[C++侯捷视频课笔记]C++标准库——架构&源码

文章目录
[CPP侯捷视频课笔记]C++标准库——架构&源码
[TOC]
源码之前 了无秘密 —— 侯捷
第一讲 架构
基础:C++基本语法(包括如何正确使用模板,templates)
目标:
- 使用C++标准库
- 认识C++标准库(胸中自有丘壑)
- 良好使用C++标准库
- 扩充C++标准库
参考资料
- https://cplusplus.com/
- https://en.cppreference.com/
- https://gcc.gnu.org/
- 《The C++ Standard Library》 第二版
- STL源码剖析,2002年 侯捷,GNU2.91(旧版)
STL 六大部件
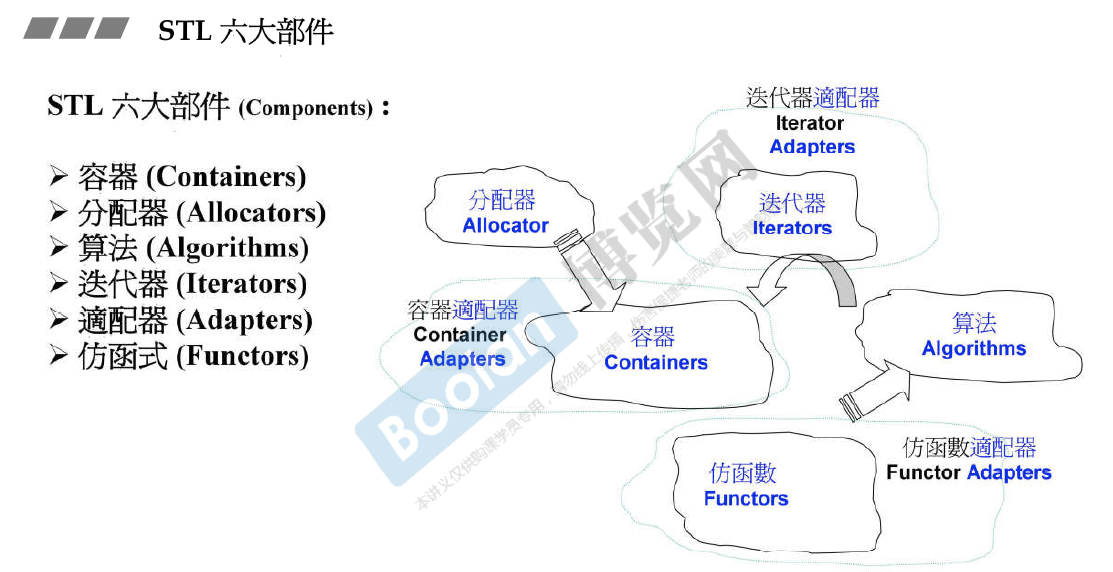
container通过allocator取得数据存储空间,algorithm通过iterator存取container内容,functor协助algorithm完成不同策略变化,adapter可以修饰或套接functor。
- 容器(containers):vector.list.deque,set,map等数据存放的类。
- 算法(algorithms):各种排序算法;sort、search、copy、erase..等
- 迭代器(iterators):扮演容器与算法之间的胶合剂,即泛型指针
- 功能函数(functors):行为类似函数,可以视为算法的某种策略
- 适配器(adapters):一种用来修饰容器(containers)或仿函数(functors)或迭代器(iterators)借口的东西
- 分配器(allocators):负责空间配置与管理
C++ 11开始
- range-based for statement
|
|
- auto 关键字
容器 —— 分类
-
Sequence Containers
-
Array

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16array<long, ASIZE> a; // 大小为ASIZE,类型为long的数组a qsort(a.data(), ASIZE, sizeof(long), compareLongs); // cstdlib 库包含qsort,bsearch long* Item = (long*)bsearch(&target, (a.data()), ASIZE, sizeof(long), compareLongs); //二分查找(&target传引用),bsearch()返回的是target对应位置的指针 array.data() //获得指向底层数组的指针 int compareLongs(const void* a, const void* b) { return ( *(long*)a - *(long*)b ); } int compareStrings(const void* a, const void* b) { if ( *(string*)a > *(string*)b ) { return 1; } else if ( *(string*)a < *(string*)b ) { return -1; } else return 0; } -
Vector
 vector向后扩展是 两倍扩展的。
vector向后扩展是 两倍扩展的。1 2 3 4 5 6 7 8 9 10#include <cstdlib> // abort() #include <cstdio> // sprintf() #include <algorithm> // sort() vector<string>c; vector.size() // vector当前实际占用大小 vector.max_size() // 返回可容纳的最大元素数,此值通常反映容器大小上的理论极限,至多为 std::numeric_limits<difference_type>::max() 。运行时,可用 RAM 总量可能会限制容器大小到小于 max_size() 的值。 vector.capacity() // 返回当前存储空间能够容纳的元素数,指在发生 realloc 前能允许的最大元素数,即预分配的内存空间。 sort(c.begin(), c.end()); snprintf(buf, 10, "%d", rand());//按照%d格式将rand()整数格式化为字符串,并将字符串复制到buf中,10为要写入的字符的最大数目,超过 10 会被截断。 auto pItem = ::find(c.begin(), c.end(), target); // :: 表示 模板函数find()是全局函数,前序查找 -
List
1 2list<string>c; c.sort(); // 容器list自带的sort(优先使用) -
Forward-List

1forward_list<string>c; -
slist (非标准库内的) 在gnu中的,与forward_list都相同。 __gnu_cxx::slist
c; -
deque
 deque
dequec; 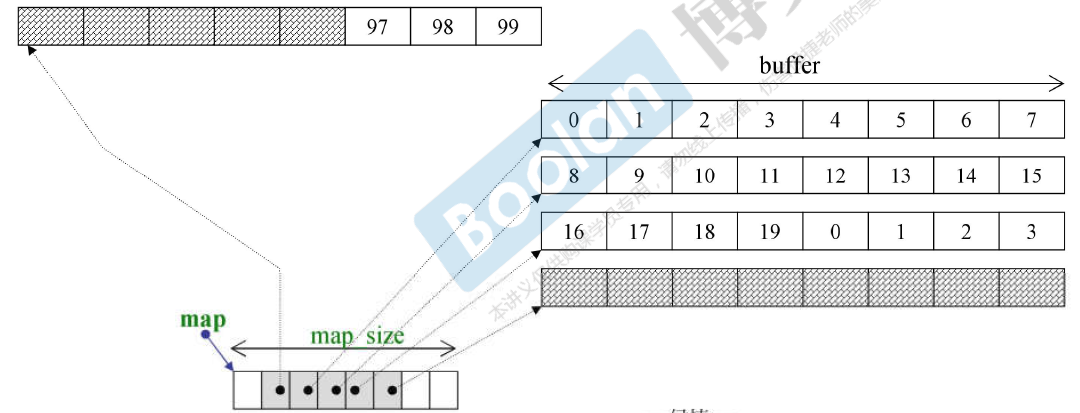
每个buffer(8个bit)连续,两边扩展。
-
-
Associative Containers
-
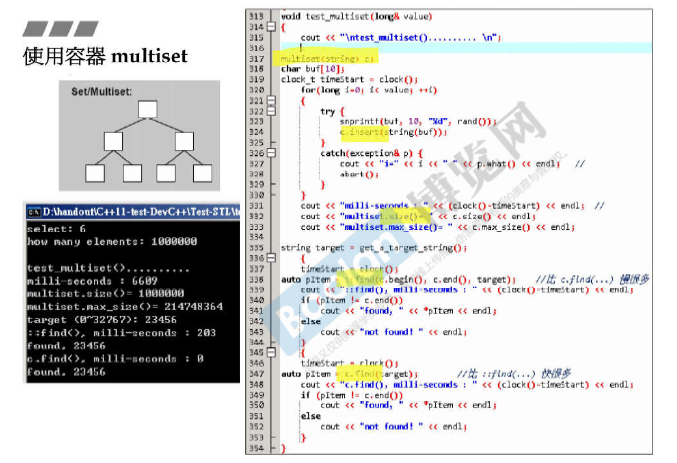
Set / Multiset
1 2 3multiset<string>c; auto pItem = ::find(c.begin(), c.end(), target); auto pItem = c.find(target); //比::find()快很多 -
Map / Multimap
-
-
Unordered Containers (不定序容器,也是关系容器的一种)
-
Unordered Set / Multiset
1 2 3 4 5 6unordered_multiset<string>c; c.bucket_count(); c.load_factor(); c.max_load_factor(); c.max_bucket_count(); // 与multiset有相同用法 c.find(),比::find()快很多【unordered_set、set 的用法与其相同】 -
Unordered Map / Multimap
1 2 3unordered_multimap<string>c; c.insert(pair<long, string>(i, buf)); // multimap不可使用[] 进行insertion auto pItem = c.find(target); // long target = get_a_target_long(); 对应的value为(*pItem).second
-
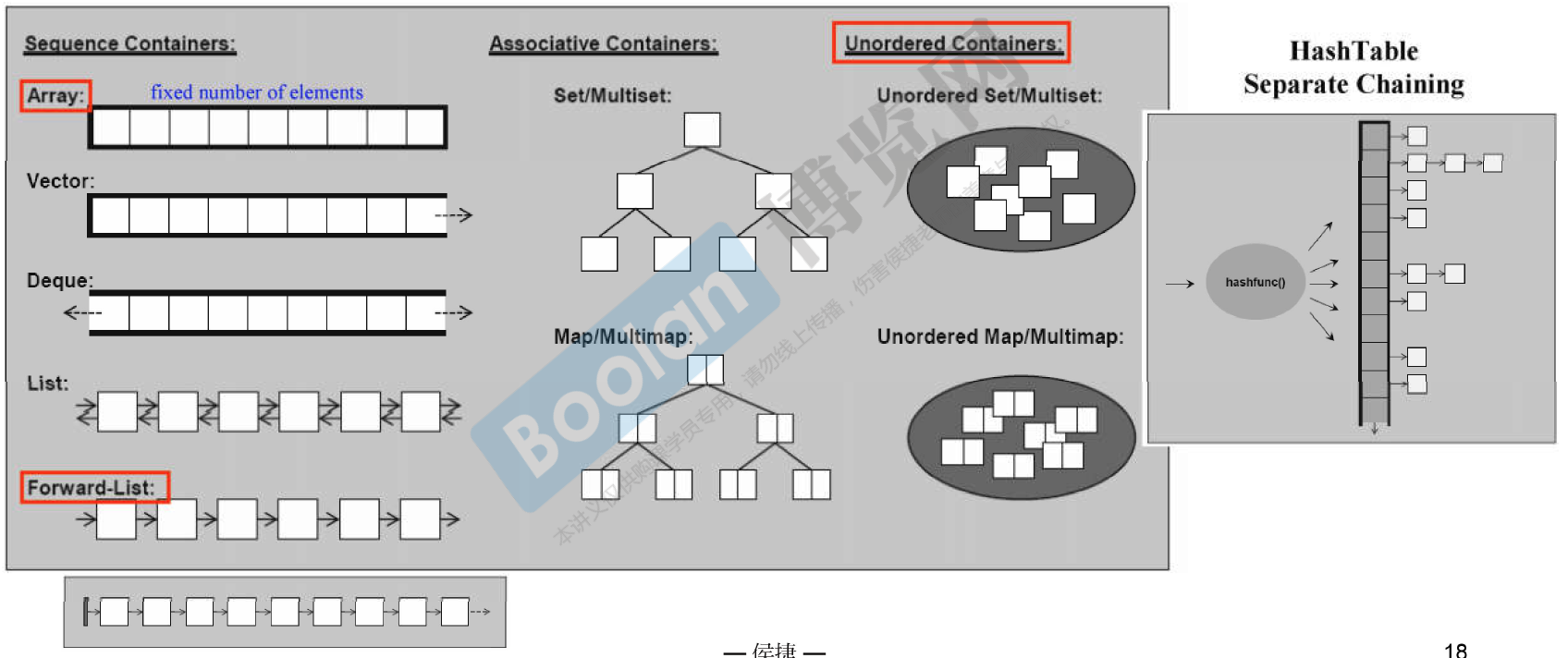
红色圈起的部分即为 C++11新增的。

第二讲 源码(主要是容器)
OOP(Object-Oriented programming)vs. GP(Generic Programming)
-
OOP企图将datas和methods关联在一起
为什么list不能使用::sort()排序? first + (last - first) /2 只有RandomAccessIterator才能如此操作

-
GP欲将datas和methods分开来 左边是数据,右边是全局的函数
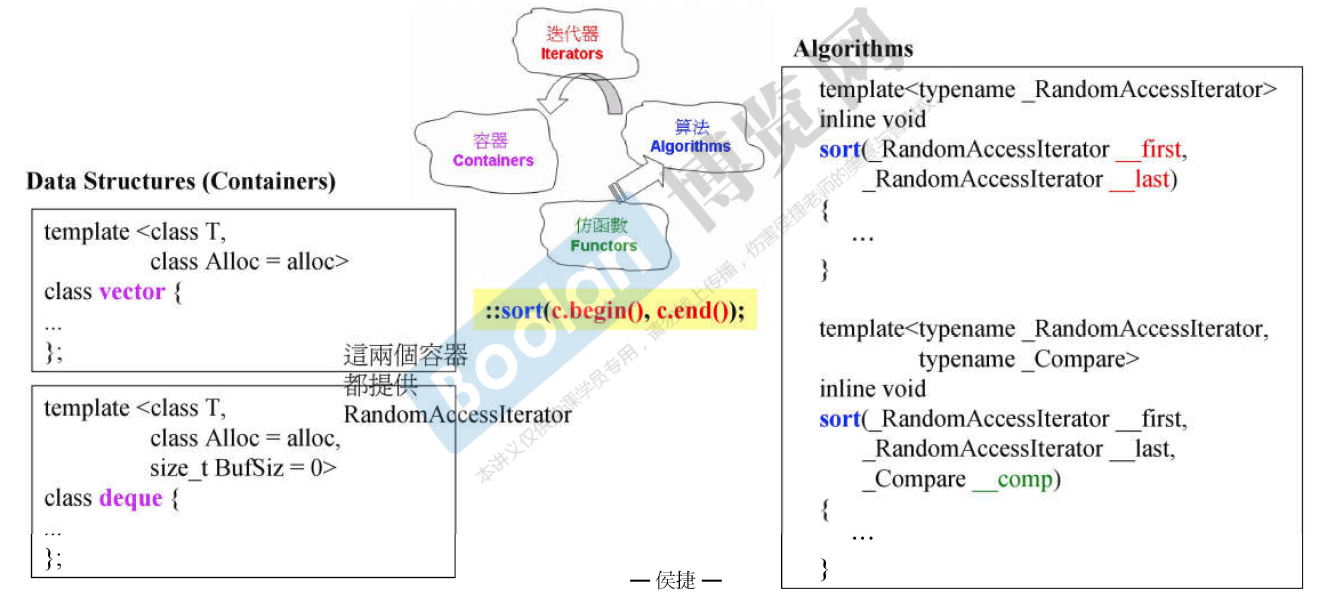
采用GP:
- Containers和Algorithms团队可各自闭门造车,其间以Iterators连通即可
- Algorithms通过Iterators确定操作范围,并通过Iterators取用Container元素

