已解决的需求
- 时间顺序排序,与实际日志相符
- kibana根据ip、log筛选日志(对应字段:fileds.server, log.file.path)
- 引入kafka保证 机器宕机后日志不丢失,3个节点组成的集群来实现日志同步,备份
- 同城双活
架构图
ELK Demo采用的架构如下:
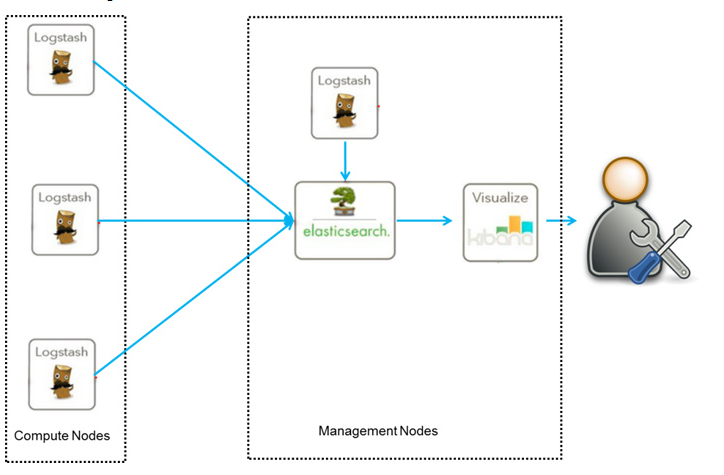
如上图,图中 Logstash 多个的原因是考虑到程序是分布式架构的情况,每台机器都需要部署一个 Logstash,如果确实是单服务器的情况部署一个 Logstash 即可。
优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
改进架构
架构图二:
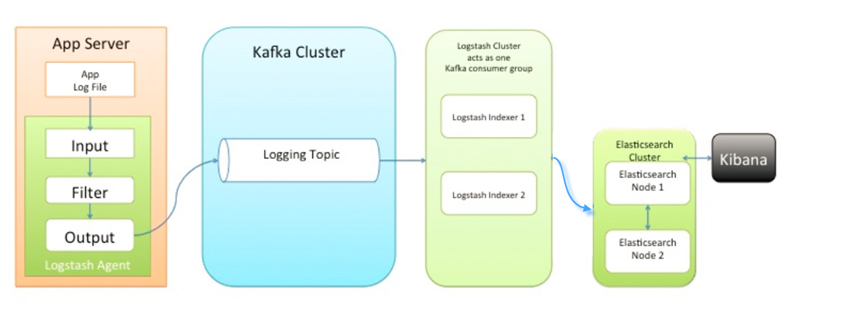
此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
架构图三:
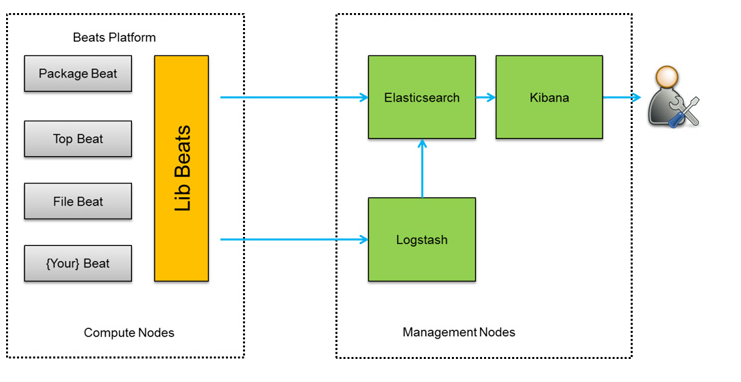
此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
当前架构
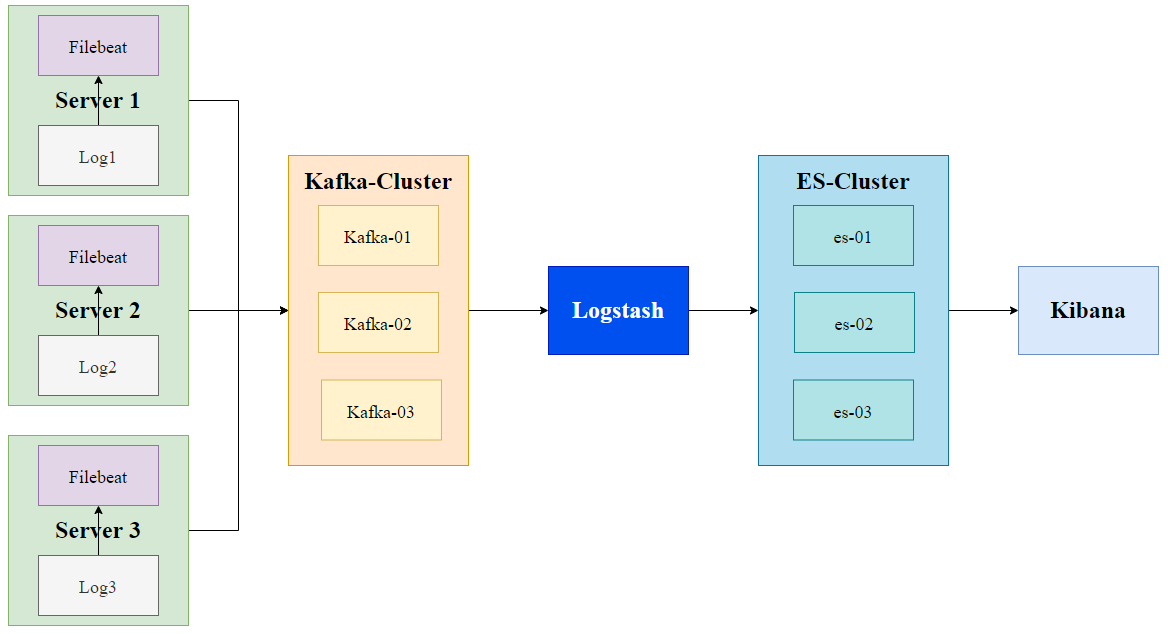
集群节点分布图
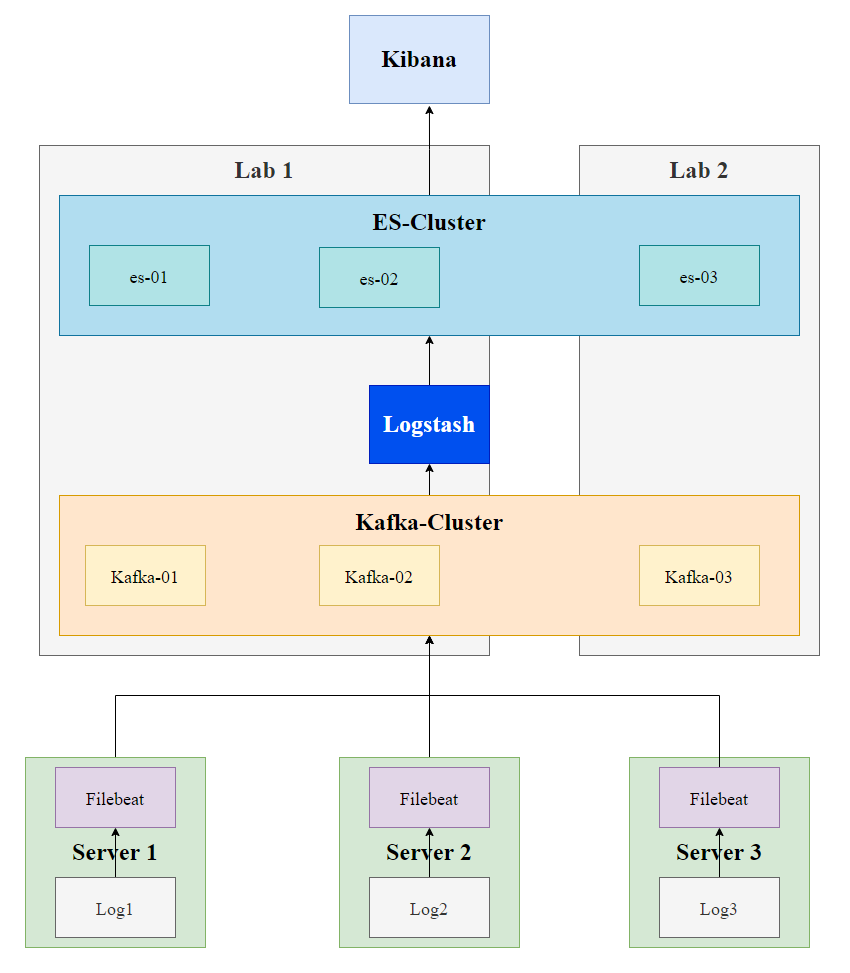
环境说明(Server 1, Server 2, Server 3均是需要日志收集服务的机器)
ELK版本均为7.6.0, Kafka版本为2.5.0。所有机器的操作系统都是CentOS 7。
| host |
vm-name |
hostname |
资源 |
运行服务 |
| 10.240.211.189 |
yufeng-centos7-kafka1 |
