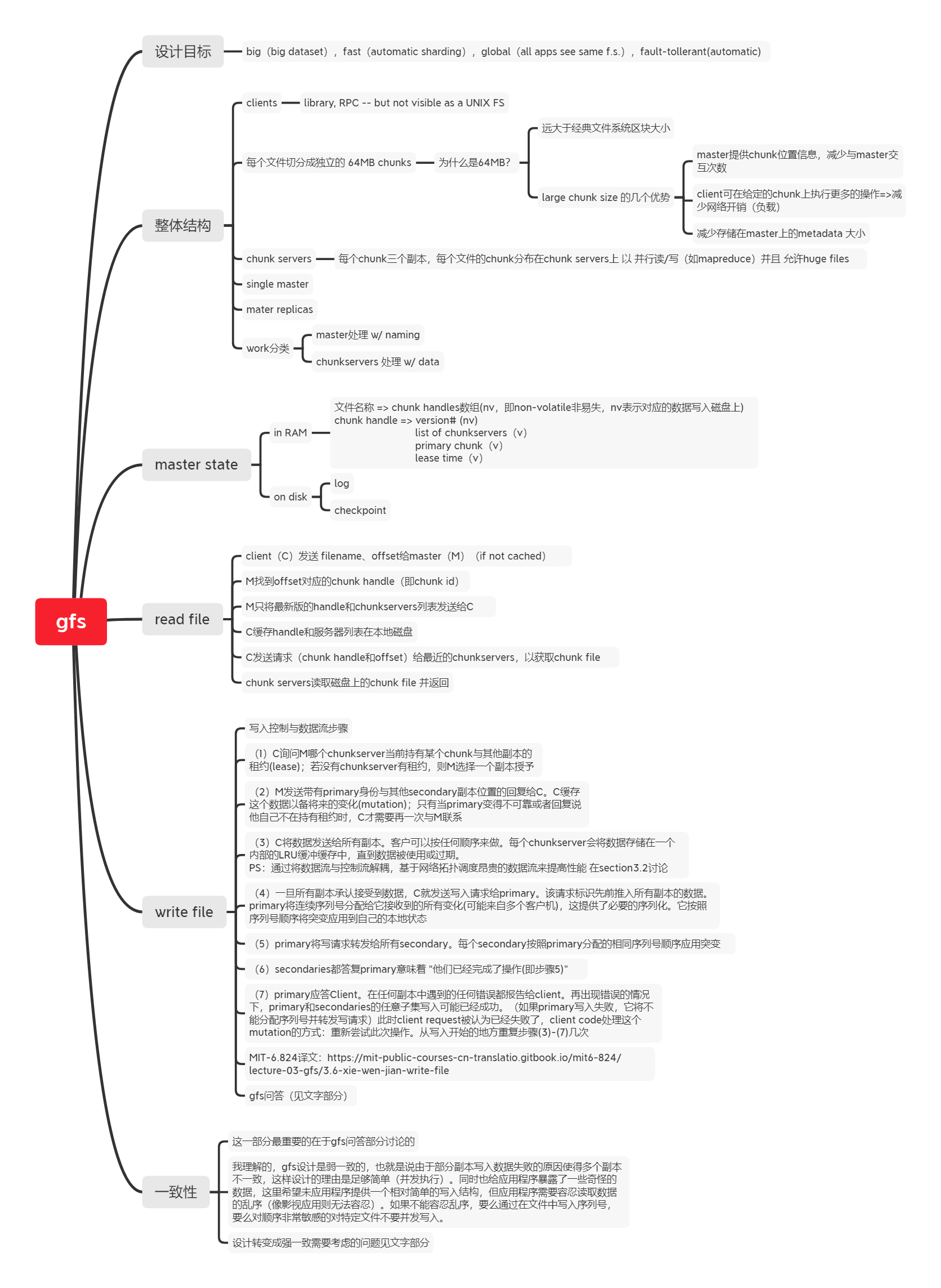
gfs-paper核心
重要问题
关于gfs写文件的问答:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-03-gfs/3.7-xie-wen-jian-write-file2。以下列出并根据自己的理解重述 (1)写文件失败之后primary和secondary服务器上的状态如何恢复? 一个chunk的[部分副本]完成了数据追加,而另一部分没有成功,这种状态是可以接受的,没有什么需要恢复,这是GFS的工作方式。 (2)写文件失败之后,读chunk数据会有什么不同? 部分副本追加成功,而其他副本没有成功,因此这取决于你从哪个副本读取数据,有可能读到新追加的数据,也可能读不到。 (3)可不可以通过版本号来判断副本是否有之前追加的数据? 不可以。所有secondaries都有相同的版本号。版本号只有在master指定一个新primary(通常是旧primary发生故障)时才会改变。因此,参与写操作的primary与secondary都有相同的版本号,无法通过版本号来判断它们是否一样,或许它们就是不一样的(取决于数据追加成功与否)。 (4)客户端将数据拷贝给多个副本会不会造成瓶颈? 考虑到底层网络,写入文件数据的具体传输路径可能非常重要。论文中第二次说到客户端只会将数据发送给离它最近的副本,之后那个副本会将数据转发另一个副本,以此类推形成一条链,直到所有副本都有了数据。这样一条数据传输链可以在数据中心内减少跨交换机传输(否则所有的数据吞吐都在客户端所在交换机上了)。 (5)什么时候版本号会增加? 版本号只在master节点认为chunk没有primary时才会增加。 (6)如果写入数据失败了,不是应该先找到问题在哪再重试吗? 【大体】来说,论文在重试追加数据之前没有任何中间操作。错误可能是网络数据的丢失,没什么好修复的。如果是某一个secondary服务器出现严重的故障,我们希望master节点能重新生成chunk对应的服务器列表将不工作的secondary服务器删除,再选择一个新的primary增加版本号。如果这样的话,我们就有了一组新的Primary,Secondary和版本号,同时,我们还有一个不太健康的Secondary,它包含的是旧的副本和旧的版本号,正是因为版本号是旧的,Master永远也不会认为它拥有新的数据。但是,论文中没有证据证明这些会立即发生。论文里只是说,客户端重试,并且期望之后能正常工作。