[PaperNotes]2020.Optimizing Federated Learning on Non-IID Data with Reinforcement Learning

文章目录
Optimizing Federated Learning on Non-IID Data with Reinforcement Learning
文章链接:https://ieeexplore.ieee.org/document/9155494/
作者:Hao Wang,Zakhary Kaplan,Di Niu,Baochun Li
发表:IEEE INFOCOM 2020 - IEEE Conference on Computer Communications
截止当前(2021.04.16)被引次数:25
Zotero links
FL的两大挑战
SEMI - 2020 - Applying Deep Reinforcement Learning Techniques in Federated Learning:https://www.youtube.com/watch?v=JlvizFBFCTw
-

减少开销的可能方法
- 减少通信轮数:本地更新
- 减少每一轮传输的信息大小

-
统计异构性 non-id 数据
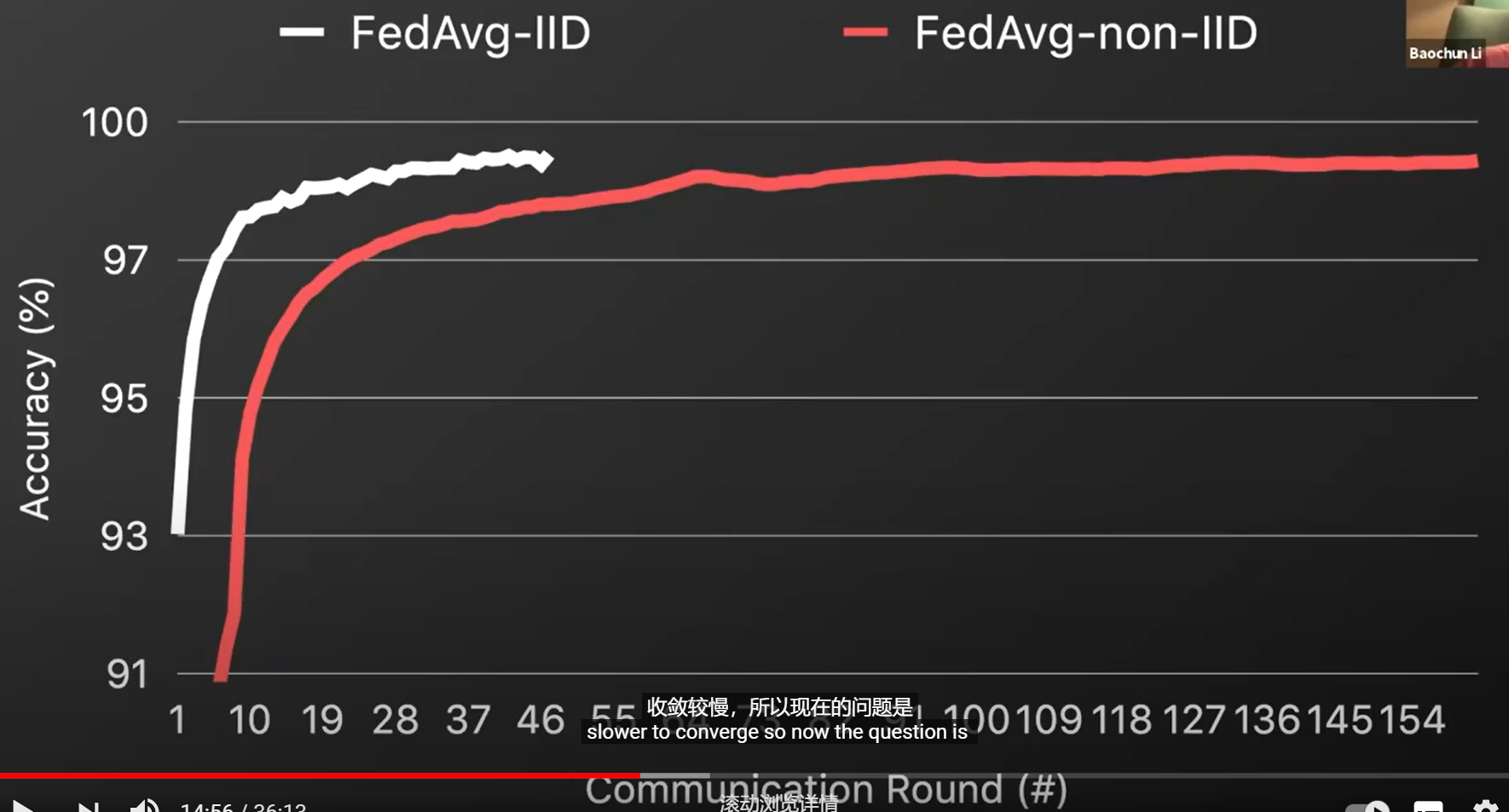
ML算法假设训练数据是iid。 FL算法的训练数据基于non-iid data (non-iid 数据向training中引入了bias,导致更慢的收敛)
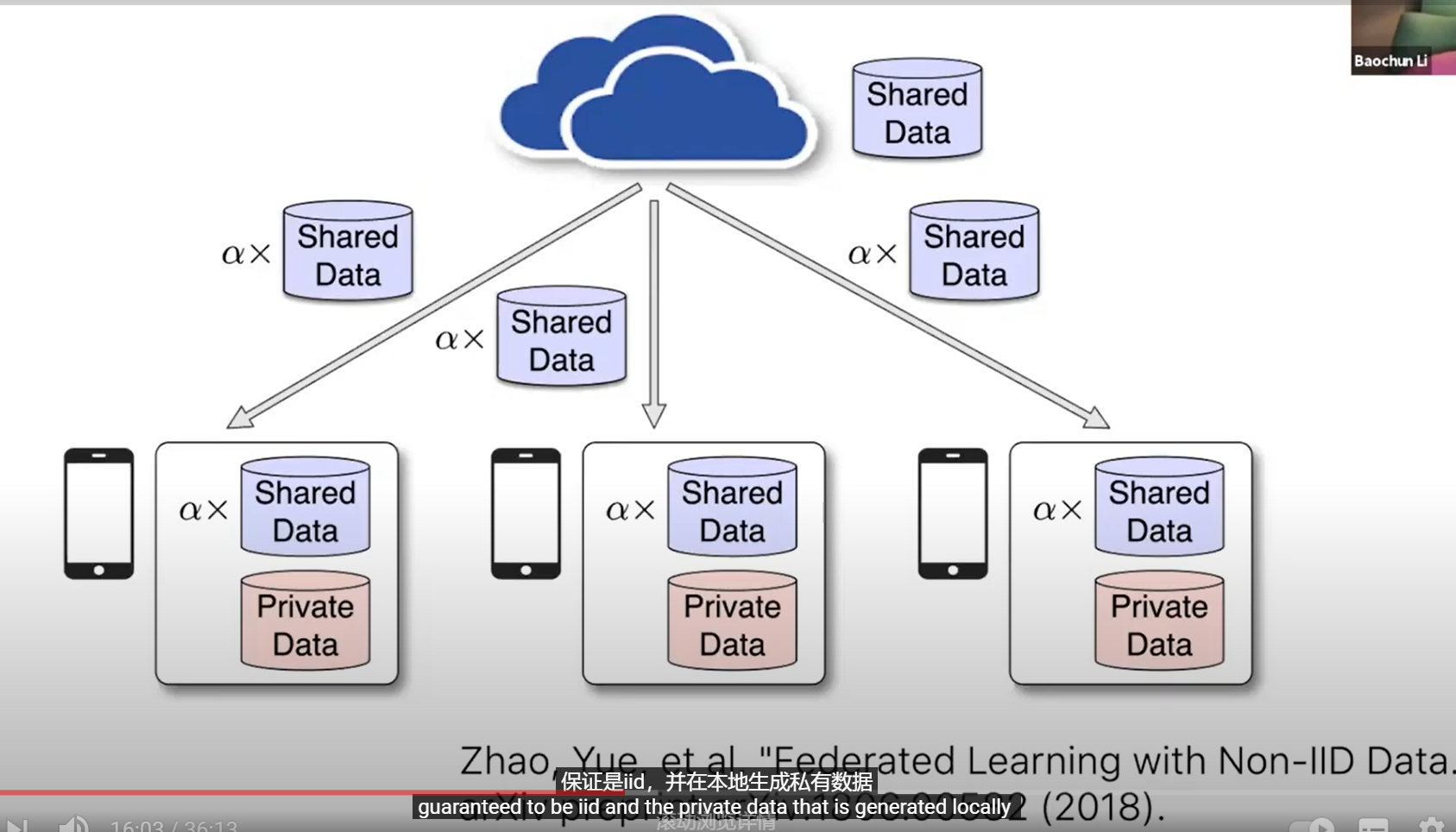
上面的解决方案带来两个问题:1)如何获得真正的共享数据【因为所有的数据都在本地】;2)实际上增加了更多的通讯开销, 用于下载共享数据
==» client selection,选择一部分设备来减少设备之间的开销。
Abstract
痛点:1) 移动设备有限的网络连接, 使得FL在所有参与设备上并行执行模型更新与聚合不实际;2)non-iid data对FL的收敛与训练速度增加了额外的挑战
本文提出 FAVOR,一种经验驱动的控制(experience-driven control)框架 智能选择客户端设备参与每一轮的联邦学习,以抵消non-iid data引入的偏差,加快收敛速度。