kafka1 |
4核8G |
kafka |
| 10.240.211.71 |
yufeng-centos7-kafka2 |
kafka2 |
4核8G |
kafka |
| 10.240.211.76(Lab2 ESXI) |
yufeng-centos7-kafka3 |
kafka3 |
4核8G |
kafka |
| 10.240.211.68 |
yufeng-centos7-dev |
yufeng |
8核24G |
es, logstash, kibana |
| 10.240.210.242 |
yufeng-centos7-dev2 |
dev2 |
4核8G |
es |
| 10.240.210.193(Lab2 ESXI) |
yufeng-centos7-es3 |
es3 |
2核4G |
es |
|
|
|
|
|
| 10.240.211.112 |
|
dbgshell |
|
lxca, filebeat |
| 10.240.210.243 |
|
dbgshell |
|
lxca, filebeat |
正如架构补充部分所说,引入Kafka,利用消息队列机制将filebeat(生产者)从服务器上采集的日志存储下来,然后logstash作为消费者将日志解析并存储到 ElasticSearch中,然后通过 Kibana提供日志可视化、筛选等功能。
此处的Kafka集群由 **三个节点(Lab1 2个节点,Lab2 1个节点)**组成,每个节点是一个broker,能够实现一个节点宕机,其他节点依然能够正常提供服务。而 **这里采取的Lab1 2个节点,Lab2 1个节点(Kafka,ES)**的目的是为了实现 同城双活。
ES双活需要考虑的问题:
- 长距离传输导致的数据传送的延时,以及 网络抖动增加“误选举”的概率?