最终,Master节点会ping所有的Chunk服务器,如果Secondary服务器挂了,Master节点可以发现并更新Primary和Secondary的集合,之后再增加版本号。但是这些都是之后才会发生(而不是立即发生)。 (7)如果master节点发现primary挂了会怎么办? 可以这么回答这个问题。在某个时间点,Master指定了一个Primary,之后Master会一直通过定期的ping来检查它是否还存活。因为如果它挂了,Master需要选择一个新的Primary。Master发送了一些ping给Primary,并且Primary没有回应,你可能会认为Master会在那个时间立刻指定一个新的Primary。但事实是,这是一个错误的想法。为什么是一个错误的想法呢?因为可能是网络的原因导致ping没有成功,所以有可能Primary还活着,但是网络的原因导致ping失败了。但同时,Primary还可以与客户端交互,如果Master为Chunk指定了一个新的Primary,那么就会同时有两个Primary处理写请求,这两个Primary不知道彼此的存在,会分别处理不同的写请求,最终会导致有两个不同的数据拷贝。这被称为脑裂(split-brain)。 脑裂是一种非常重要的概念,我们会在之后的课程中再次介绍它(详见6.1),它通常是由网络分区引起的。比如说,Master无法与Primary通信,但是Primary又可以与客户端通信,这就是一种网络分区问题。网络故障是这类分布式存储系统中最难处理的问题之一。 所以,我们想要避免错误的为同一个Chunk指定两个Primary的可能性。Master采取的方式是,当指定一个Primary时,为它分配一个租约,Primary只在租约内有效。Master和Primary都会知道并记住租约有多长,当租约过期了,Primary会停止响应客户端请求,它会忽略或者拒绝客户端请求。因此,如果Master不能与Primary通信,并且想要指定一个新的Primary时,Master会等到前一个Primary的租约到期。这意味着,Master什么也不会做,只是等待租约到期。租约到期之后,可以确保旧的Primary停止了它的角色,这时Master可以安全的指定一个新的Primary而不用担心出现这种可怕的脑裂的情况 (8)为什么立即指定一个新的primary是坏的设计?既然客户端总是先询问master节点,master指定完primary之后,将新的primary返回客户端不行吗? Robert教授:因为客户端会通过缓存提高效率,客户端会在短时间缓存Primary的身份信息(这样,客户端就不用每次都会向Master请求Primary信息)。