所有algorithms,其内最终涉及元素本身的操作 无非就是比大小。
技术基础 操作符重载 与 模板(特化、全特化、偏特化)
《C++ Template》第二版
类模板:
|
|
函数模板:
|
|
成员模板:
特化
出现template<> 则是特化
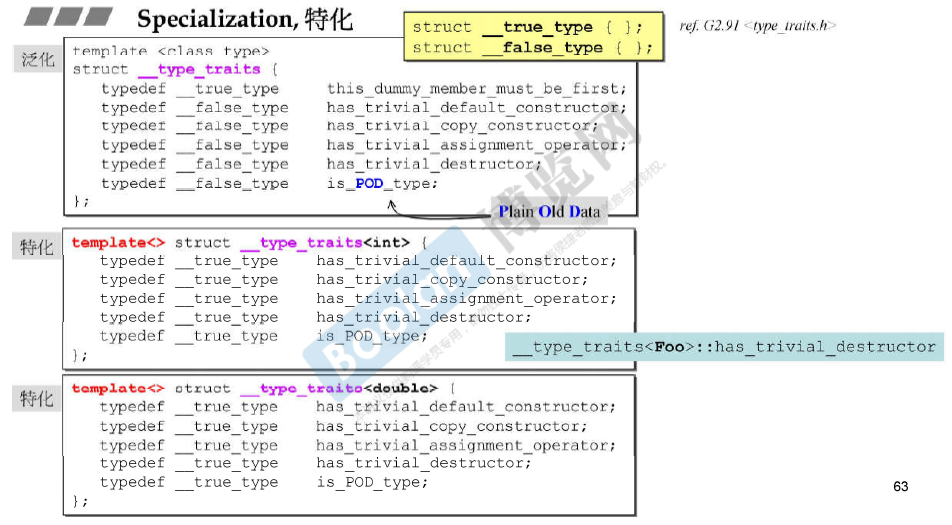


偏特化
分类:
- 模板中有 多个参数,绑定部分参数;(个数的偏特化)
- 范围的偏特化

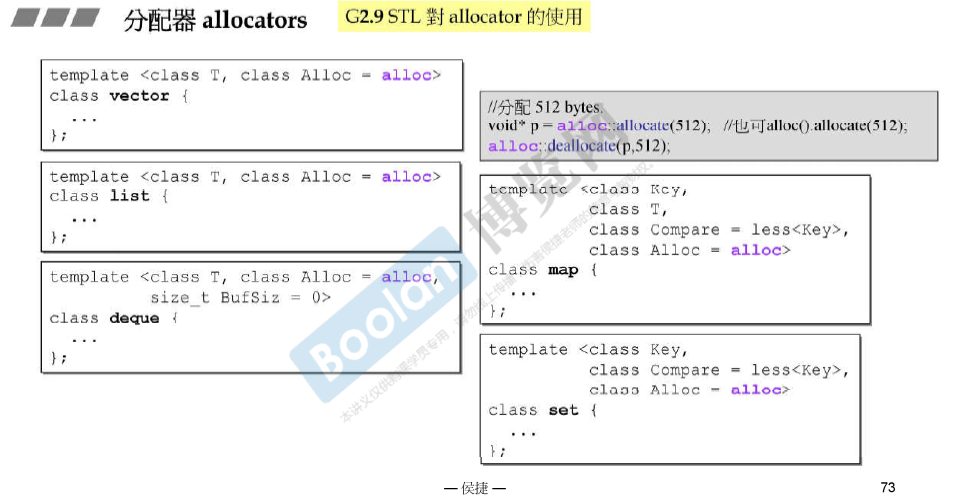
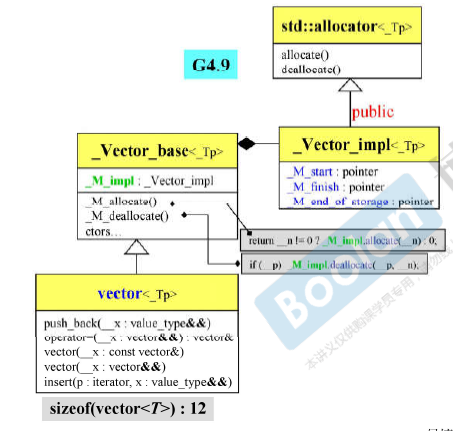
allocators分配器
malloc()的额外开销 在于:下图中 上下两个红色的部分(习惯叫 cookie,记录着这个分配空间的大小)

VC6的标准库,其中allocator的实现中 operator new()调用malloc(), operator deallocate
allocator接口的难用之处在于 要指出当时分配的内存大小即 size_type. 容器用它则没有这个问题。(为什么? 封装好了底层自动完成吗?)


BC5标准库的 allocator实现:


VC, BC, G2.9的 allocator都是以 ::operator new和::operator delete完成allocate() 和 deallocate(),没有任何特殊设计。
G 2.9 STL对allocator的使用:
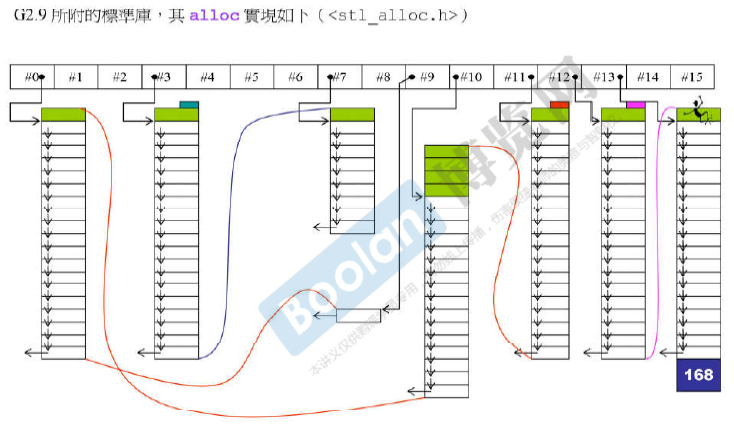
G 2.9中alloc分配器的实现:(减少了前面allocator的额外开销(cookie))一次分配很大的一块内存,然后根据申请的空间划分成小块的内存,用单向链表连接起来。
但是G4.9版本中没有使用alloc分配器。 而是std::allocator

G 4.9所附的标准库有很多 extention allocators,其中**__pool_alloc 就是G2.9的alloc**。
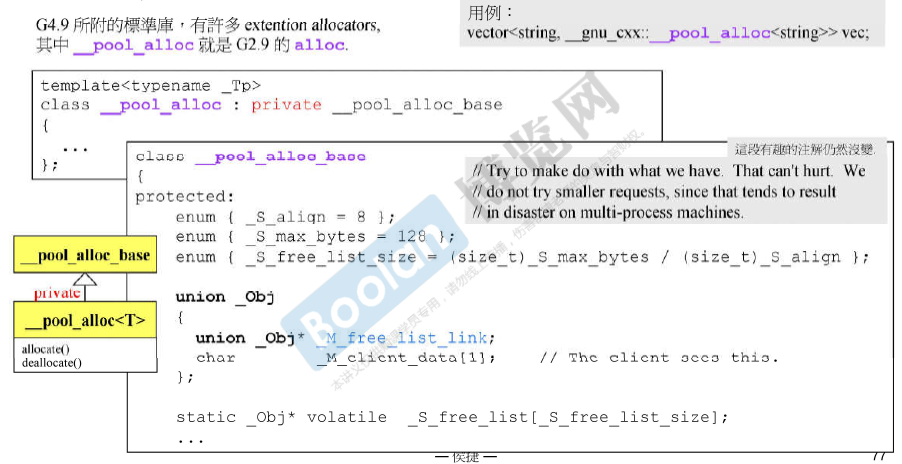
为什么默认使用的是 std::allocator 而不是更省空间的 __pool_alloc? 不知道。
容器,结构与分类
下图中 以 缩排的形式表示 “基层与衍生层”的关系,这里的衍生 是 复合关系, 而不是继承。

容器list
每次为list申请分配空间的时候,会为每个节点多申请两个指针的空间 存储 prev 和 next。
注意:__list_node中的 pointer类型是 void*
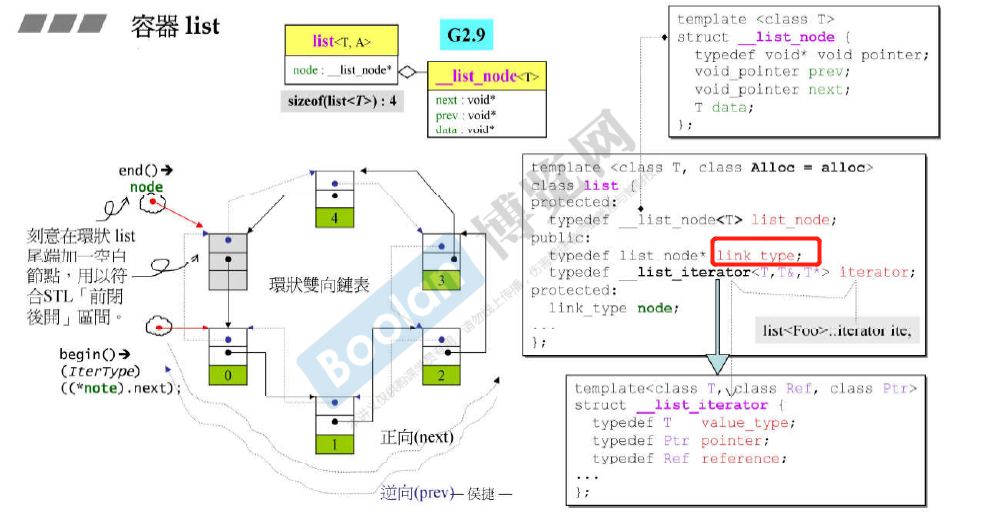
除了vector和array以外的 所有容器中的 iterator 必须是一个 class 才能是一个 智能指针。
list的iterator
iterator ++