- 3个节点,当某个节点挂了以后,重新恢复连接时,从leader节点上同步数据时 可能发生的流量风暴?
参考:
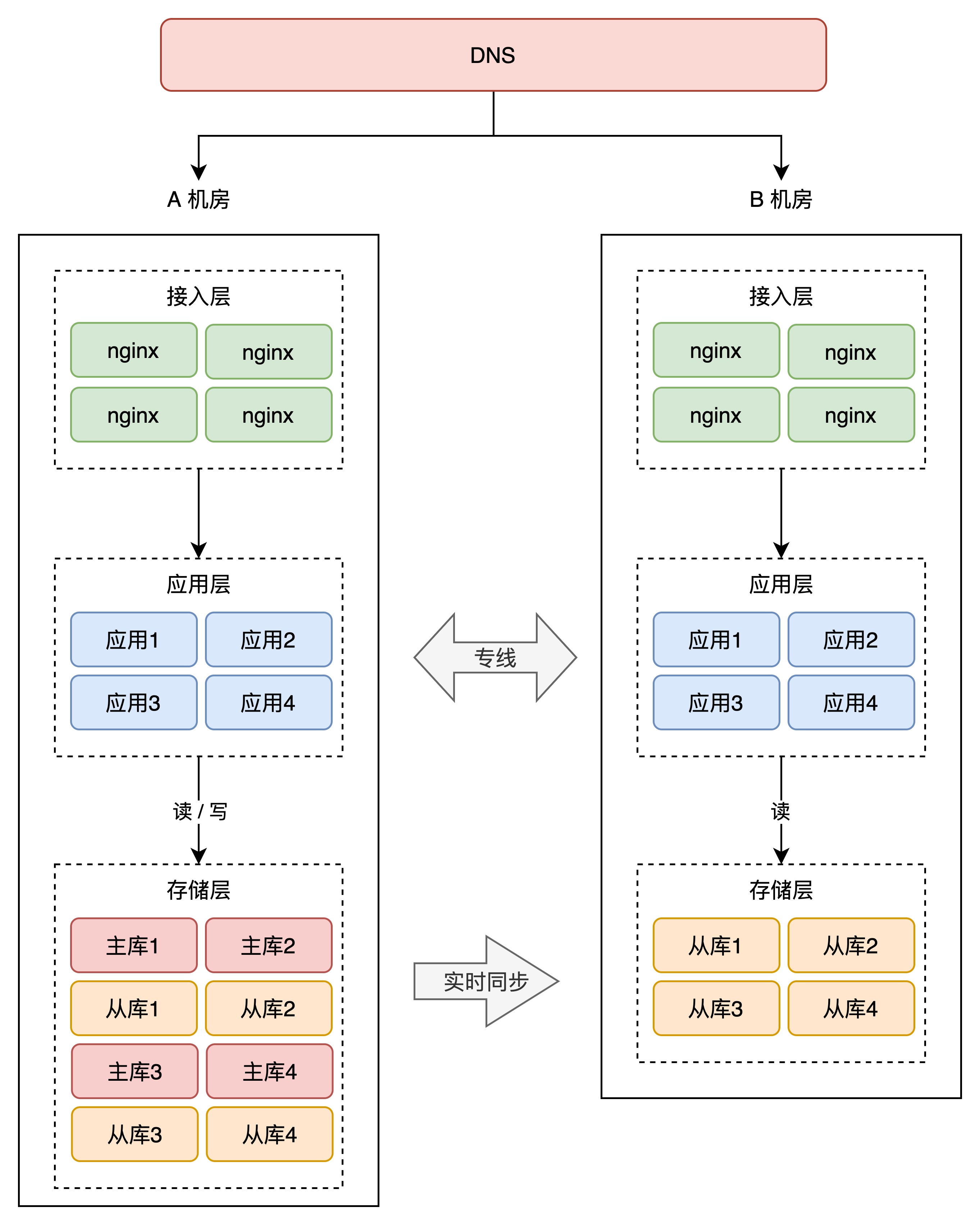
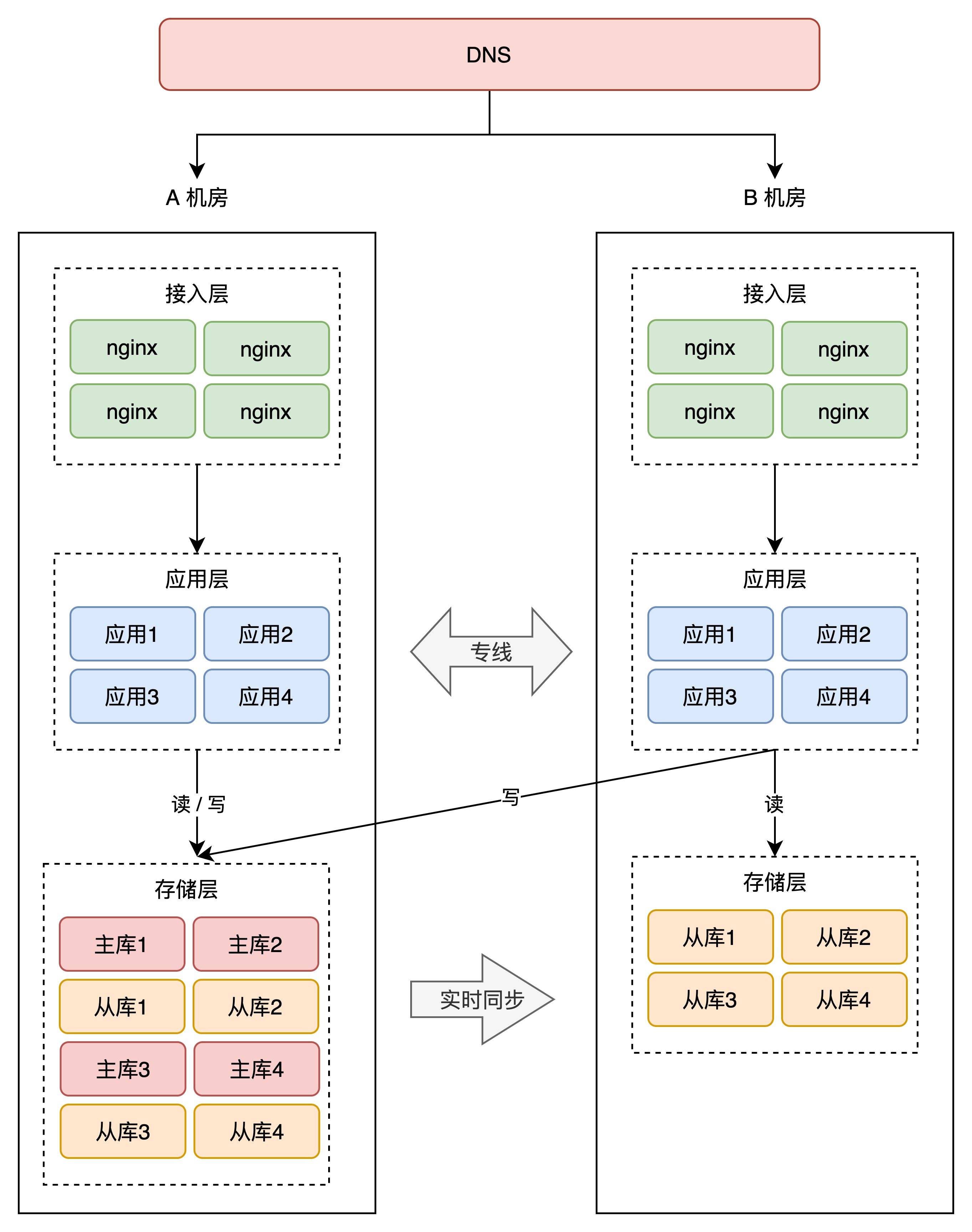
工作流程概述
- 配置jdk
- 根据环境说明中的所运行的软件下载安装软件,并配置
filebeat.yml, logstash配置文件,kafka, es
- 依次启动es集群, kibana, kafka集群,创建topic,启动filebeat,启动logstash
具体配置
Kafka
config/server.properties
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# kafka1
broker.id=0 # 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
listeners=PLAINTEXT://10.240.211.189:9092
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
zookeeper.connect=10.240.211.189:2181,10.240.211.71:2181,10.240.211.76:2181
# kafka2
broker.id=1
listeners=PLAINTEXT://10.240.211.71:9092
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
zookeeper.connect=10.240.211.189:2181,10.240.211.71:2181,10.240.211.76:2181
# kafka3 也一样 就broker.id = 2
broker.id=2
listeners=PLAINTEXT://10.240.211.76:9092
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
zookeeper.connect=10.240.211.189:2181,10.240.211.71:2181,10.240.211.76:2181
|
config/zookeeper.properties
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
dataDir=/tmp/zookeeper
# 客户端连接server的端口,即对外服务端口,默认为2181
clientPort=2181
# 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制
maxClientCnxns=0
admin.enableServer=false
# server列表 2888为选举端口,3888为心跳端口
# 0表示服务器的编号 对应 dataDir 下面的 myid 文件
server.0=10.240.211.189:2888:3888
server.1=10.240.211.71:2888:3888
server.2=10.240.211.76:2888:3888
# ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime
tickTime=2000
# Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,F在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数
initLimit=10
# 在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了。注意:不要把这个参数设置得过大,否则可能会掩盖一些问题
syncLimit=5
|
在上一步 dataDir 指定的目录下,创建 myid 文件。 直接将 kafka 的 broker.id 写入对应即可
启动集群所有节点
1
2
3
4
5
6
7
8
|
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
./bin/kafka-server-start.sh -daemon ./config/server.properties
# 开放端口,
iptables -A INPUT -ptcp --dport 3888 -j ACCEPT
iptables -A INPUT -ptcp --dport 2888 -j ACCEPT
iptables-save #保存
|
创建topic
1
2
3
4
5
6
7
8
|
./bin/kafka-topics.sh --create --bootstrap-server 10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092 --replication-factor 3 --partitions 1 --topic pim2_log
./bin/kafka-topics.sh --create --bootstrap-server 10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092 --replication-factor 3 --partitions 1 --topic lxca2_log
# 查看topic是否正常
./bin/kafka-topics.sh --describe --bootstrap-server 10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092 --topic pim2_log
./bin/kafka-topics.sh --describe --bootstrap-server 10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092 --topic lxca2_log
|
ES
elasticsearch.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
cluster.name: elk-application #ELK的集群名称,名称相同即属于是同一个集群
node.name: node-1 #本机在集群内的节点名称 要在集群中唯一
path.data: /elk/data #数据存放目录
path.logs: /elk/logs #日志保存目录
network.host: 10.240.211.68 #监听的IP地址
http.port: 9200 #服务监听的端口
discovery.seed_hosts: ["10.240.211.68:9300", "10.240.210.242:9300", "10.240.210.193:9300"] # 提供集群中符合主机要求的节点的列表 服务发现种子主机