即使没有缓存,也可能出现这种情况,客户端向Master节点查询Primary信息,Master会将Primary信息返回,这条消息在网络中传播。之后Master如果发现Primary出现故障,并且立刻指定一个新的Primary,同时向新的Primary发消息说,你是Primary。Master节点之后会向其他查询Primary的客户端返回这个新的Primary。而前一个Primary的查询还在传递过程中,前一个客户端收到的还是旧的Primary的信息。如果没有其他的更聪明的一些机制,前一个客户端是没办法知道收到的Primary已经过时了。如果前一个客户端执行写文件,那么就会与后来的客户端产生两个冲突的副本。 (9)如果是对一个新的文件进行追加,那这个新的文件没有副本,会怎么样? Robert教授:你会按照黑板上的路径(见GFS写文件)再执行一遍。Master会从客户端收到一个请求说,我想向这个文件追加数据。我猜,Master节点会发现,该文件没有关联的Chunk。Master节点或许会通过随机数生成器创造一个新的Chunk ID。之后,Master节点通过查看自己的Chunk表单发现,自己其实也没有Chunk ID对应的任何信息。之后,Master节点会创建一条新的Chunk记录说,我要创建一个新的版本号为1,再随机选择一个Primary和一组Secondary并告诉它们,你们将对这个空的Chunk负责,请开始工作。论文里说,每个Chunk默认会有三个副本,所以,通常来说是一个Primary和两个Secondary。
https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-03-gfs/3.8
学生提问:客户端重新发起写入的请求时从哪一步开始重新执行的?
Robert教授:根据我从论文中读到的内容,(当写入失败,客户端重新发起写入数据请求时)客户端会从整个流程的最开始重发。客户端会再次向Master询问文件最后一个Chunk是什么,因为文件可能因为其他客户端的数据追加而发生了改变。
学生提问:为什么GFS要设计成多个副本不一致?
Robert教授:我不明白GFS设计者为什么要这么做。GFS可以设计成多个副本是完全精确同步的,你们在lab2和lab3会设计一个系统,其中的副本是同步的。并且你们也会知道,为了保持同步,你们要使用各种各样的技术。如果你们想要让副本保持同步,其中一条规则就是你们不能允许这种只更新部分服务器的不完整操作。这意味着,你必须要有某种机制,即使客户端挂了,系统仍然会完成请求。如果这样的话,GFS中的Primary就必须确保每一个副本都得到每一条消息。
学生提问:如果第一次写B失败了,C应该在B的位置吧?
