Multi-Agent Reinforcement Learning基本概念&三种架构

文章目录
参考内容在References写出,仅作为个人学习笔记,如有错误欢迎指出。
References的一本偏向数学推理的DRL新书即将上线?安排上
Multi-Agent Reinforcement Learning基本概念(1/2)
Settings
-
Fully cooperative 相互配合 e.g. 工业机器人
-
Fully competitive 一方的收益是另一方的损失(捕猎者和猎物),如 零和博弈,双方获得的奖励总和等于0
-
Mixed Cooperative % competitive e.g. 足球机器人 同队伍的机器人与不同队伍的机器人分别是合作与竞争关系
-
Self-interested 利己主义,即 每个agent只想要最大化自身利益 如 股票和期货的自动交易系统
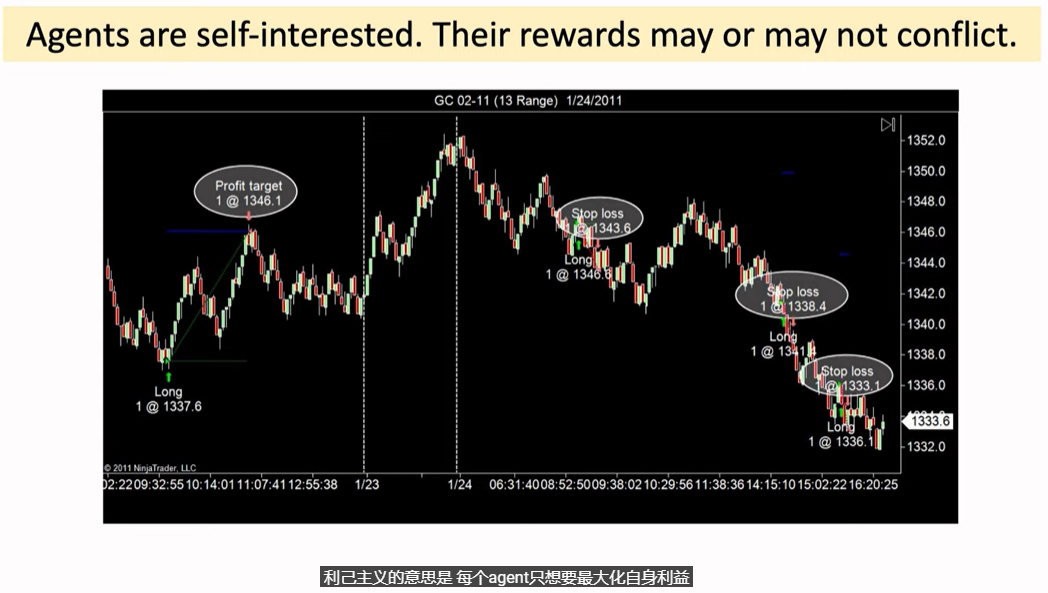

Terminologies
-
State,Action,State Transition (agent之间会相互影响,而非独立)

-
Rewards
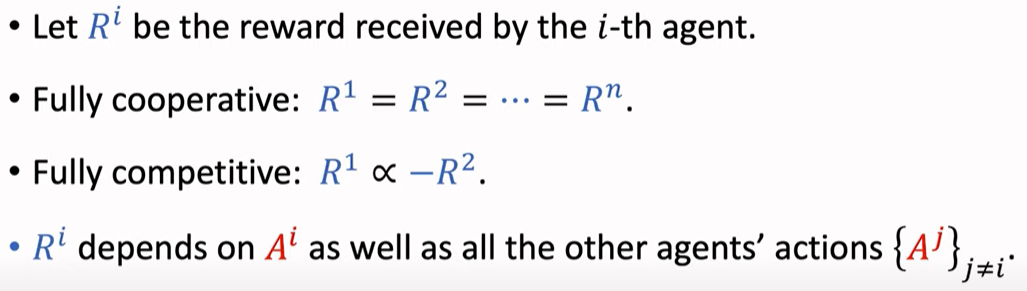
-
Returns

-
Policy Network

-
Uncertainty in the Return

-
State-Value Function

动作是随机的,与$\theta^j$相关,因此$V^i$依赖于所有的$\theta^1,…,\theta^n$

Convergence
-
Single-Agent Policy Learning

-
Multi-Agent Policy Learning
Nash Equilibrium 纳什均衡

-
Difficulty of MARL
Single-Agent Policy Gradient for MARL
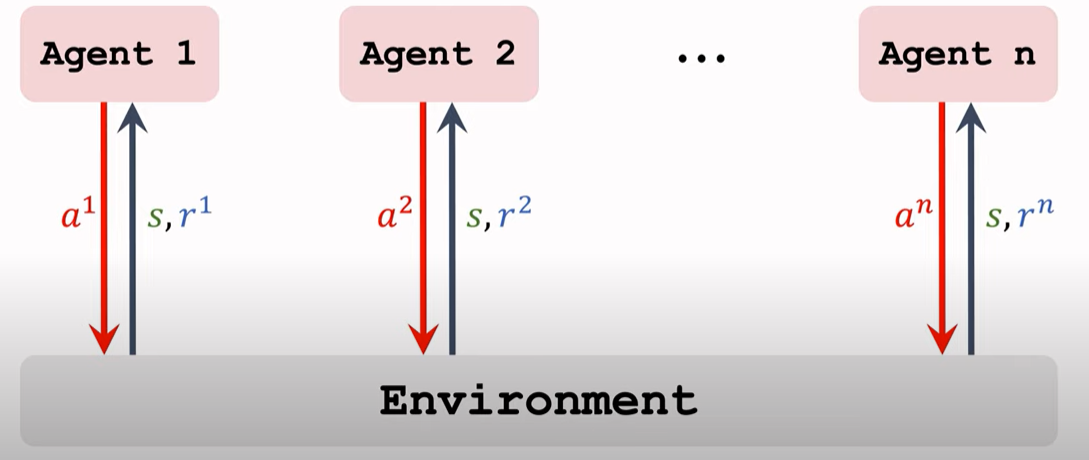