cluster.initial_master_nodes: ["10.240.211.68", "10.240.210.242", "10.240.210.193"] # 可以成为master节点的机器 初始主节点
#开启 xpack 功能,如果要禁止使用密码,请将以下内容注释,直接启动不需要设置密码
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
|
各节点修改 config/jvm.options 文件的 -Xms4g 和 -Xmx4g 为服务器的内存一半,我的服务器时 8G 内存,所以这里改成了 4G 。当然,这个值最大不要超过 32G 。
生成TLS核身份认证
1
|
bin/elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass ""
|
生成 TLS 和身份验证,将会在config下生成elastic-certificates.p12文件,将此文件传到其他节点的config目录,注意文件权限。
创建 Elasticsearch 集群密码
交互式设置密码,此处密码全部设置为 123456.
1
|
bin/elasticsearch-setup-passwords interactive
|
kibana页面登录账号密码为:elastic/123456
Kibana
config/kibana.yml
1
2
3
4
5
|
server.port: 5601
server.host: "10.240.211.68"
elasticsearch.hosts: ["10.240.211.68:9200"]
elasticsearch.username: "kibana"
elasticsearch.password: "123456"
|
Logstash
lxca_log.conf 处理topic为lxca2_log的日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
input{
kafka {
codec => json
auto_offset_reset => "earliest"
topics => "lxca2_log" # 与kafka topic对应
consumer_threads => 1
bootstrap_servers => "10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092"
}
}
filter {
grok {
match => {"message" => "%{MONTHDAY:day}\.%{MONTH:month}\.%{YEAR:year}\s+%{TIME:time}\s+%{TZ:timezone},\s+\[%{DATA:threadName}\],\s+%{LOGLEVEL:loglevel},\s+%{JAVACLASS:logclass}\:%{WORD:method}\s+%{GREEDYDATA:details}"}
}
mutate {
add_field => {"timestamp" => "%{year}-%{month}-%{day} %{time}"}
}
date {
match => [ "timestamp" , "yyy-MMM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