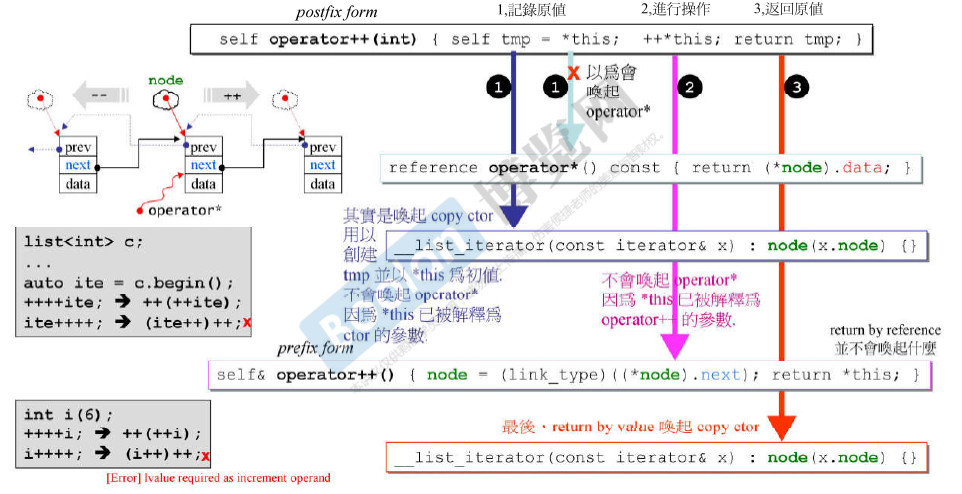
**整数类型 不能使用后加加 加两次 即 i++++是不允许的。**所以为了模拟int类型的操作,(后缀形式,后加加) operator++(int)的返回类型是 self,但 (前缀形式,前加加)operator++() 的返回类型是self &。后缀形式调用前缀形式来实现 加法(这样的方法在STL中经常使用)。
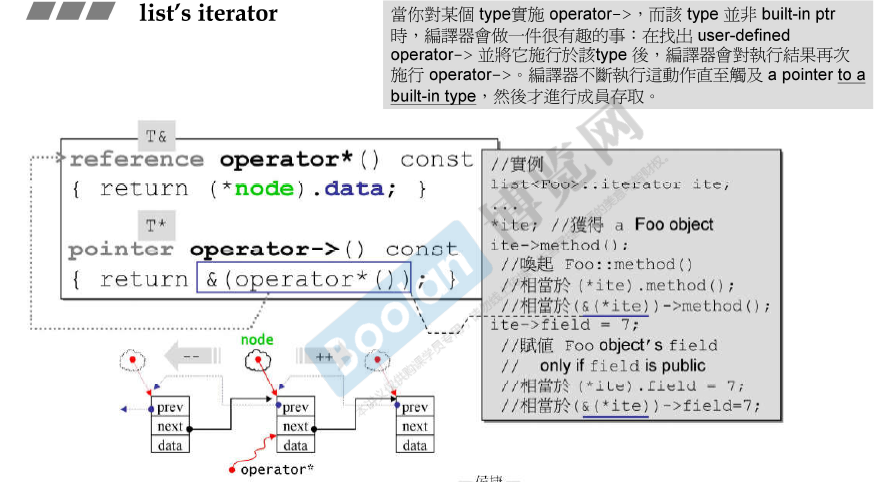
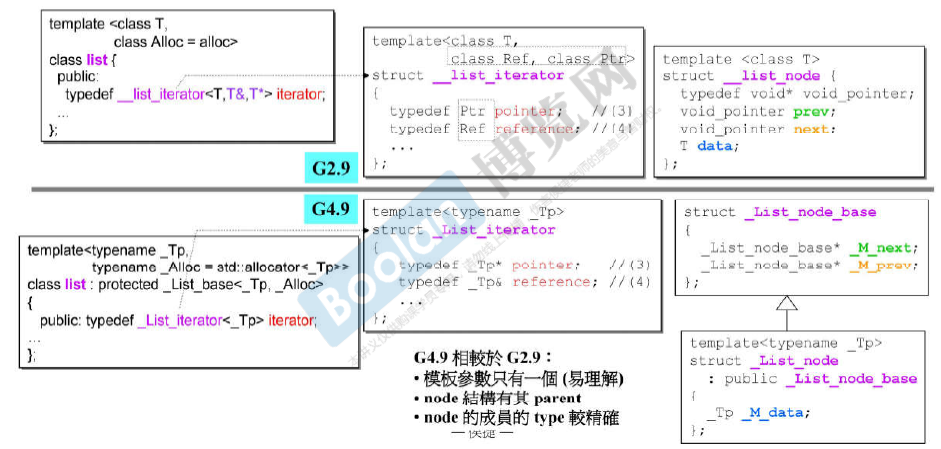
G4.9的模板参数只有一个了(容易理解)。node的成员的type更精确了,而不是void*.
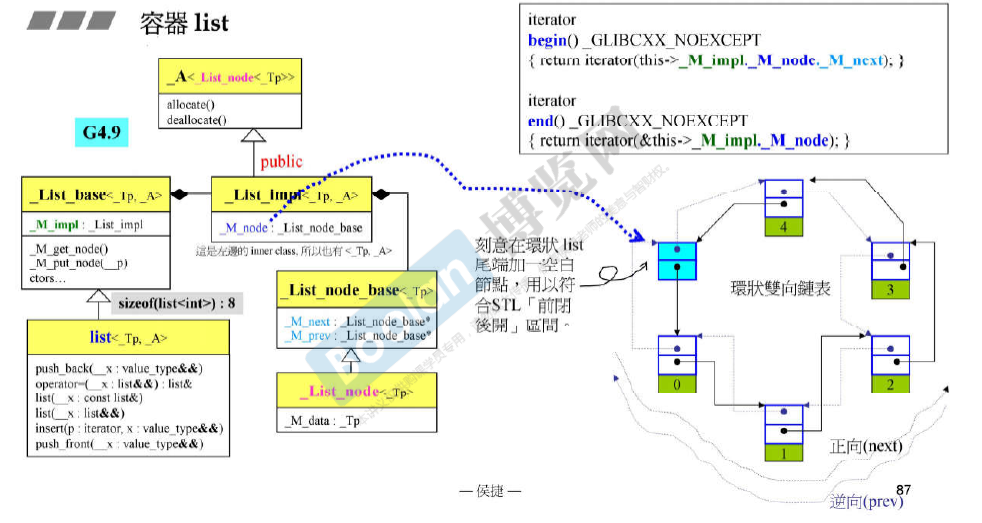
list的类之间的关系更加复杂了。(所以用G2.9版本作为讲解)
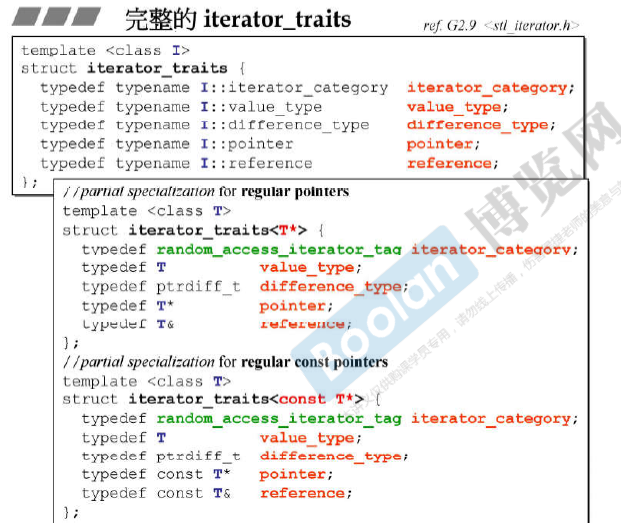
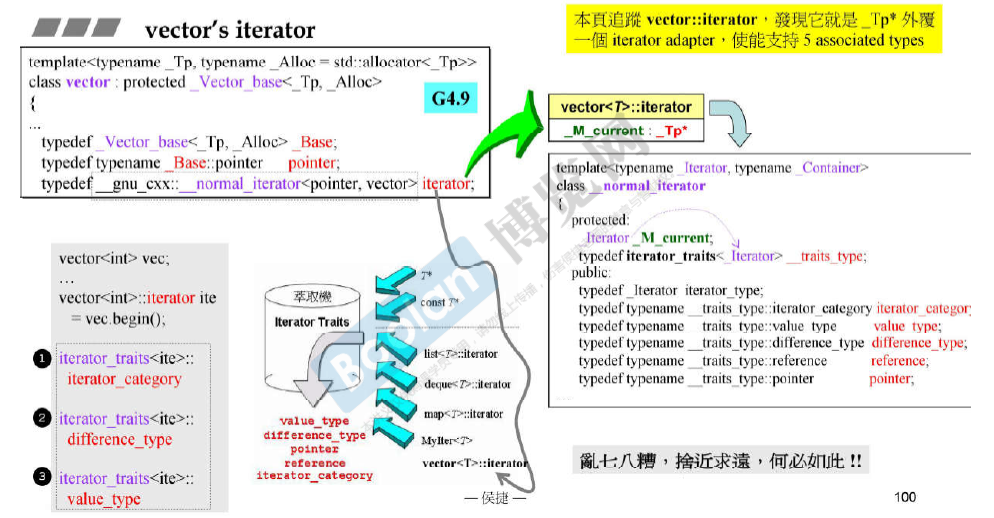
迭代器的设计规则和Iterator Traits的作用与设计
Iterator Trait 是人为设计的一种萃取机(萃取特征)。
-
iterator_category指的是 iterator的移动性质(++, –, += 3)。 -
value_type指的是实际元素的类型。 -
difference_type指的 是 两个元素之间的距离对应的类型 。 -
另外两种(这两种在算法中从未使用过)分别是:
reference_type -
pointer_type
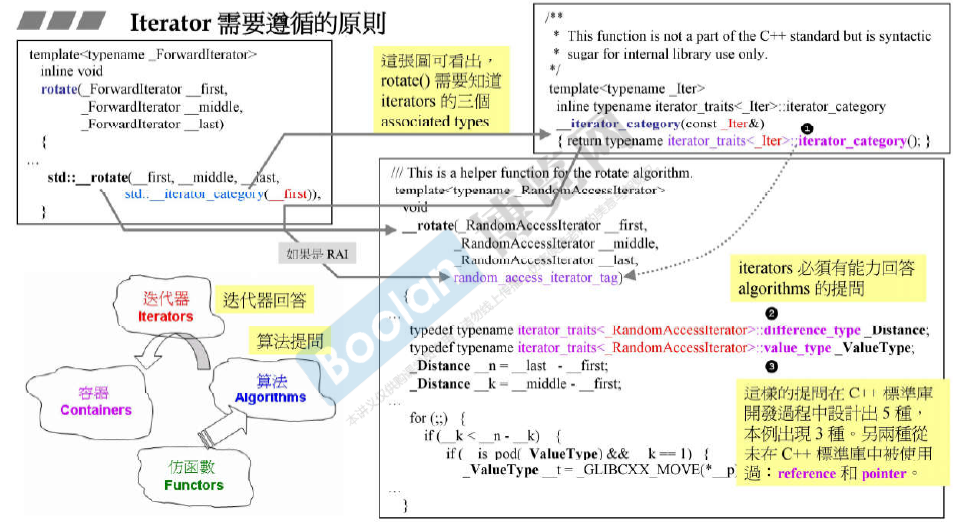
算法提问, 迭代器回答。
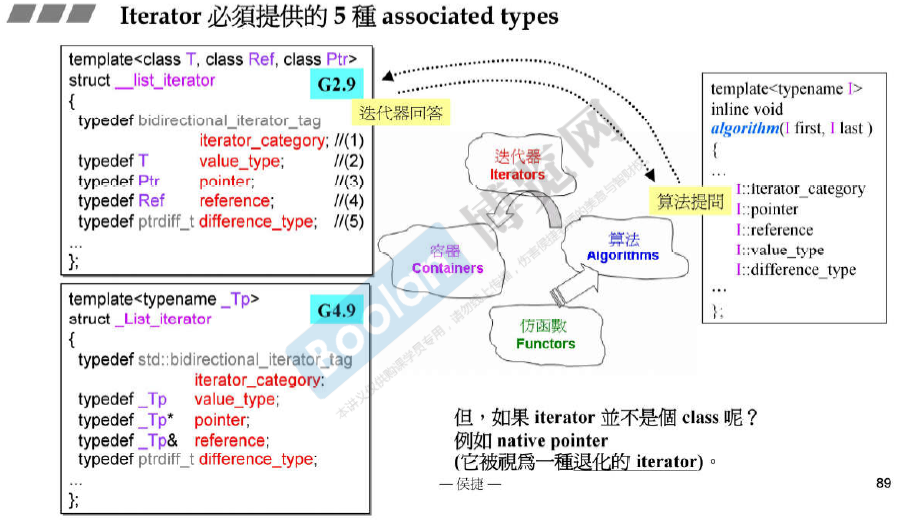
指针pointer 视作是一种退化的iterator,iterator是一种泛化的pointer。
Traits特性
Iterator Traits是一个萃取机。 用于**分离 classs iterators 和 non-class itertors **
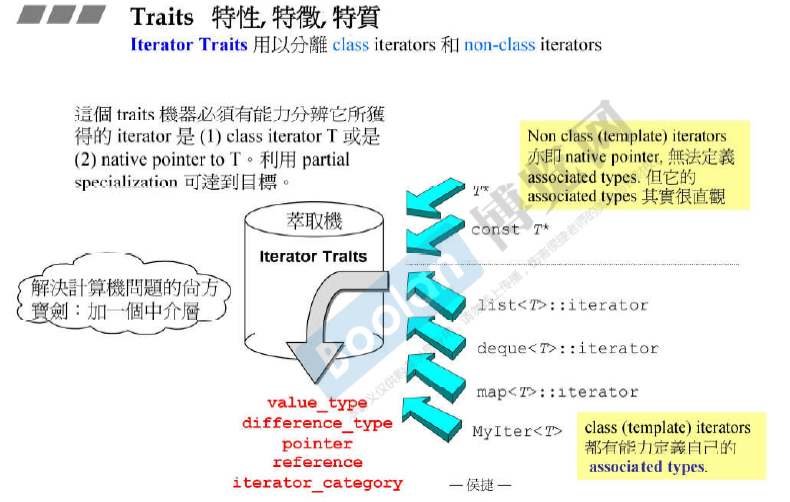
(银弹)即 解决计算机问题的尚方宝剑:加一个中介层。(这里的中介层 就是 Iterator Traits)

上图中 第三个 iterator_traits 里的声明是 typedef T value_type,而不是const T的原因是:若声明为const T,那么无法被赋值 就没有用了。
各种各样的Traits

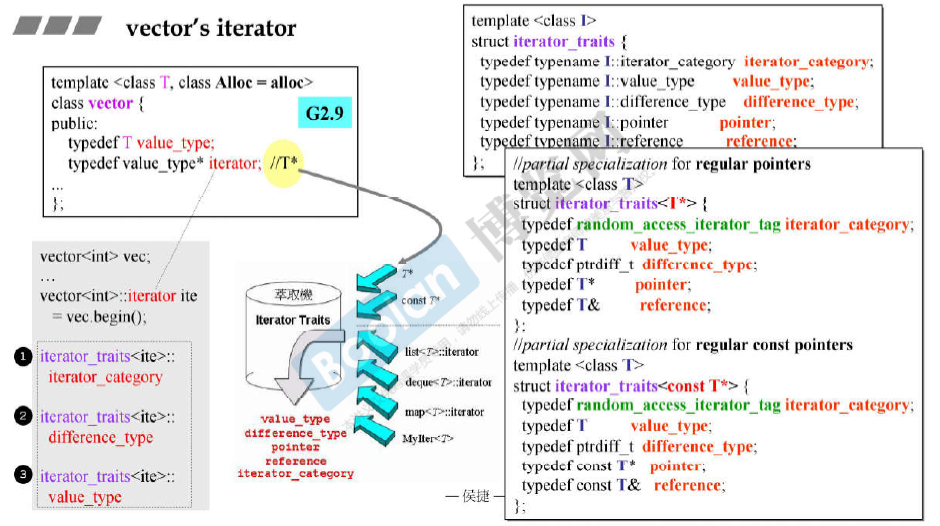
容器vector

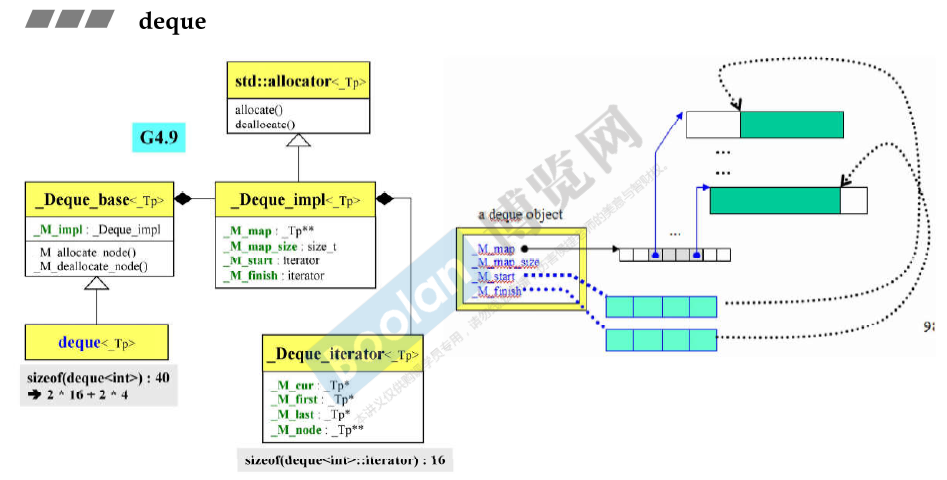
sizeof(vector<T>) 的大小为 12(32位操作系统,在64位操作系统上。即为3个指针 start, finish, end_of_storage的大小)


vector的iterator
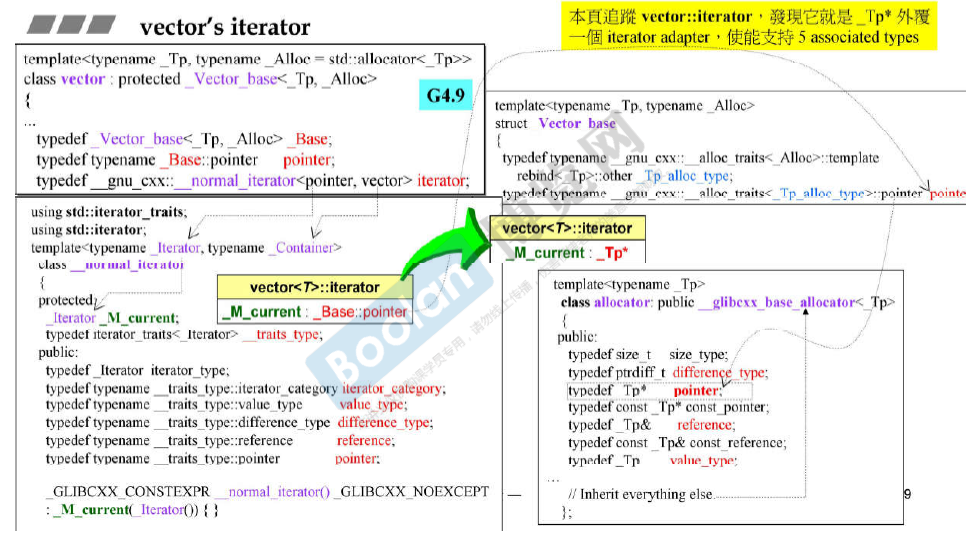
容器array
TR1:Technical Report 1. C++98与C++11之间的过渡版本(大概是2003年)。
array 没有 ctor,也没有dtor。
像array、vector连续空间的容器,可以 直接用单纯的指针作为iterator。