an implicit connection between the distribution of training data on a device and the model weights trained based on those data 发现在这些实验数据中,设备上训练数据的分布与模型权重之间存在 隐含的联系,使得我们可以根据上传的模型权重 to profile the data distribution(来分析设备上的数据分布) ==» states:本地模型权重和共享的全局模型
提出基于dqn的一种机制在每轮通信中选择一个设备集合 来最大化奖励值,促进了验证准确率的增加,并惩罚(减少)了更多通信轮数的使用。
实验: PyTorch,dataset:MNIST,FashionMNIST,CIFAR-10, 与FedAvg算法对比
Introduction
已有研究指出FL的性能,尤其是FedAvg,因为non-iid data的出现而严重下降。
FedAvg随机选择一个设备子集合,并将他们的本地模型权重平均后更新全局模型。 从全局来看,随机选择的本地数据集可能不会影响真实数据分布,但一定 引入bias到全局模型更新中。 non-iid data设备之间很大不同,聚合分散模型减慢了收敛继而降低了模型精度。
FAVOR, aim to accelerate and stabilize the federated learning process 基于RL通过每个通信轮主动选择最佳的设备集合抵消non-iid data引入的偏差。
DRL for Client Selection
训练DRL智能体的目标是:使FL尽可能快的收敛到目标准确率(target accuracy)。
在此框架中,智能体不必收集 或 检查任何来自移动设备数据样本,只需要传输模型权重 ==» 因此origin FL一样保护了样本级的隐私。 框架只依赖模型权重信息来决定 哪个设备可能对全局模型的提升最大, 因为在设备上的数据分布和在那些数据上执行SGD获得的本地模型权重有隐含的联系。
The Agent based on Deep Q-Network