locale => "en"
timezone => "+00:00"
}
mutate {
remove_field => ["timezone", "timestamp", "day", "month", "year", "time"]
}
}
output{
#if [type] == "lxca-log" {
if [fields][topic] == "lxca2_log" { # 与filebeat.yml对应
elasticsearch{
hosts => ["10.240.211.68:9200","10.240.210.242:9200", "10.240.210.193:9200"]
user => "elastic" # 前面创建的账号密码
password => "123456"
index =>"lxca-%{+YYYY.MM.dd}.log"
}
}
#}
}
|
pim_log.conf 处理topic为pim2_log的日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# pim_log.conf 处理topic为pim2_log的日志
input{
kafka {
codec => json
auto_offset_reset => "earliest"
topics => "pim2_log"
consumer_threads => 1
bootstrap_servers => "10.240.211.189:9092,10.240.211.71:9092,10.240.211.76:9092"
}
}
filter {
grok {
match => {"message" => "%{MONTHDAY:day}\.%{MONTH:month}\.%{YEAR:year}\s+%{TIME:time}\s+%{TZ:timezone},\s+\[%{DATA:threadName}\],\s+%{LOGLEVEL:loglevel},\s+%{JAVACLASS:logclass}\:%{WORD:method}\s+%{GREEDYDATA:details}"}
}
mutate {
add_field => {"timestamp" => "%{year}-%{month}-%{day} %{time}"}
}
date {
match => [ "timestamp" , "yyy-MMM-dd HH:mm:ss.SSS" ]
target => "@timestamp"
#remove_field => ["timezone"]
locale => "en"
timezone => "+00:00"
}
mutate {
remove_field => ["timezone", "timestamp", "day", "month", "year", "time"]
}
}
output{
if [fields][topic] == "pim2_log" {
elasticsearch{
hosts => ["10.240.211.68:9200","10.240.210.242:9200", "10.240.210.193:9200"]
user => "elastic"
password => "123456"
index =>"pim-%{+YYYY.MM.dd}.log"
}
}
}
|
Filebeat