**typedef int T[100]; **
T c;

容器forward_list
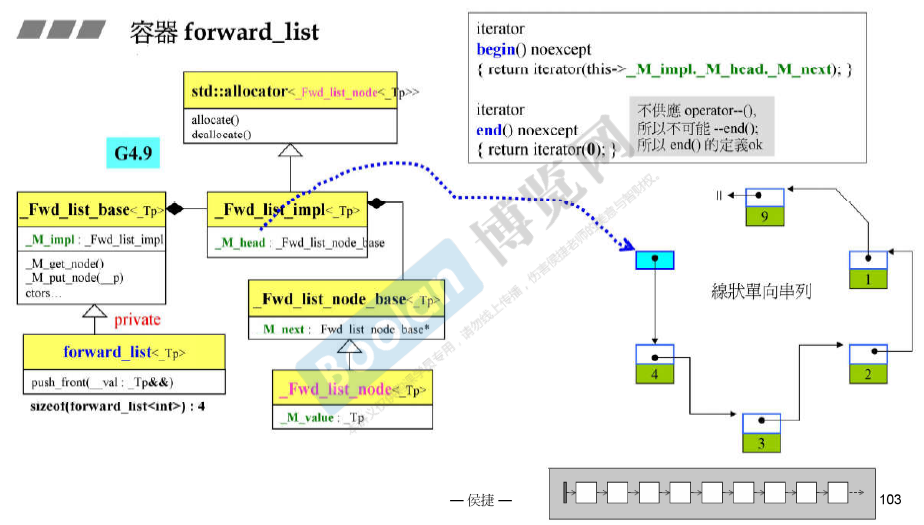
容器deque
deque号称是连续的,实际上是分段连续的。
可以双向扩充,每个buffer对应一个buffer。
deque是分段连续的,为了维持连续的表象,迭代器走到边界(first或者last)的时候需要有能力(利用node)跳到下一个元素对应的空间位置。
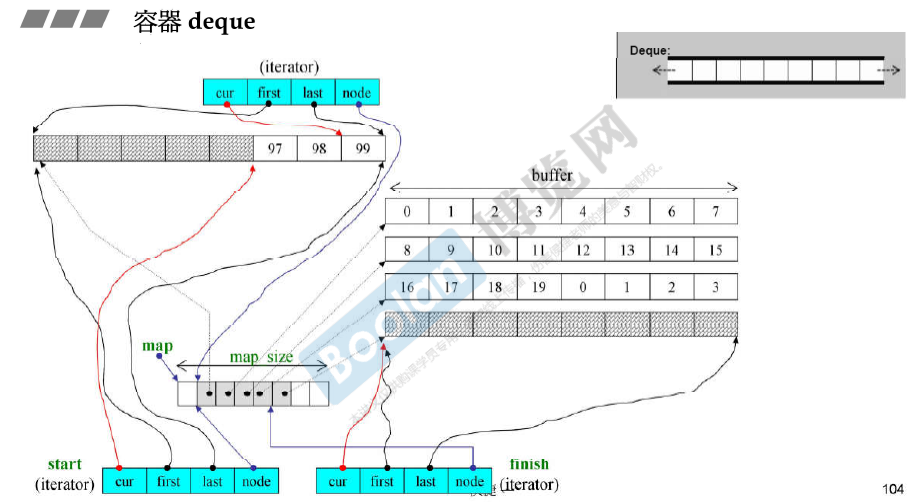
map_size 是以两倍的速度增长的(就是一个vector)。
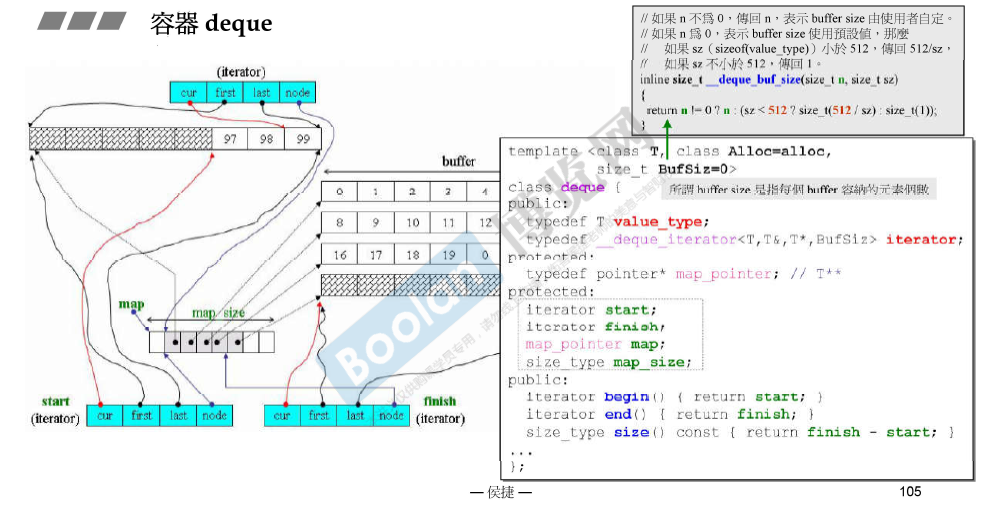
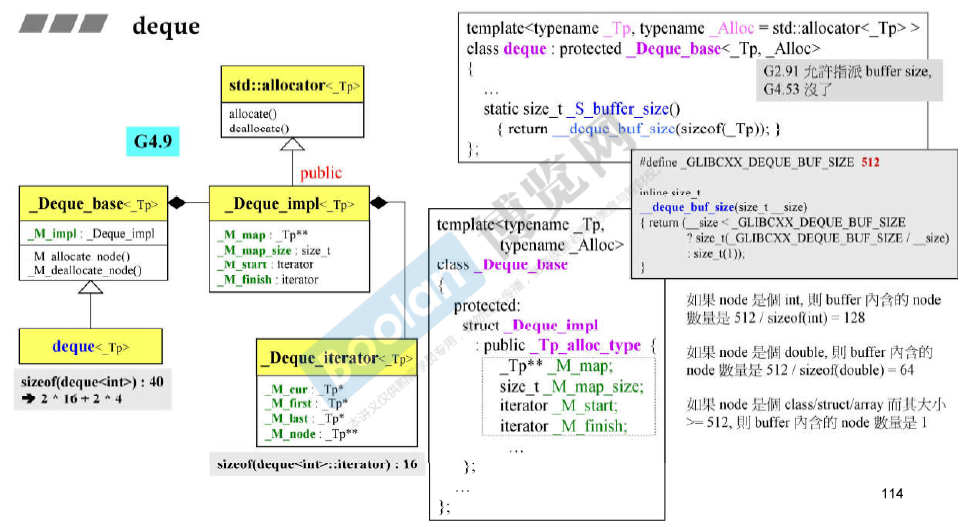
sizeof(deque<T>) = 16 + 16 + 4 + 4 = 40(32位操作系统)
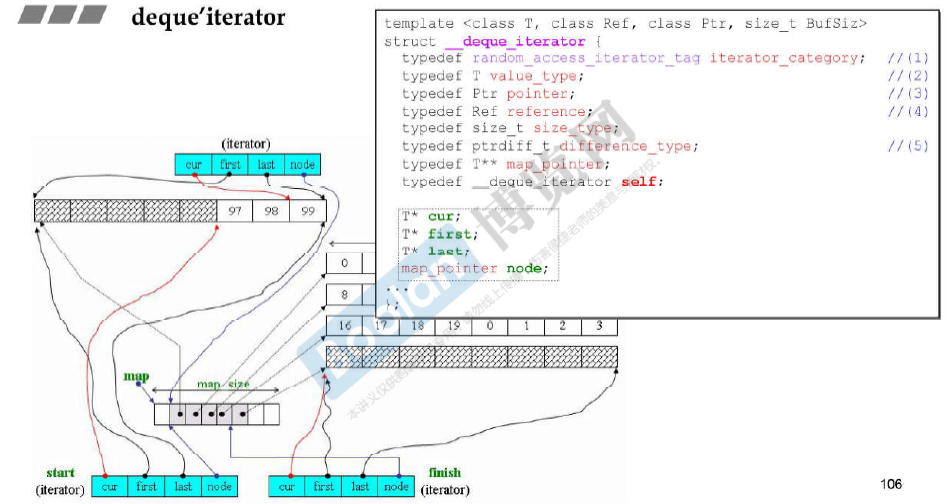
deque iteraotr里面有四个指针 即cur、first、last和node。因此sizeof(__deque_iterator<T>)的大小是16(32位操作系统)。
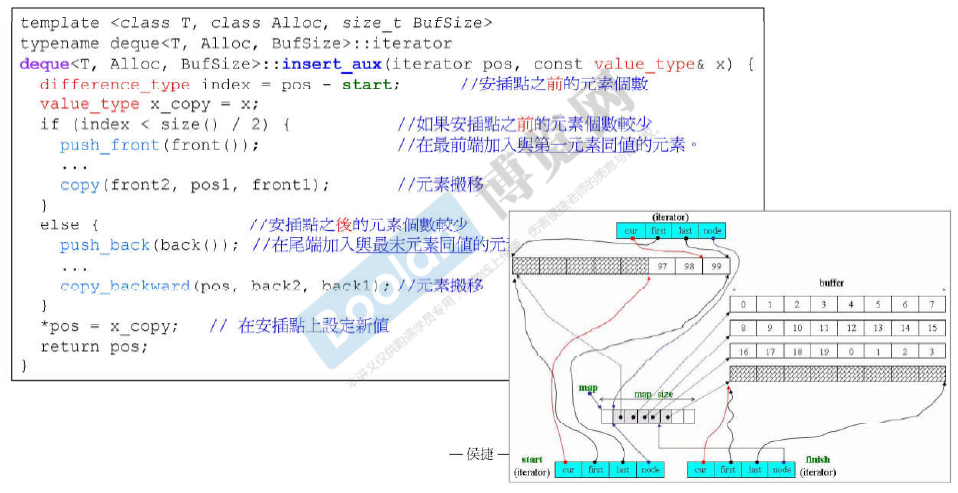
deque<T>::insert()
逻辑:
- 如果插入的位置在deque最前端,则直接push_front();
- 如果插入的位置在deque 最尾端,则直接push_back();
- 否则 判断插入的位置是靠近 前半部分 还是 后半部分,然后移动相应部分的元素,最后插入元素。

deque如何模拟连续空间
全是deque iterators的功能。 求size() 中的 finish - start 的减号经过重载的。
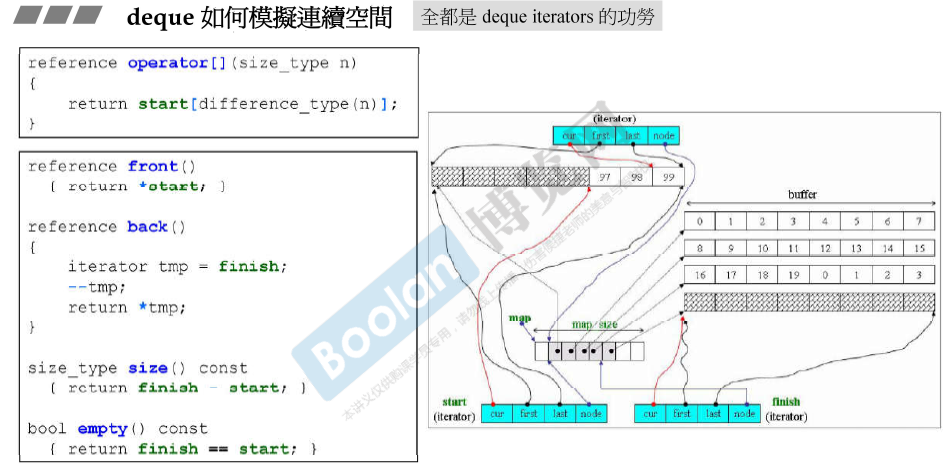
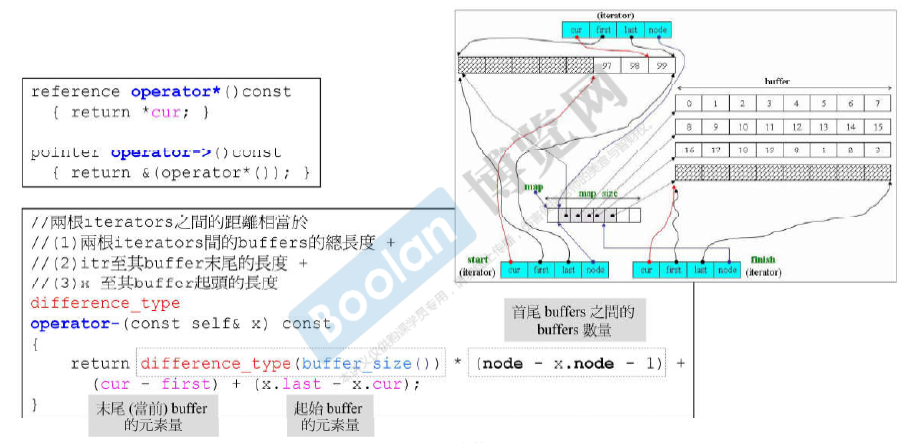

+= (-= 通过调用 += 来实现的)


G4.9版本中的deque
deque中的map 内存大小是 两倍增长的;而两端剩余未使用的内存空间会保持相等,也就是会通过移动map的元素到中段,以保证deque可以两端扩充。
容器queue
queue的内部使用了 deque。 (因为是将deque改装了,自己实际上没做什么事,所以有时称为“适配器”)

容器stack
同queue一样,内部使用了deque。
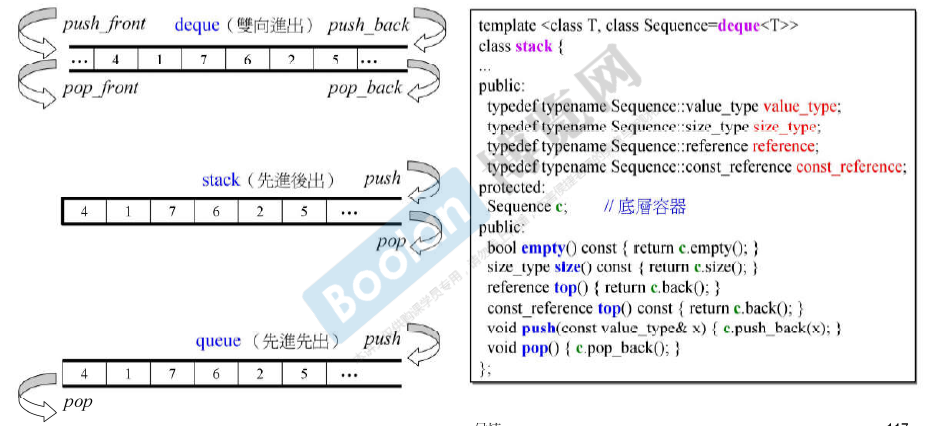
queue和stack 关于其iterator和底层结构
stack 和 queue都不允许遍历,也不提供iterator【编译错误】。
- stack和queue都可以选择list或deque为底层结构。(但是deque作为底层结构比较快!)
- stack可以选择vector作为底层结构,queue 不可以选择vector作为底层结构(pop()会调用pop_front() 发生编译错误!)
- stack和queue都 不可以选择set或map作为底层结构。