考虑到 limited available traces from federated learning jobs, 相比策略梯度方法与actor-critic方法,DQN训练更高效,而且能高效重复利用数据。
-
State
$s_t = (w_t,(w_t)^{(1)},…,(w_t)^{(N)} )$ , $w_t$ 表示t轮训练后全局模型的权重,$(w_t)^{(k)}$ 表示第k个设备的本地模型权重
没有引入额外的通信开销给设备, 因为只有设备k被选中作为client训练时,才会更新$w^{(k)}$
为解决巨大状态空间问题(CNN模型包含百万个权重),采用高效且轻量的 降维技术 。如本节第三部分
-
Action
client selection可能导致巨大的动作空间$C_K^N$ ,这使得RL training复杂化了。
==» a trick :基于DQN每一轮FL训练 智能体从N台设备中只选出一台设备。 DQN智能体学习最优动作值函数$Q^*(s_t,a)$ 的一个近似器(approximator),用于评估从$s_t$开始的最大化预计收益的action 。 ==» 因此动作空间减少为{${1,2,…,N}$ } ,a=i表示选择设备i参与FL训练
每个动作值 代表智能体在状态$s_t$时选择一个特定动作a 获得的最大化预计收益。然后选择K台设备,每台设备对应一个不同的动作a,因此得到**$Q^*{(s_t,a)}$的top-K values**
-
Reward
$r_t = \Xi^{(w_t-\Omega)} -1,t = 1,…,T$,其中$w_t$是全局模型在held-out验证集上经过t轮验证后达到的测试精度(testing accuracy),$\Omega$是目标精度(target accuracy),$\Xi$ 是正常数 在测试精度$w_t$下确保$r_t$呈指数式增长。$r_t \in (-1,0], 0\leq w_t \leq \Omega \leq 1$。当$w_t = \Omega 时,$此时$r_t$达到其最大值0。
训练DQN智能体 来最大化累计折扣奖励的期望 $R=\sum^T_{t=1}\gamma ^{t-1}r_t=\sum^T_{t=1}\gamma^{t-1}(\Xi ^{(w_t-\Omega)}-1)$ ,其中折扣因子 $\gamma \in (0,1]$ 。