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /opt/lenovo/lxca/data/logs/pim-*.log
#- /opt/cfc/test-filebeat.log
#- /var/log/test-filebeat.log
#- c:\programdata\elasticsearch\logs\*
fields:
topic: pim2_log # 对应于输出到kafka的topic
server: 10.240.211.112 # 这个字段用来区分是哪台机器
- type: log
enabled: true
paths:
- /opt/lenovo/lxca/data/logs/lxca*.log
fields:
topic: lxca2_log
server: 10.240.211.112
output.kafka:
hosts: ["10.240.211.189:9092","10.240.211.71:9092", "10.240.211.76:9092"]
topic: "%{[fields.topic]}" # 输出到kafka对应topic
partition.round_robin: # 开启kafka的partition分区
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 100000000
|
效果
http://10.240.211.68:5601/
登录kibana,elastic/123456
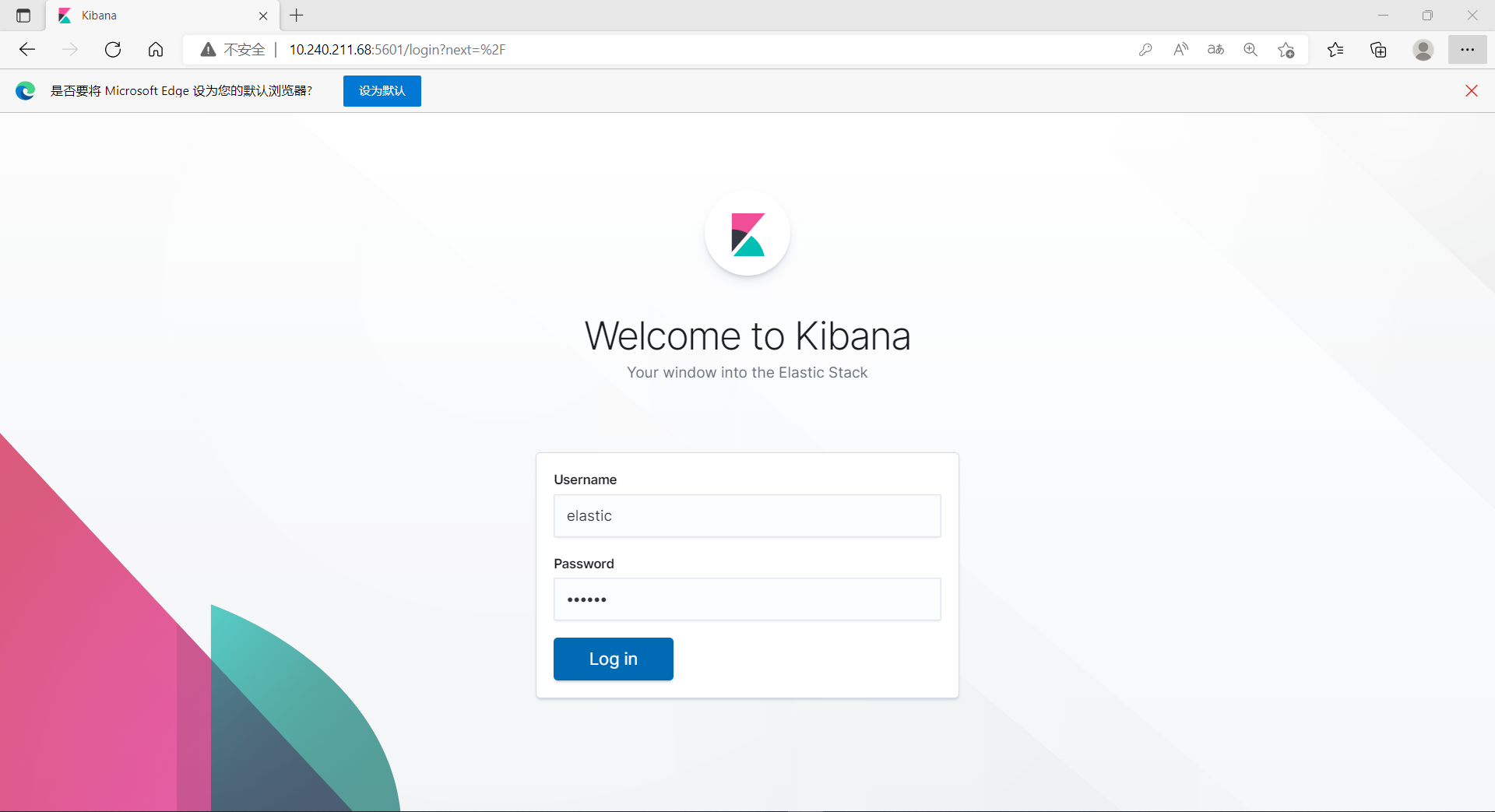
-
按实际日志时间倒序排序;
-
根据server ip区分机器(fields.server),根据log.file.path区分log;
-
实时性,依赖kafka与ELK
-
同城双活(2机房,主机房2个节点,第二机房1个节点)
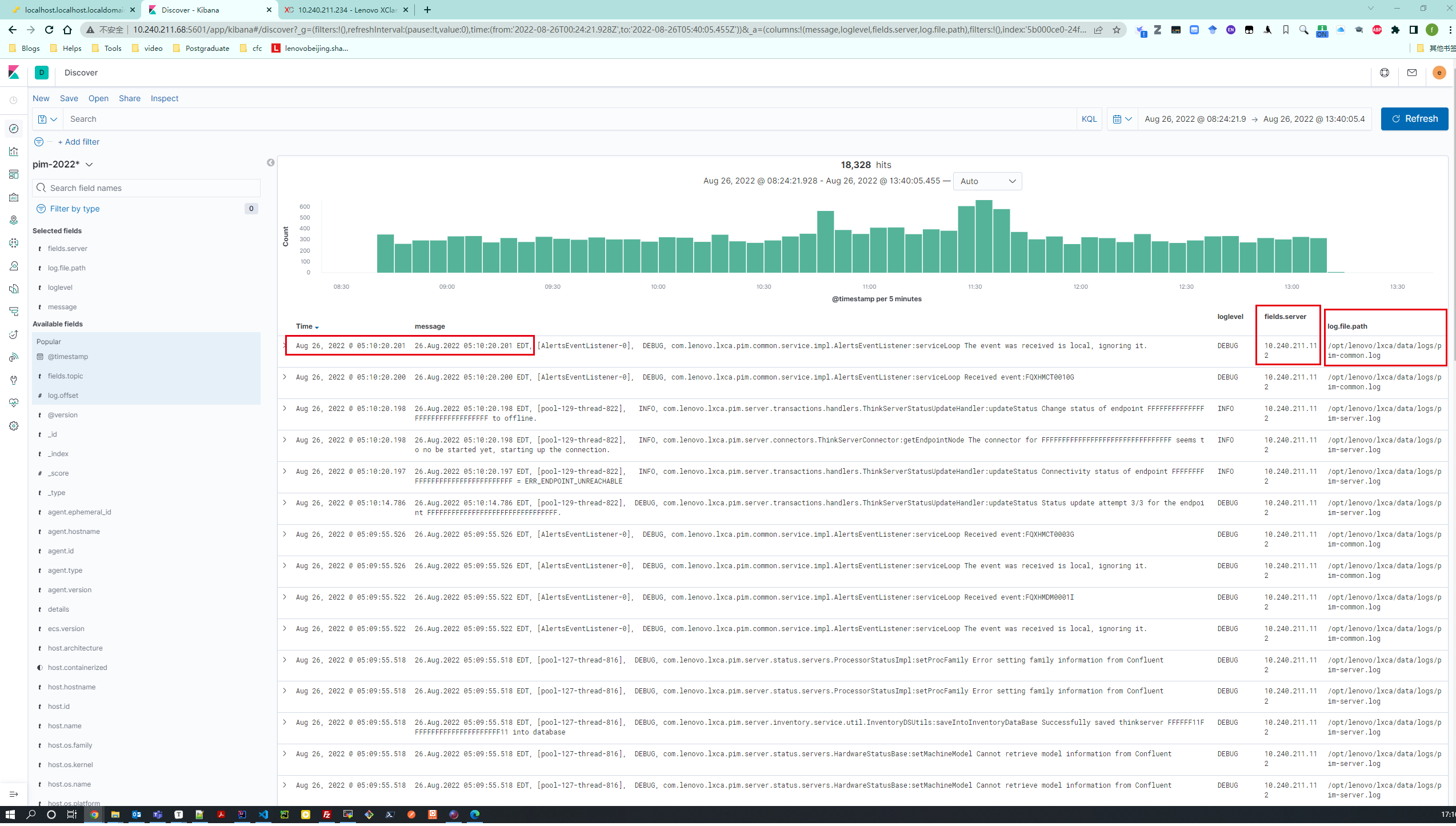
简单使用:创建Index Pattern(可以理解为对es的index进行分组筛选),然后切换到Discover页面根据需要做filter
联调步骤
为了能够节省调试时间,建议大家从数据源头开始做调试,
第一步:查看filebeat的log确认 pim-*.log日志收集是否正常
第二步:查看filebeat的日志文件有没有自身配置错误信息以及转发数据到kafka队列是否正常
此步骤可以在kafka服务器端使用命令行方式消费kafka中的消息进行双边确认
第三步:确认kafka服务本身正常的情况下,查看logstash日志,如果logstash和其它服务共用节点时
需要注意该节点的内存资源是否充足,否则logstash会因为内存不足直接启动失败
第四步:如果前面三步验证都没问题的情况下,elasticsearch里面现在生产了少量的日志数据,但只要有数据存入elasticsearch,就会产生logstash out插件中预定义好的index,此时可能通过elasticsearch 提供的查询API验证elasticsearch是否正常接收了来自logstash转发过来的日志数据
第五步:确认elasticsearch里面有数据以后,就可以使用浏览器打开es_server_ip:5601页面进行创建index模式
如果elasticsearch中没有数据时,是无法在kibana页面中创建index模式
NOTE
-
架构中各节点端口的开放,(9092,9200,9300等),ssh, telnet, 检查防火墙
-