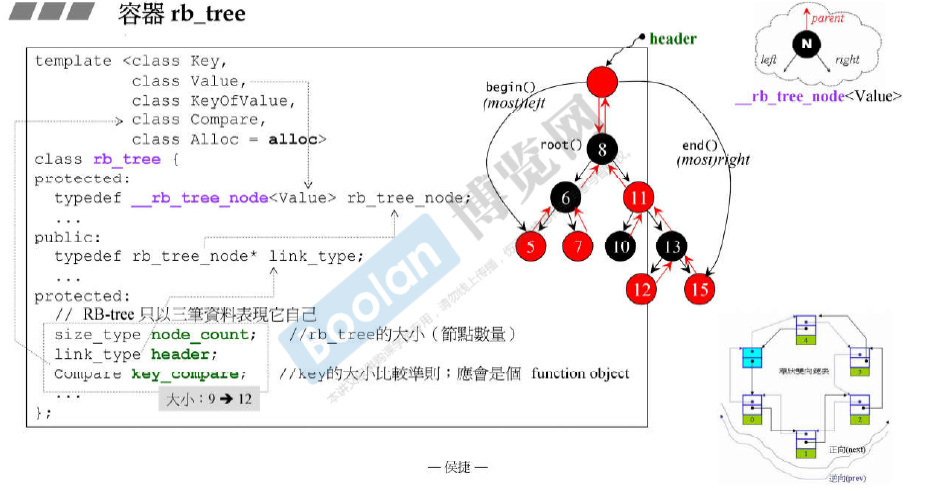
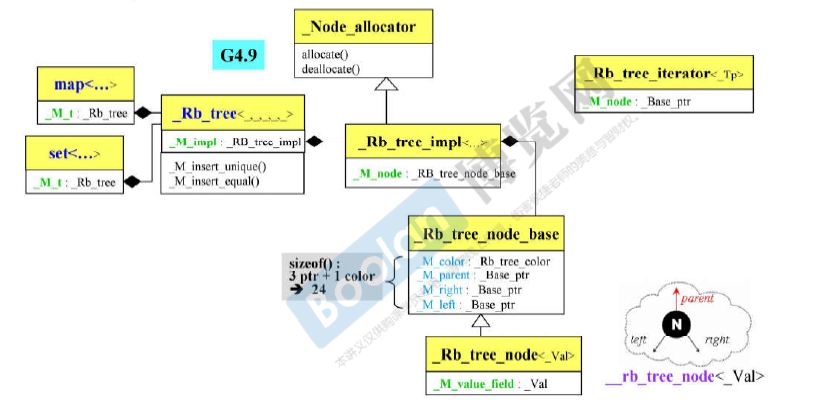
[关联式容器]容器rb_tree
前面讨论的list、vector、array、forward_list、deque、queue和stack都是序列式容器。 关联式容器查找非常快,类似一个小型数据库。
rb_tree的两个底层结构:红黑树(高度平衡的二叉搜索树,有利于查找),哈希表。
rb_tree提供“遍历”操作 及 iterators。
我们不应使用rb_tree的iterators改变元素值(因为元素其有其最严谨排列规则)。 map允许 元素的data被改变,只有 元素的key才是不可被改变的。

key和data 组成 value。
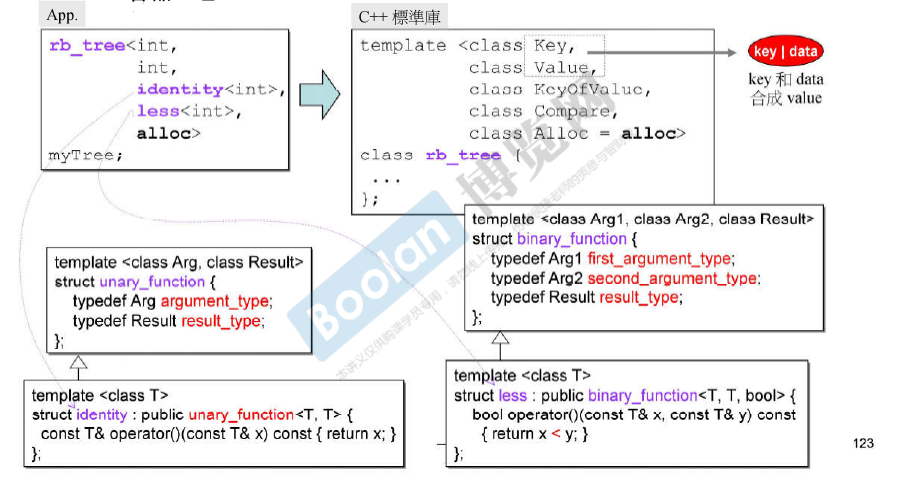
identity仿函数:实现获取自身元素。
容器rb_tree用例



容器set,multiset
-
set和multiset以rb_tree为底层结构,因此 有 元素自动排序特性,排序的依据是key(key就是value)。
-
提供遍历操作及iterators,按 ++iter遍历 就能得到排序状态值。
-
无法使用set/multiset的iterators(实际实现中的iterator是 const_iterator,见下图)改变元素值(因为key就是value);
-
set和multiset的区别在于 multiset的key可以重复。
- set元素的key必须独一无二,其insert()用的是rb_tree的insert_unique();
- multiset元素的key可以重复,其insert()用的是rb_tree的insert_equal()。

set底层实现中的后两个模板参数有默认值 less<Key> 和 alloc。
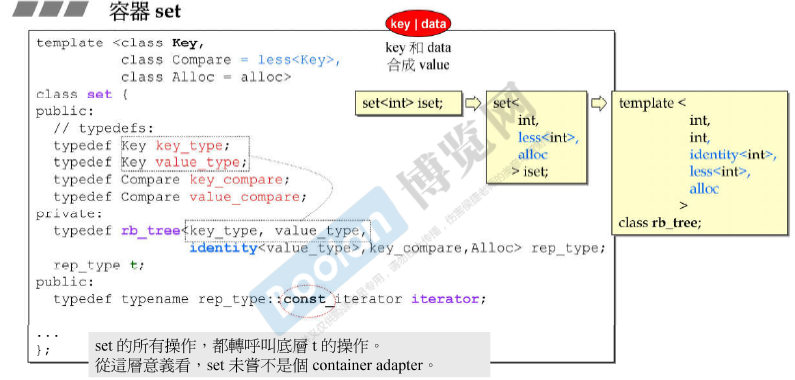
set的所有操作,都是让底层t操作,从这个意义上来看,set是个container adapter。
容器set in VC6
上面讲述的identity()是 GNUC特有的。VC6不提供identity(),set和map使用RB-tree的时候 则自己实现identity()即下图中的_Kfn。

使用容器multiset
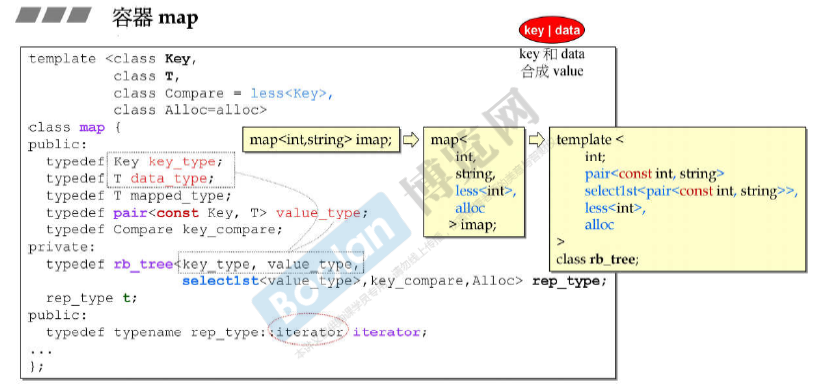
容器map, multimap
-
map和multimap以rb_tree为底层结构,因此 有 元素自动排序特性,与set/multiset不同的是,其key和data合成value,而不是(key就是value,value就是key)。
-
提供遍历操作及iterators,按 ++iter遍历 就能得到排序状态值。
-
无法使用map/multimap的iterators改变key,但是能改data。
-
map和multimap的区别在于 multimap的key可以重复。
- map元素的key必须独一无二,其insert()用的是rb_tree的insert_unique();
- multimap元素的key可以重复,其insert()用的是rb_tree的insert_equal()。

map的底层实现中后两个模板参数是默认的 即 less<Key>和alloc。 下图例子中key的类型是int,data的类型是string。
通过map的iterator可以修改data,不能修改key。下图实现中的iterator就是rb_tree的data。pair<const Key, T> value_type 中的Key是const类型,所以不能改变key。
select1st() 是GNUC独有的。
容器map,in VC6
VC6通过**自己实现 _Kn(G2.9中的select1st()功能)**来使用RB-tree。

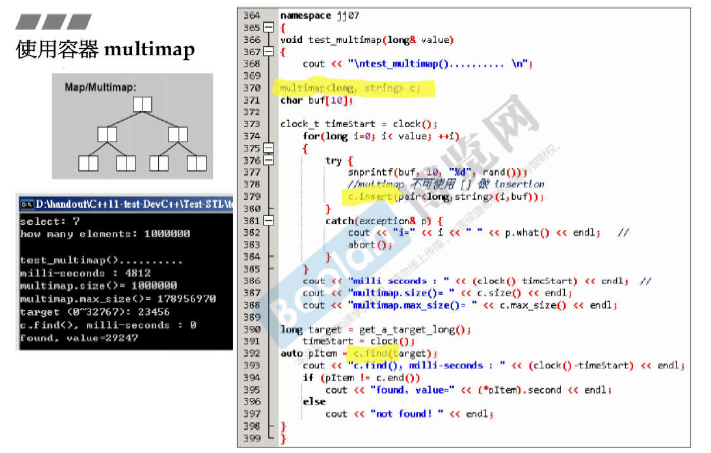
使用multimap
小技巧:每个测试用例包括在一个不同的namespace里。
下图用例的 key是[0, value), 不会重复,虽然multimap允许key重复。
multimap不可使用[] 做 insertion。
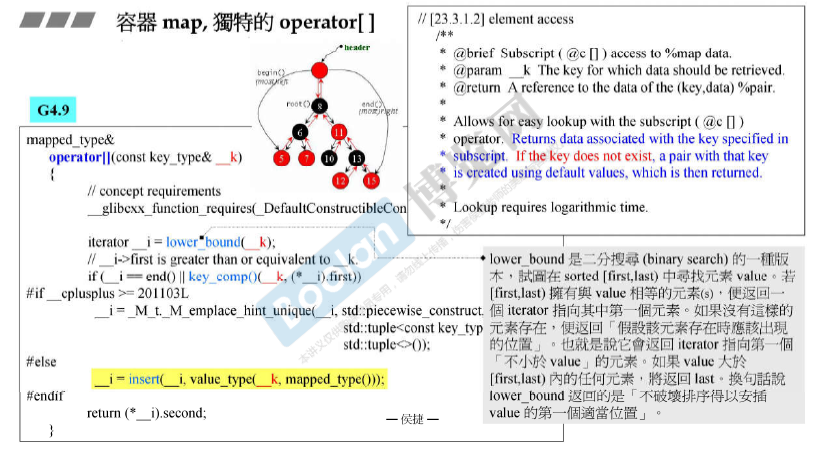
容器map独有的operator[]
返回与key对应的value。如果key不存在,将创建一个具有默认值的key 并返回。
使用容器map

红黑树:set和map的底层结构。
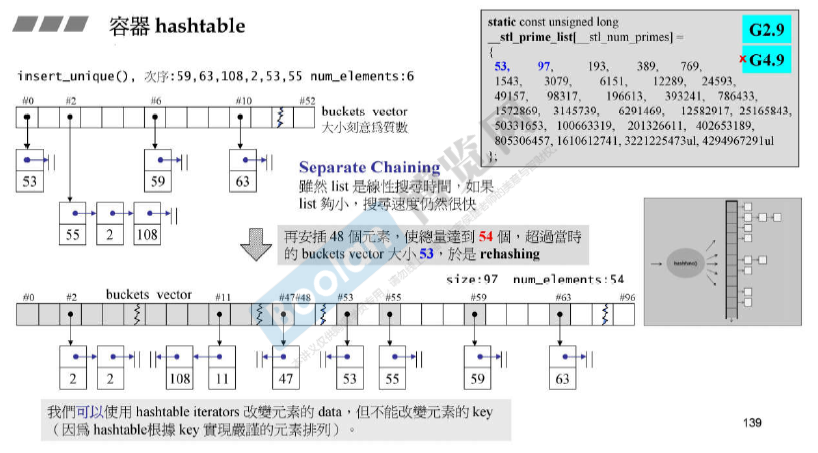
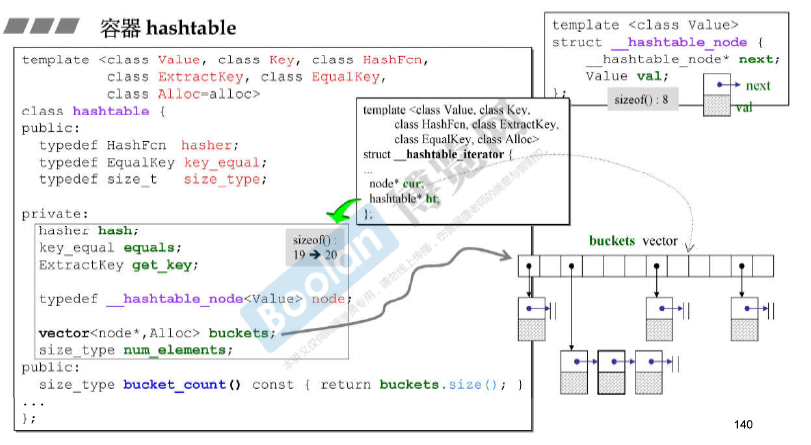
容器hashtable
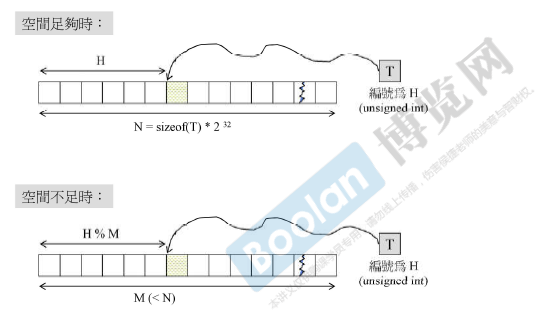
发生碰撞时,使用链表来处理冲突,称为链式哈希。
bucket(大小一般是质数, 在GUNC是53),如果一个链表的长度大于buckets vector的长度,那么一般将 bucket vector长度翻倍(最近的一个质数,如97)(经验)。 这样的操作称 rehash。时间消耗花费在重新计算位置并拷贝移动上。
下图的HashFun用于获取哈希编号。 ExtractKey用于从pair中提取处key,EqualKey用于Key的判断是否相等。
三个对象hash、equals和get_key的内部没有元素,但其实际大小为1字节,所以总共3字节。buckets是一个vector,里面有三个指针,12个字节。size_type 4个字节。因此 sizeof() = 1 * 3 + 4 * 3 + 4 + 1(对齐)= 20.
GNUC中链表是单向链表,VC6的实现是双向链表,确保能够进入下一个bucket。
使用hashtable
hashtable<const char*, const char*, hash<const char*>, identity<const char*>, **eqstr**, alloc> 中 为什么是eqstr, 而不能是strcp(),这是因为 **hashtable中要求其返回值是bool类型,而不能传回的是-1, 0, 1**,所以必须加一层外套。
hashtable使用的关键:HashFun如何设计(即 将一个对象或字符串转换成一个编号)? —— 没有统一的计算方法,只要编号够乱,不发生碰撞即可。