$r_t$中的两个术语 $\Xi^{(w_t - \Omega)}$ 和 $-1$ motivations,
前者激励智能体选择设备达到更高的测试精度$w_t$,$\Xi$ 用$w_t$控制奖励$r_t$的增长速度。通常,ML训练过程中,模型精度以更慢的pace增长,意味着轮数t增加时,$|w_t-w_{t-1}|$ 下降。因此,我们使用**指数项**来放大随着FL进展到后期的边缘精度增加。在本实验中 $\Xi$ 设置为64。
后者-1,鼓励智能体以更少的轮数完成训练,因为消耗越多的轮数,智能体获得的累计奖励越少。
Workflow
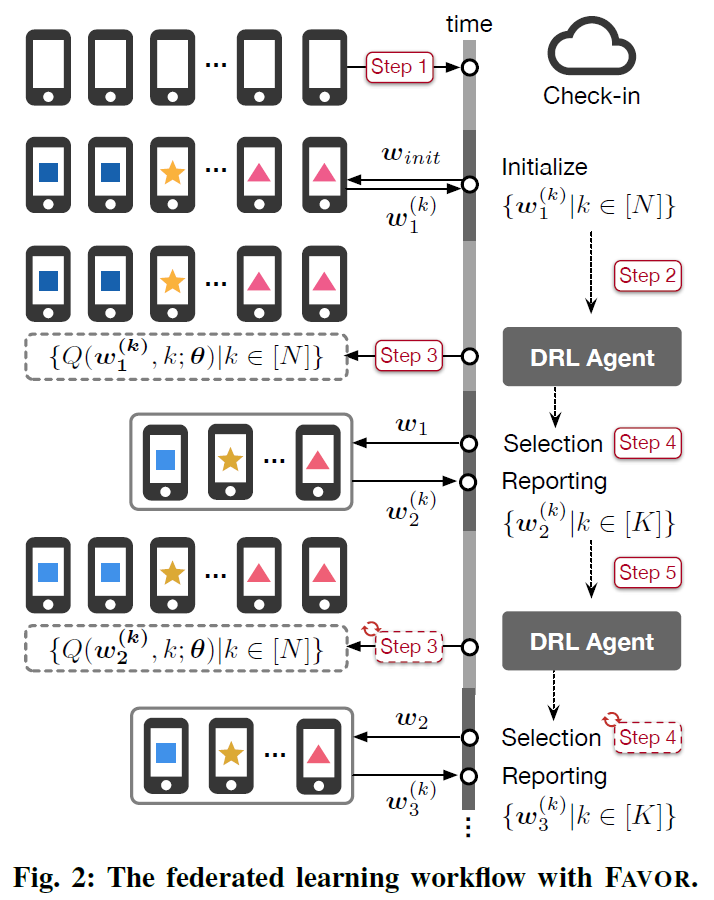
上图为FAVOR在每一轮用DRL智能体选择设备执行FL的步骤。
- Step1:FL服务器检查所有N台合格的设备
- Step2:没太设备从服务器下载初始随机模型权重$w_{init}$,在每个回合执行本地SGD,然后将结果模型权重 ${w_1^{(k)}, k \in [N]}$返回给服务器
- Step3:在第t轮($t=1,2,…,$),接收到上传的本地权重后,更新存储在服务器上的本地模型权重的对应副本。DQN智能体计算所有设备a=1,…,N的 $Q(s_t,a;\theta)$
- Step4:DQN智能体选择K台设备对应top-K values,$Q(s_t,a;\theta)$,a=1,…,N。被选的K台设备下载最新的全局模型权重$w_t$,然后在本地执行一轮SGD来获得{${ w_{t+1}^{k} k \in [K] }$ }
- Step5:上传{${ w_{t+1}^{k} k \in [K] }$ }到服务器,基于FEDAVG计算$w_{t+1}$。进入t+1轮并重复Step3-5
Dimension Reduction
PCA提取两个主成分,将状态空间映射到横纵坐标为这两个主成分的平面空间上
Evaluation
代码研究
Conclusion Remarks
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)