一个logstash实例同时启动多个配置文件,善用 pipelines.yml,利用pipeline可以将各个配置文件相互隔离开来,对于不同的log,我们就可以分别编写一个conf来处理,相互之间不干扰,可扩展性高,不易出错。
pipelines.yml(实现一个logstash两个pipeline的关键)
参考:https://www.elastic.co/guide/en/logstash/7.6/pipeline-to-pipeline.html
1
2
3
4
5
6
7
|
- pipeline.id: pim_log-processing
pipeline.workers: 4
pipeline.batch.size: 256
path.config: "/home/yufeng/logstash-7.6.0/config/conf/pim_log.conf"
- pipeline.id: lxca_log-processing
pipeline.workers: 4
path.config: "/home/yufeng/logstash-7.6.0/config/conf/lxca_log.conf"
|
-
ES用户拥有的可创建文件描述的权限太低 以及 filebeat.yml格式
-
kafka 集群优化
TODO
Service方式启动Filebeat
- filebeat一段时间以后自动关闭,可以通过添加为servie自动重启;
- 解决方法:https://www.jianshu.com/p/6720fe6d24fb
Logstash单调故障问题——利用Kafka Consumer Group实现高可用
参考: https://www.cnblogs.com/caoweixiong/p/12691458.html
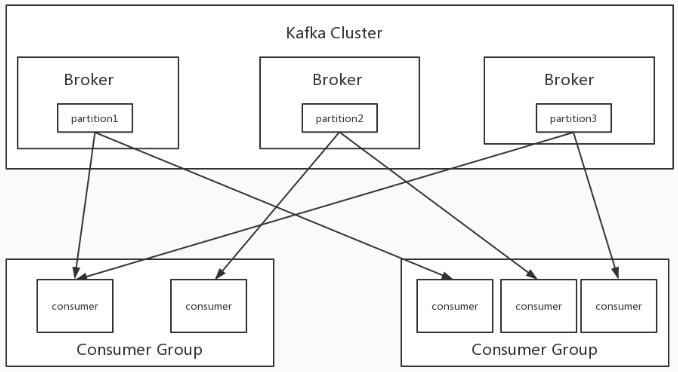
Consumer Group: 是个逻辑上的概念,为一组consumer的集合,同一个topic的数据会广播给不同的group,同一个group中只有一个consumer能拿到这个数据。
也就是说对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个consumer消费,
基于这一点我们只需要启动多个logstsh,并将这些logstash分配在同一个组里边就可以实现logstash的高可用了。
Kafka Partition数目的确定?
如果partition少的话,某些消费者无法消费数据,那么,Topic为什么要设置多个Partition呢,这是因为kafka是基于文件存储的,通过配置多个partition可以将消息内容分散存储到多个broker上,这样可以避免文件尺寸达到单机磁盘的上限。同时,将一个topic切分成任意多个partitions,可以保证消息存储、消息消费的效率,因为越多的partitions可以容纳更多的consumer,可有效提升Kafka的吞吐率。因此,将Topic切分成多个partitions的好处是可以将大量的消息分成多批数据同时写到不同节点上,将写请求分担负载到各个集群节点。
Topic为什么要设置多个Partition呢
- 可有效提升Kafka的吞吐率
- 写请求分担负载到各个集群节点
Log topic的划分?(颗粒度)
项目log的格式 grok正则化解析式编写?
每个log文件的(Exception)异常情况处理,需要根据loglevel级别划分,并编写对应的grok解析式。
根据request api找到对应的response