hash-function,hash-code
数值就作为编号。
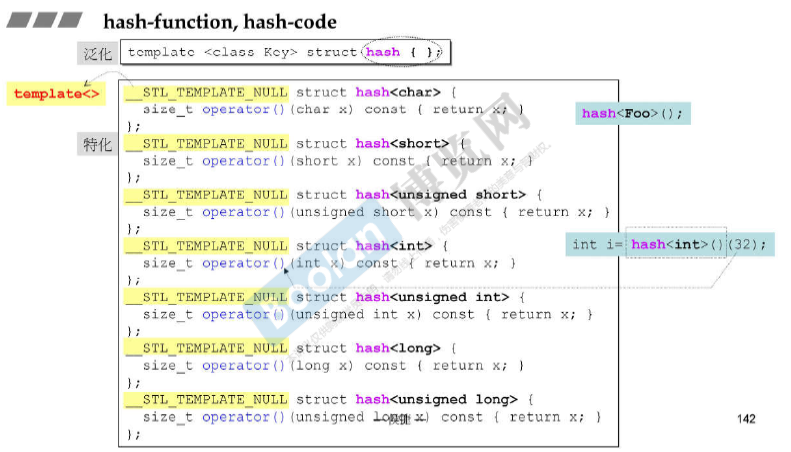
hash function的目的:希望根据元素值计算出一个 hash code(一个可以进行modulus运算的值),使得元素经hash code映射之后能够 【够乱】地被置于hashtable内。 越乱越不容易发生碰撞。
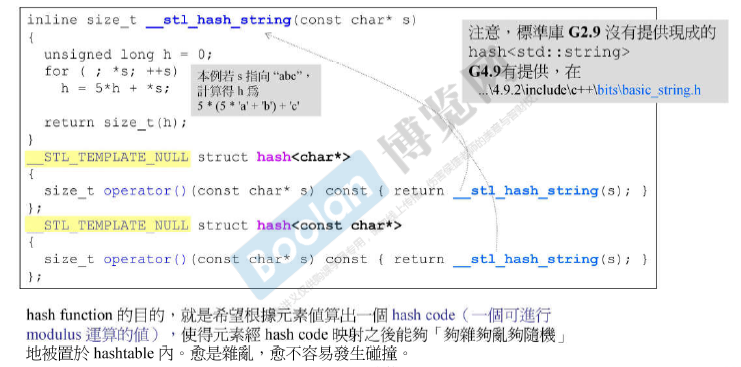
modules运算

hash(key) % n中的hash是 class hashtable中的hashser hash。
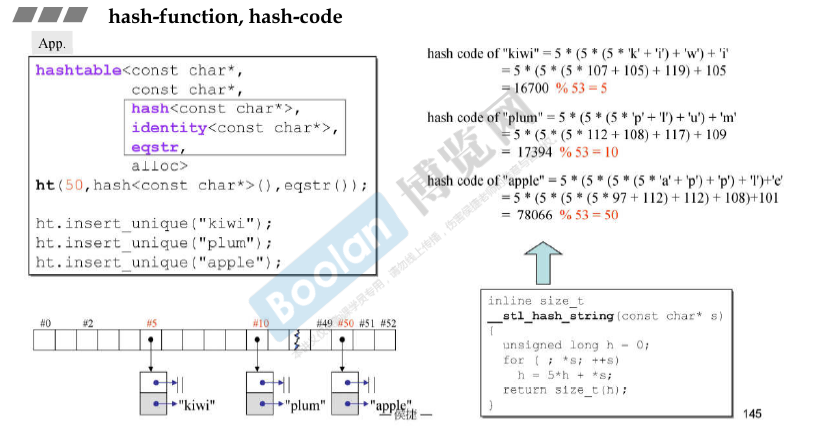
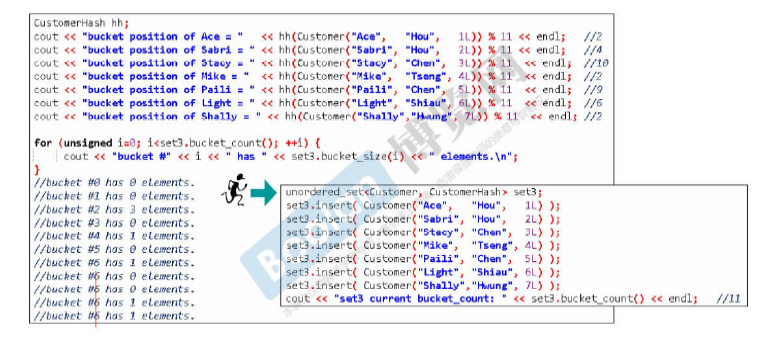
hashtable用例


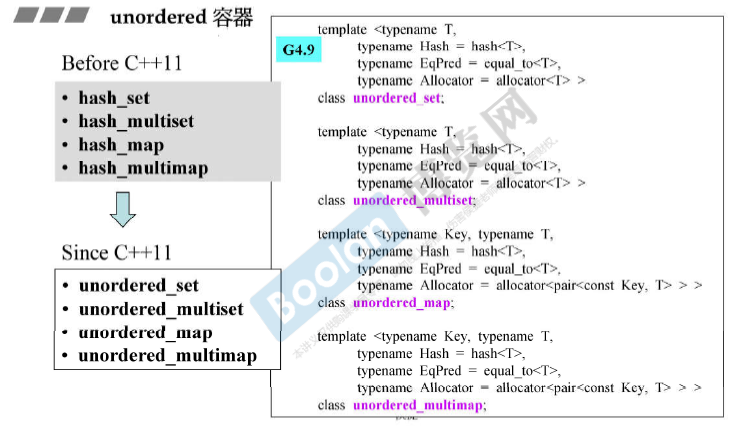
容器unordered_set, unordered_multiset, unordered_map, unordered_multimap
C++11开始改名为 unordered_set, unordered_multiset, unordered_map, unordered_multimap
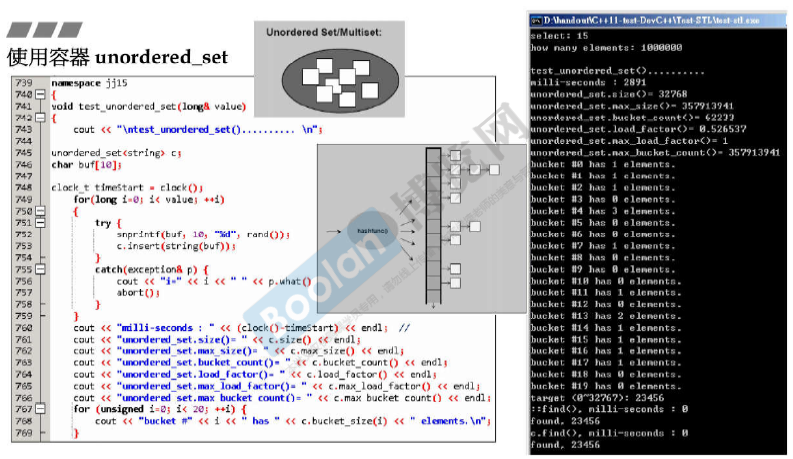
使用unordered_set
第三讲 体系结构与内核分析
C++标准库的算法 是什么?
从语言层面讲:
- 容器Container是个class template;
- 算法Algorithm 是个function template;
- 迭代器Iterator是个class template;
- 仿函数Function是个class template;
- 适配器Adapter是个class template;
- 分配器Allocator是个class template。

迭代器的分类(category)
移动能力的分类:
input_iterator_tagoutput_iterator_tagforward_iterator_tag: forward_listbidirectional_iterator_tag:不能跳random_access_iterator_tag:可以跳


各种容器的iterators的iterator_category
- array => random_access_iterator
- vector => random_access_iterator
- list => bidirectional_iterator
- forward_list => forward_iterator
- deque => random_access_iterator
set, map, multiset, multimap都是以红黑树为底层结构
- set => bidirectional_iterator
- map => bidirectional_iterator
- multiset => bidirectional_iterator
- multimap => bidirectional_iterator
- unordered_set => forward_iterator
- unordered_map => forward_iterator
- unordered_multiset => forward_iterator
- unordered_multimap => forward_iterator
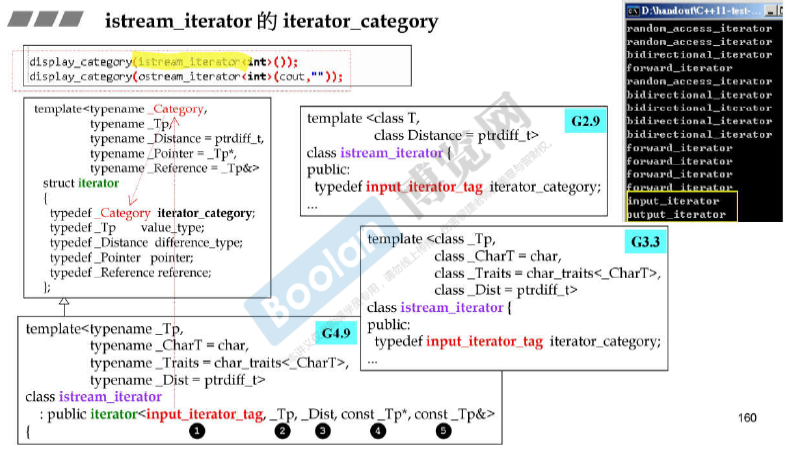
特殊的两个iterator
- istream_iterator => input_iterator
- ostream_iterator => output_iterator
各种容器的iterators的iterator_category的typeid
可以将typeid()视作C++的一种操作符,获得一个对象, typeid().name()获得对象的名称。
返回值由实现所定义,实际输出取决于库的实现(但具体哪种iterator是相同的)。
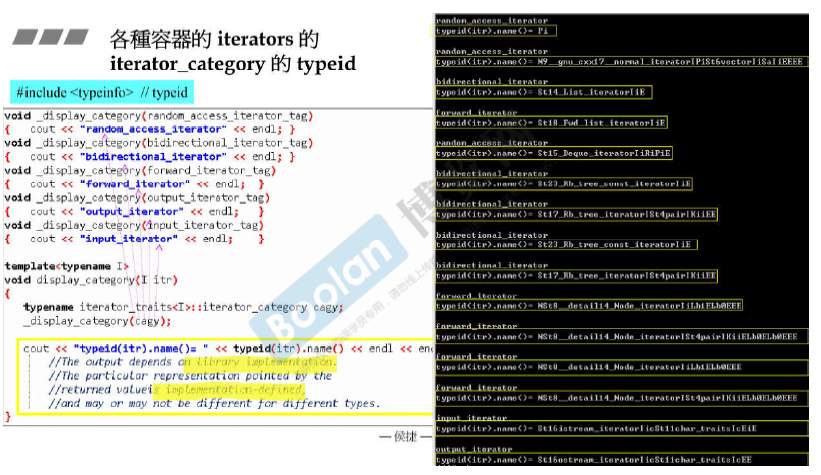
虽然G2.9, G3.3, G4.9每个版本的具体实现不太相同,但是不影响接口的使用(接口一样)。比如 其模板参数都只需要传入一个参数,其他的都有默认值。

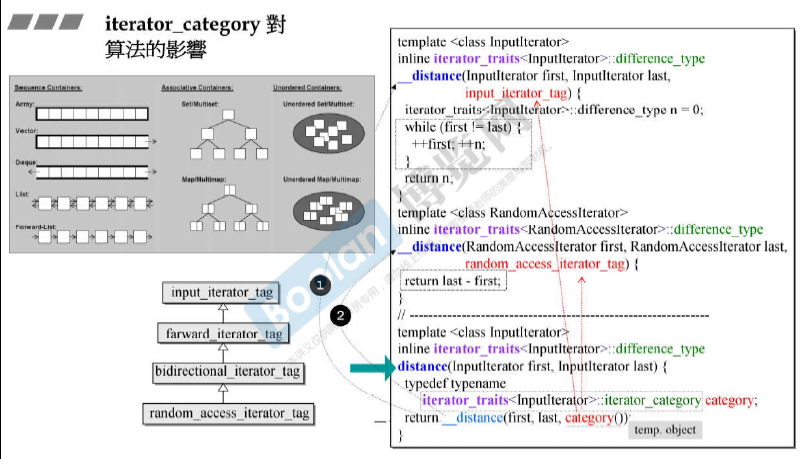
iterator_category对算法的影响
distance() 这个函数模板用于 求两个iterator直接的距离。
- 如果是连续空间(random_access_iterator_tag表示),则调用__distance(RandomAccessIterator first, RandomAccessIterator last, random_access_iterator_tag) 直接对两个iterator做减法;
- 如果是 非连续空间(input_iterator_tag表示),则调用__distance(InputIterator first, InputIterator last, input_iterator_tag),遍历iterator并计数返回。
第一种的效率更高。
distance()的返回类型是 iterator_traits<InputIterator>::difference_type是考虑到了不同情况下返回类型可能不同。
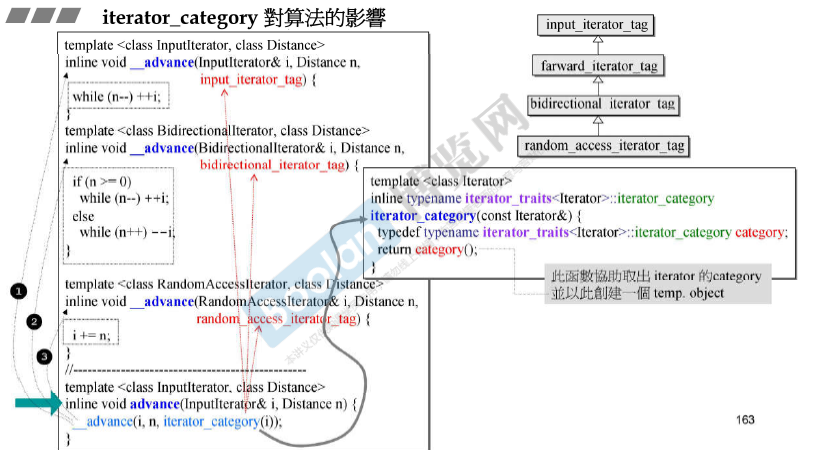
__advance()
- 可以跳,则调用 __advance(RandomAccessIterator& i, Distance n, random_access_iterator_tag)
- 双向,则调用__advance(BidirectionalIterator& i, Distance n, bidirectional_iterator_tag)
- 否则 调用__advance(InputIterator& i, Distance n, input_iterator_tag)。
iterator_category()是一个辅助函数,功能与前面的iterator_traits<InputIterator>::iterator_category相同。
iterator_category和type traits对算法的影响
Type Traits在第四讲。
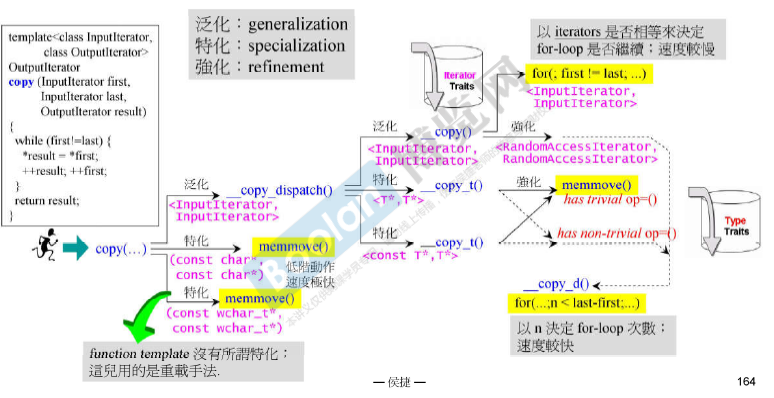
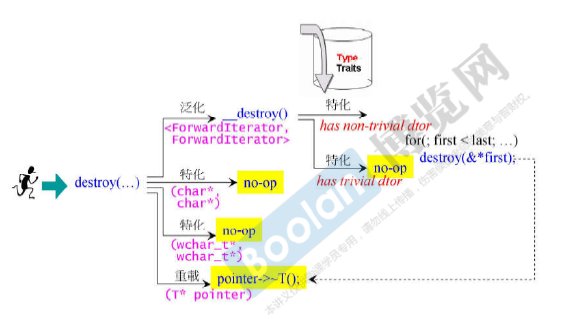
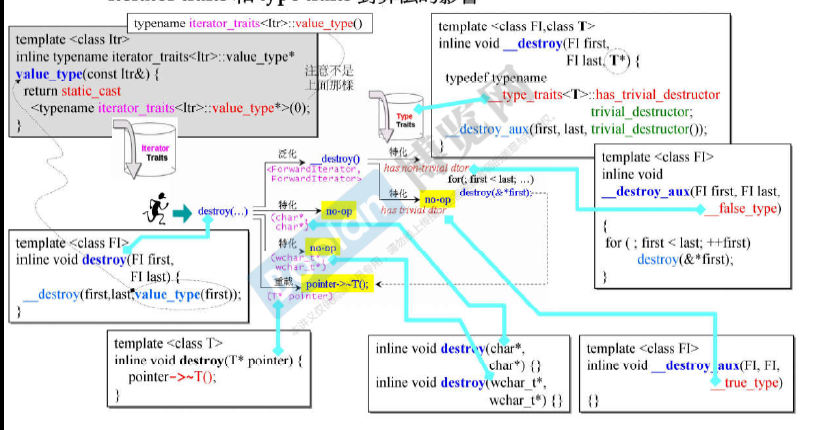
destroy()的源代码:
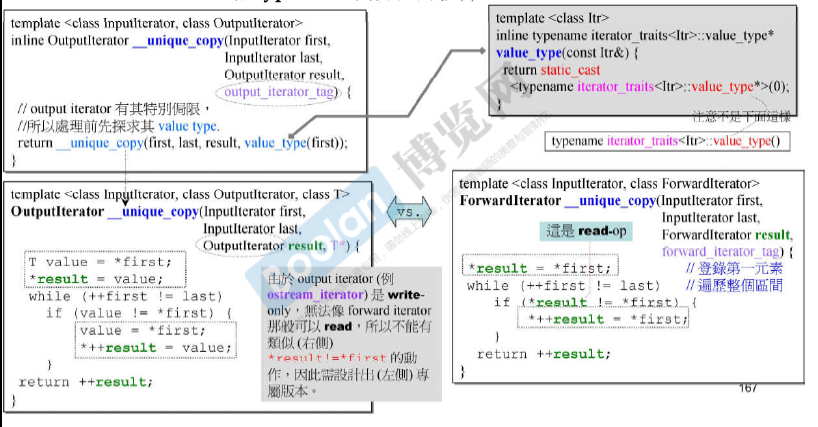
output_iterator(比如 ostream_iterator)是 write-only(只可写的),无法像forward iterator那样可以 read,因此不能有类似(右侧)*result != *first的动作,因此设计出(左侧)的版本。
算法源码中对 iterator_category的“暗示”
模板参数类的命名提示 开发者需要传入的iterator需要满足该类型,否则后面代码可能会编译不通过。