Robert教授:实际上并没有。实际上,Primary将C添加到了Chunk的末尾,在B第一次写入的位置之后。我认为这么做的原因是,当写C的请求发送过来时,Primary实际上可能不知道B的命运是什么。因为我们面对的是多个客户端并发提交追加数据的请求,为了获得高性能,你会希望Primary先执行追加数据B的请求,一旦获取了下一个偏移量,再通知所有的副本执行追加数据C的请求,这样所有的事情就可以并行的发生。
也可以减慢速度,Primary也可以判断B已经写入失败了,然后再发一轮消息让所有副本撤销数据B的写操作,但是这样更复杂也更慢。
有人会问,如何将这里的设计转变成强一致的系统,从而与我们前面介绍的单服务器模型更接近,也不会产生一些给人“惊喜”的结果。实际上我不知道怎么做,因为这需要完全全新的设计。目前还不清楚如何将GFS转变成强一致的设计。但是,如果你想要将GFS升级成强一致系统,我可以为你列举一些你需要考虑的事情:
- 你可能需要让Primary来探测重复的请求,这样第二个写入数据B的请求到达时,Primary就知道,我们之前看到过这个请求,可能执行了也可能没执行成功。Primay要尝试确保B不会在文件中出现两次。所以首先需要的是探测重复的能力。
- 对于Secondary来说,如果Primay要求Secondary执行一个操作,Secondary必须要执行而不是只返回一个错误给Primary。对于一个严格一致的系统来说,是不允许Secondary忽略Primary的请求而没有任何补偿措施的。所以我认为,Secondary需要接受请求并执行它们。如果Secondary有一些永久性故障,例如磁盘被错误的拔出了,你需要有一种机制将Secondary从系统中移除,这样Primary可以与剩下的Secondary继续工作。但是GFS没有做到这一点,或者说至少没有做对。
- 当Primary要求Secondary追加数据时,直到Primary确信所有的Secondary都能执行数据追加之前,Secondary必须小心不要将数据暴露给读请求。所以对于写请求,你或许需要多个阶段。在第一个阶段,Primary向Secondary发请求,要求其执行某个操作,并等待Secondary回复说能否完成该操作,这时Secondary并不实际执行操作。在第二个阶段,如果所有Secondary都回复说可以执行该操作,这时Primary才会说,好的,所有Secondary执行刚刚你们回复可以执行的那个操作。这是现实世界中很多强一致系统的工作方式,这被称为两阶段提交(Two-phase commit)。
- 另一个问题是,当Primary崩溃时,可能有一组操作由Primary发送给Secondary,Primary在确认所有的Secondary收到了请求之前就崩溃了。当一个Primary崩溃了,一个Secondary会接任成为新的Primary,但是这时,新Primary和剩下的Secondary会在最后几个操作有分歧,因为部分副本并没有收到前一个Primary崩溃前发出的请求。所以,新的Primary上任时,需要显式的与Secondary进行同步,以确保操作历史的结尾是相同的。
- 最后,时不时的,Secondary之间可能会有差异,或者客户端从Master节点获取的是稍微过时的Secondary。系统要么需要将所有的读请求都发送给Primary,因为只有Primary知道哪些操作实际发生了,要么对于Secondary需要一个租约系统,就像Primary一样,这样就知道Secondary在哪些时间可以合法的响应客户端。
为了实现强一致,以上就是我认为的需要在系统中修复的东西,它们增加了系统的复杂度,增加了系统内部组件的交互。我也是通过思考课程的实验,得到上面的列表的,你们会在lab2,3中建立一个强一致系统,并完成所有我刚刚说所有的东西。
最后,让我花一分钟来介绍GFS在它生涯的前5-10年在Google的出色表现,总的来说,它取得了巨大的成功,许多许多Google的应用都使用了它,许多Google的基础架构,例如BigTable和MapReduce是构建在GFS之上,所以GFS在Google内部广泛被应用。它最严重的局限可能在于,它只有一个Master节点,会带来以下问题:
- Master节点必须为每个文件,每个Chunk维护表单,随着GFS的应用越来越多,这意味着涉及的文件也越来越多,最终Master会耗尽内存来存储文件表单。你可以增加内存,但是单台计算机的内存也是有上限的。所以,这是人们遇到的最早的问题。
- 除此之外,单个Master节点要承载数千个客户端的请求,而Master节点的CPU每秒只能处理数百个请求,尤其Master还需要将部分数据写入磁盘,很快,客户端数量超过了单个Master的能力。
- 另一个问题是,应用程序发现很难处理GFS奇怪的语义(本节最开始介绍的GFS的副本数据的同步,或者可以说不同步)。
- 最后一个问题是,从我们读到的GFS论文中,Master节点的故障切换不是自动的。GFS需要人工干预来处理已经永久故障的Master节点,并更换新的服务器,这可能需要几十分钟甚至更长的而时间来处理。对于某些应用程序来说,这个时间太长了。

#参考文献
- 6.824 Schedule: Spring 2021
- Lecture 03 - GFS:https://mit-public-courses-cn-translatio.gitbook.io/mit6-824/lecture-03-gfs
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)