算法源代码剖析(11个例子)
先前示例中出现的算法:

1. 算法accumulate
接受三个参数,first和last迭代器,初始值init
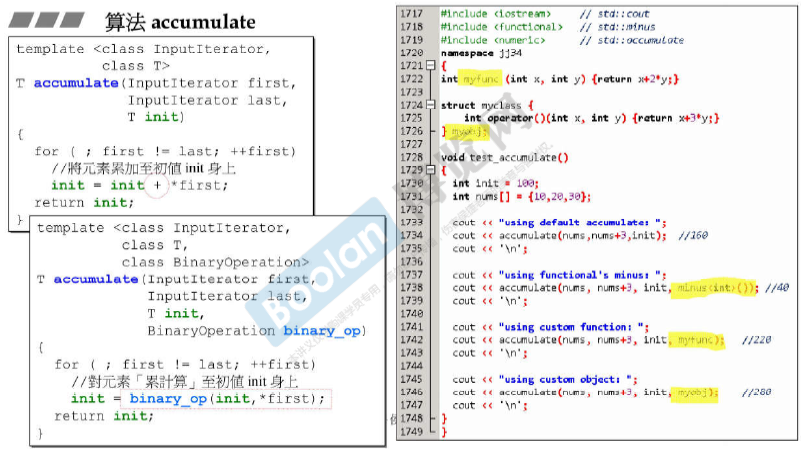
2. 算法for_each
接受三个参数,first和last迭代器,函数f
C++11开始
1for(decl : coll) { statement}

3. 算法replace, replace_if, replace_copy

4. 算法count, count_if
左边是全局函数,右边是容器的成员函数。

5. 算法find,find_if

6.算法sort

6.算法binary_search
必须先排序后再进行二分。

仿函数functors
仿函数只为算法服务。 Algorithm(Iterator itr1, Iterator itr2, Cmp comp)里的Cmp即为仿函数类。
- 算术类
- 逻辑运算类
- 相对关系类

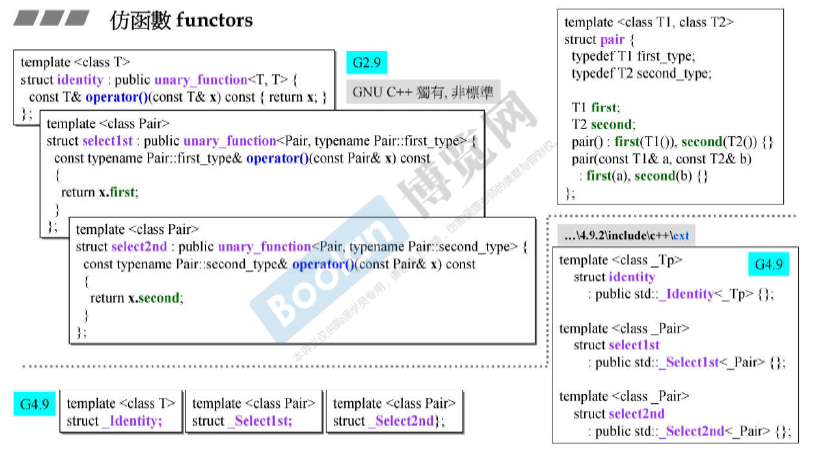
算法sort()的Cmp可以是 函数myfunc,也可以是函数对象myobj。 传入的less<int>()和greater<int>()表示一个对象。

仿函数functors的可适配(adaptable)条件

less继承了binary_function中的三个typedef。
适配器Adapters
想要A拥有B的功能,有两种方法:继承 或 复合(composition,拥有)。
Adapters中使用 复合的方法。 Functor Adapters内含了Functors,其他适配器类似。
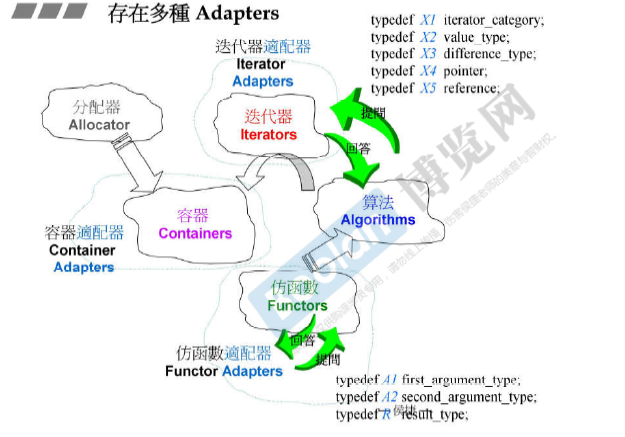
容器适配器stack,queue
如下图:stack和queue都内含了一个deque。

函数适配器binder2nd
typedef typename Operation::second_argument_type arg2_type;
编译过程中不知道Operation是什么, 使用typename保证Operation是一个类型,保证编译能通过。

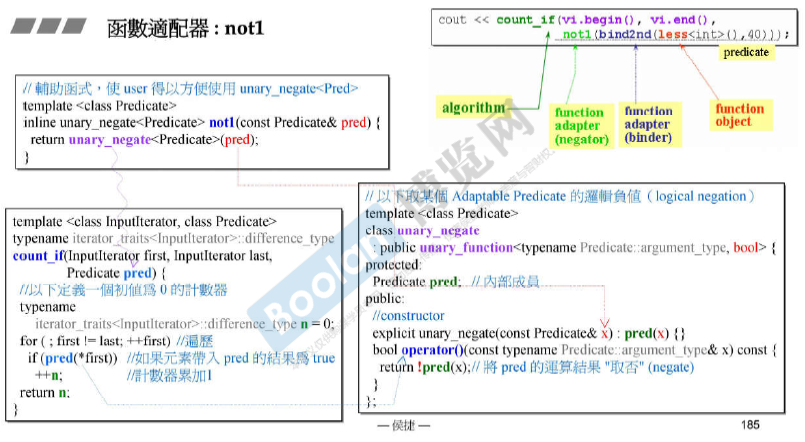
下图中用左侧的 代替 右侧的。

新型适配器bind(Since C++11)
|
|
std::bind 可以绑定:
- functions
- function objects
- member functions, **_1(表示占位符)**必须是某个object地址;
- data_members,_1必须是某个object地址

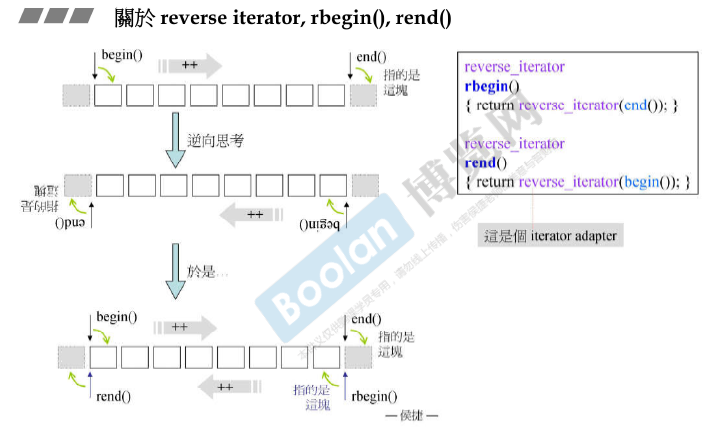
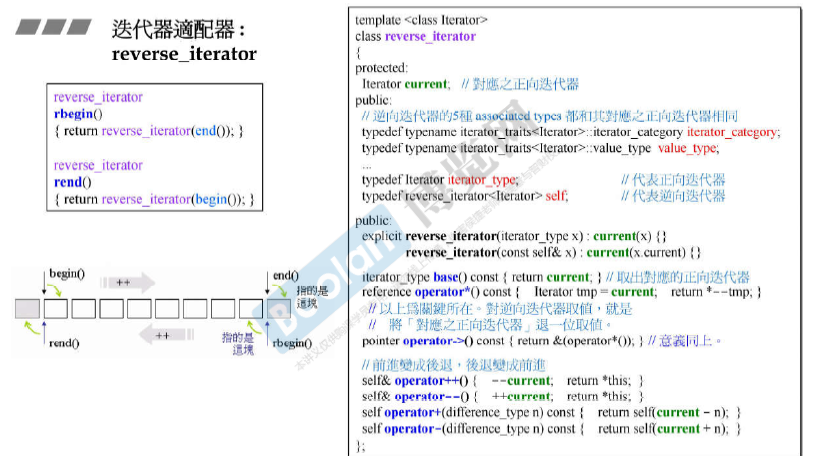
迭代器适配器reverse_iterator
rend()对应的元素取begin()的前一个,rbegin()对应的元素取end()的前一个。
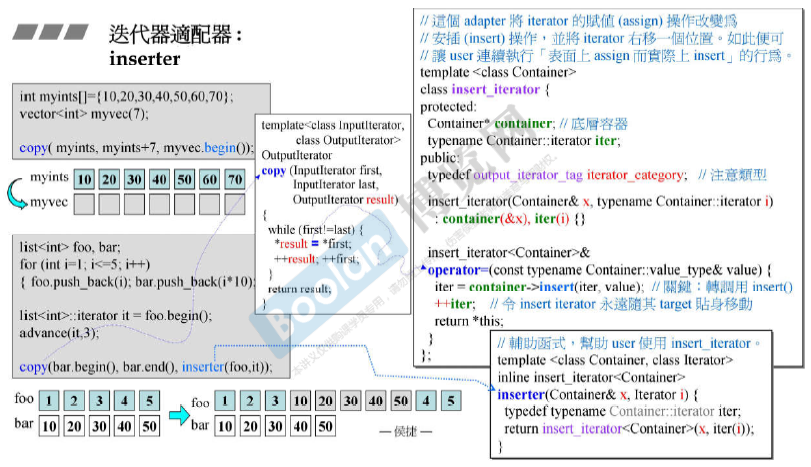
迭代器适配器:inserter
inserter在list中直接插入另一个list(可能插入位置后面的空间不够copy插入的,具体如下例:)
X(未知)适配器
ostream_iterator

istream_iterator
istream_iterator中的 数据成员in_stream使得 下面的例子能够实现 cin»value,然后进行乘法操作的功能。
当创建对象iit时(std::istream_iterator<double> iit(std::cin); ),立即调用了++*this,然后读入了数据value。


使用一个东西,却不明白它的道理,不高明!
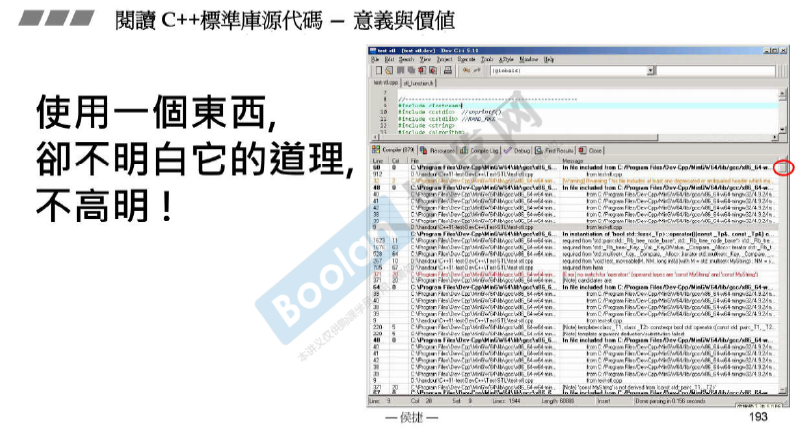
上图是使用模板 写错一行代码(但是报了一堆的错误)的示例。
第四讲 体系结构与内核分析
勿在浮沙筑高台。
一个万用的Hash Function
左边的CustomerHash在unordered_set<Customer, CustomerHash> custset; 中被当作函数调用,调用的是CustomerHash类中的成员函数operator().
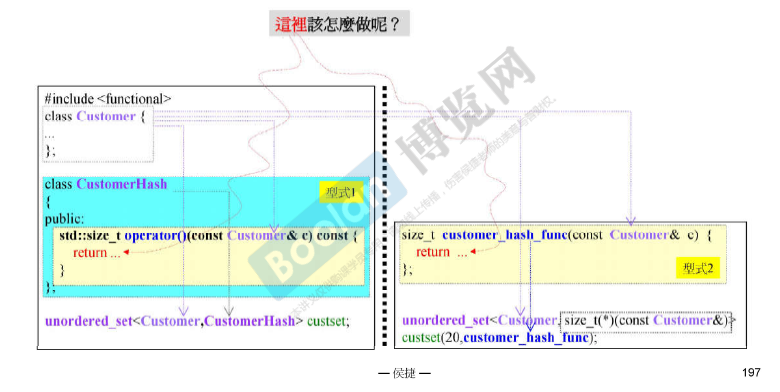
|
|
下图中1,2,3对应的hash_val()函数由于函数参数的不同,所以是不同的函数(重载的一种)。根据具体参数调用不同的函数。
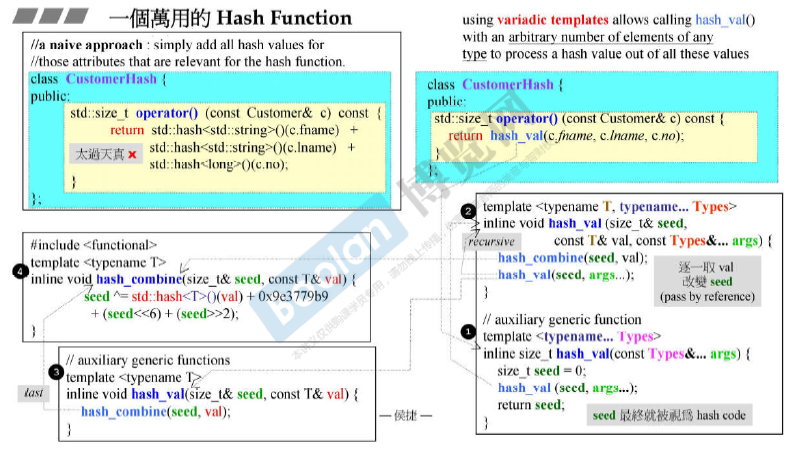
关于0x9e3779b9的来源:

实际实现

以struct hash偏特化形式实现Hash Function


tuple用例

tie(i1, f1, s1) = t3; 将t3的数据取出来赋值
下图中
|
|
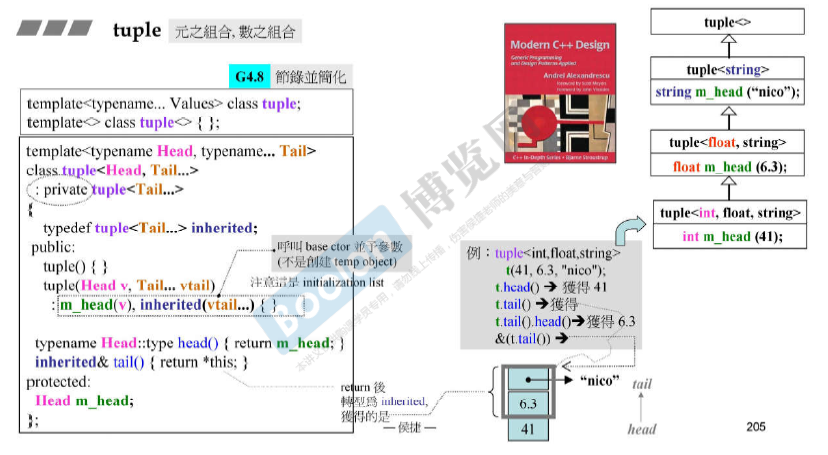
Tuple,元之组合,数之组合
Modern C++ Design
type traits

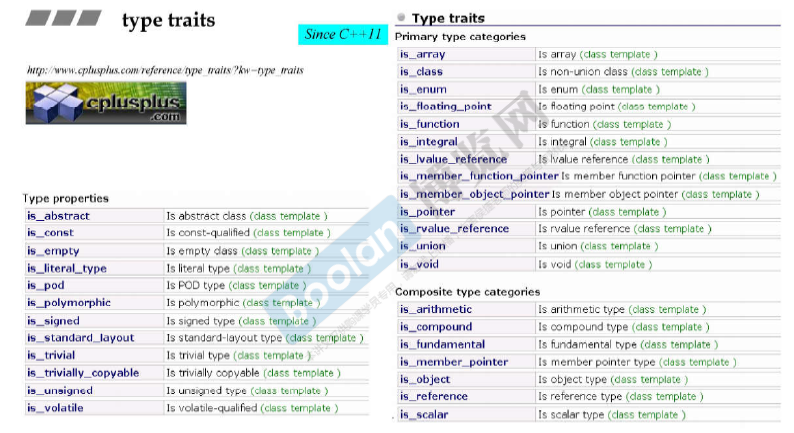


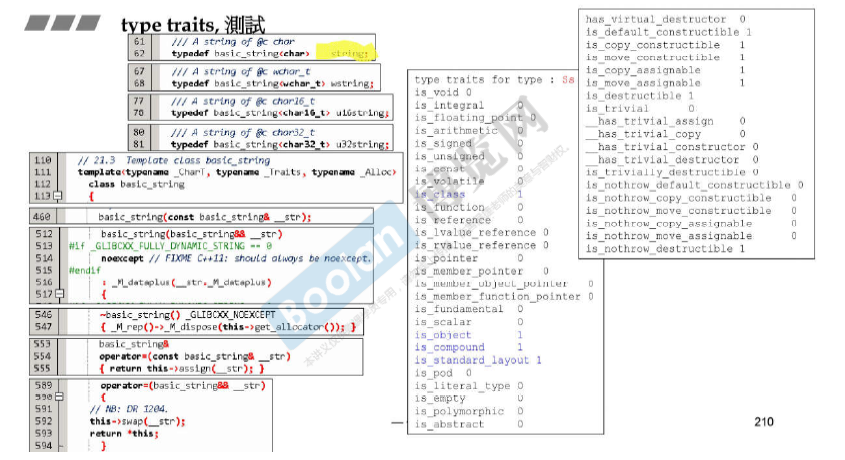


|
|

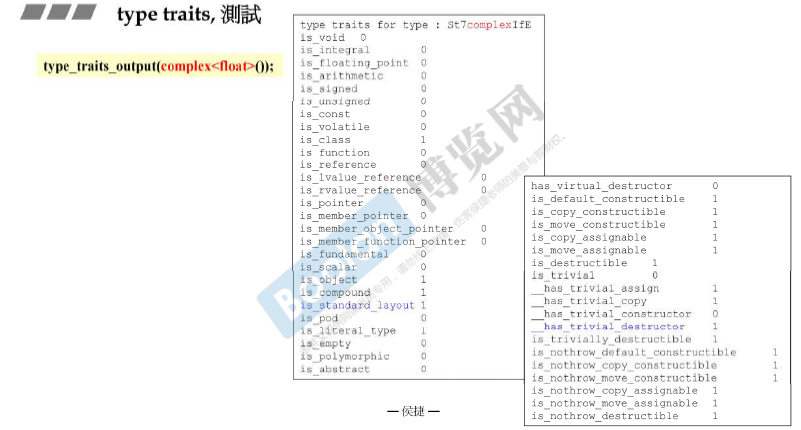
复数只有实部和虚部。 不用写析构函数,默认生成,不重要,所以**__has_trivial_destructor = 1。**

type traits,实现 is_void
特化是泛化的范围缩小。

type traits,实现 is_integral

type traits,实现is_class, is_union, is_enum, is_pod
这些在 C++标准库源代码中没有出现,可能是编译器做的这些事。

type traits,实现is_move_assignable

cout
|
|


moveable元素对各种容器速度效能的影响
速度跟机器实际内存也有关系。
|
|
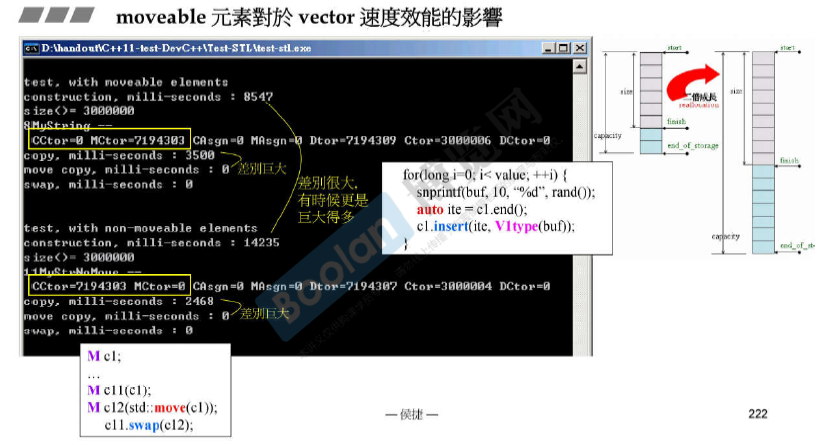
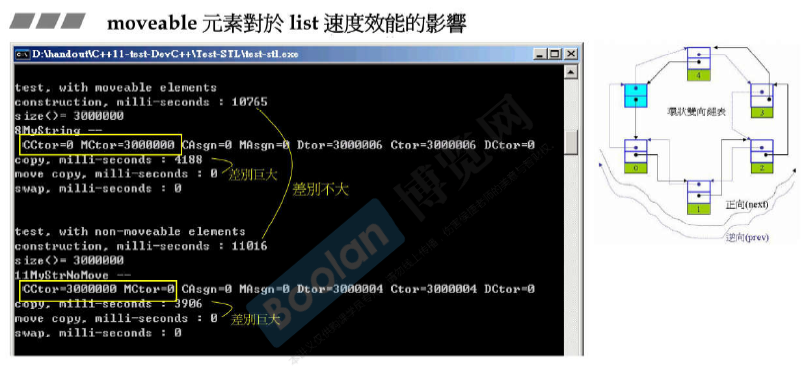
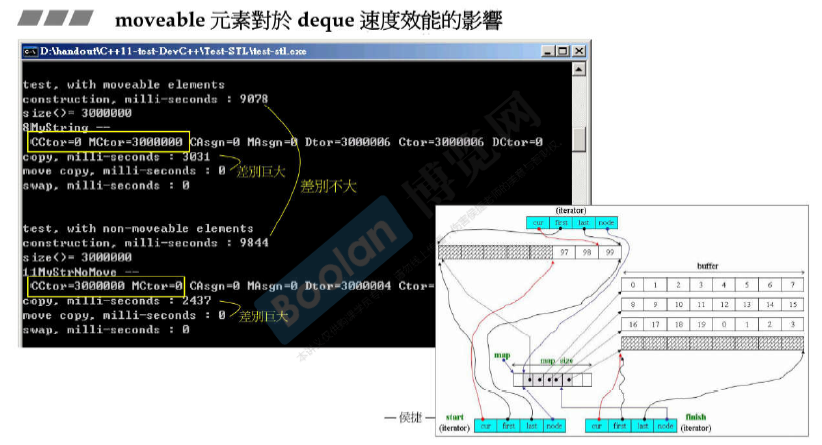
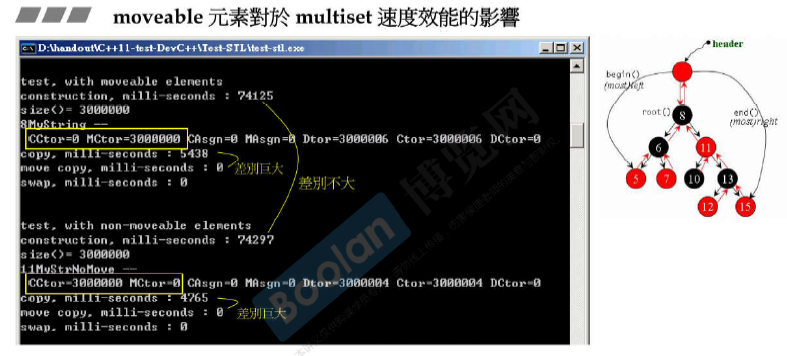
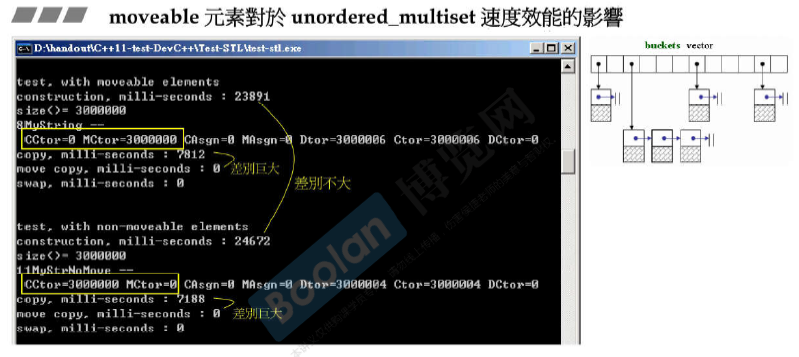
写一个moveable class


move copy浅拷贝,只是将新的指针指向原来的数据。
copy深拷贝,将数据和指针都移动到新的位置。(必须保证原来的不会被用到)
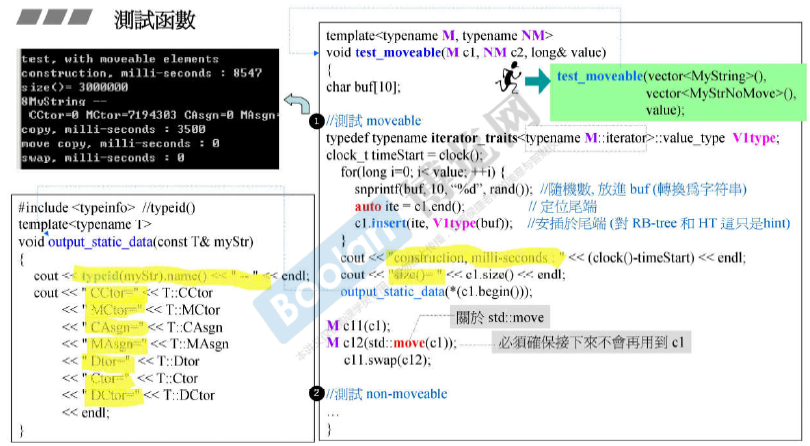
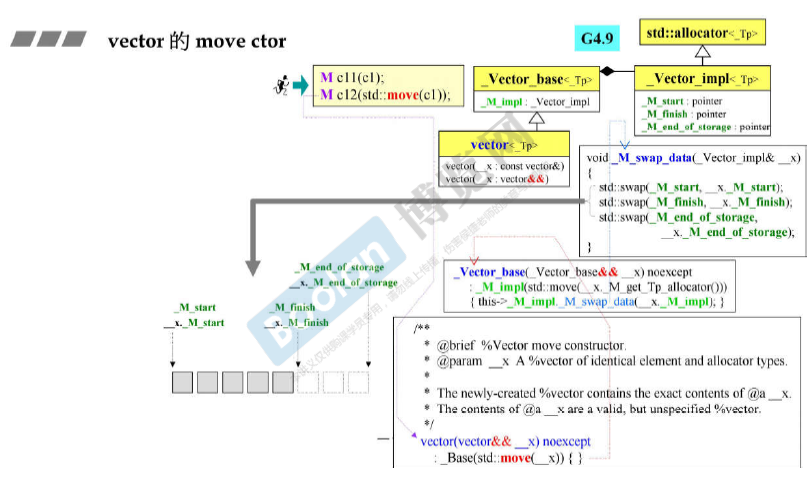
vector本身的拷贝copy ctor是深拷贝。

vector的move ctor是浅拷贝,只是swap三根指针。

参考资料
-
https://www.bilibili.com/video/av714361076/?spm_id_from=333.788.b_765f64657363.2
-
视频代码-GitHub:https://github.com/19PDP/Bilibili-plus
-
STL源码剖析
文章作者 fzhiy
上次更新 2022-03-05