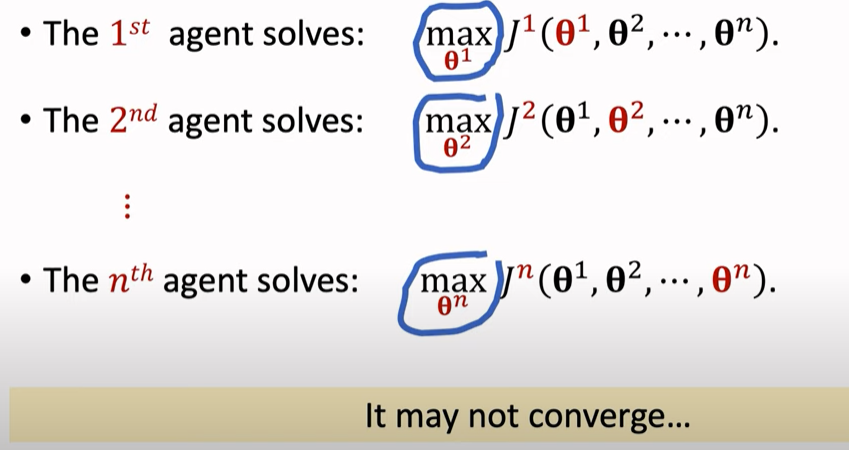

用single-agent policy来做MARL的问题在于:当一个智能体达到最优策略时,另一个智能体继续调整$\theta$,其他的智能体的目标函数都会改变,因此他们也将改变 自己的策略。 即 **MARL的最优策略依赖于所有的$\theta^i,i=1,…,n$ **
Summary
- MARL 只有所有的agents之间相互独立时,才能将single-agent RL方法用于MARL

-
Setting of MARL 四种设置
-
Convergence

对于single-agent System,目标函数不再增长时 收敛;对于multi-agent System,纳什均衡 表示收敛
Multi-Agent Reinforcement Learning三种架构(2/2)
Architectures
- 完全去中心化 agents之间不通信
- 完全中心化 (可理解为 “定于一尊“) 中央控制器为所有的agents做决策
- 中心化训练、去中心化执行 (训练过程使用中央控制器,训练后不使用中央控制器,每个agent根据自己的观测用自己的策略网络做决策)

Partial Observations (MARL的假设)

Fully Decentralized Training

Single-Agent RL 架构图(来自基本概念章节)
通过上面两张图发现 完全去中心化架构的本质是Single-Agent RL 而不是MARL
==Fully Decentralized Actor-Critic Method==

Fully Centralized
Centralized Training

Centralized Execution
中心化执行的时候, 输入是$o^1,…,o^n$ ,策略由中央控制器来做,因为做决策需要知道所有的观测o, 一个agent只知道自己的观测o,而不知道其他的观测。
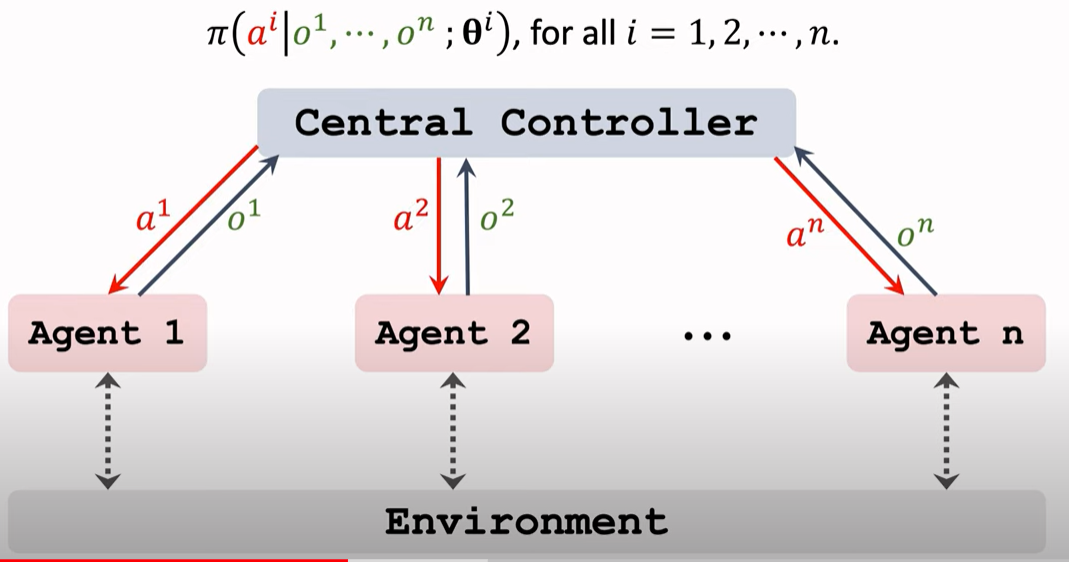
Centralized Actor-Critic Mehod


中心化架构的好处是 中央知道所有的观测o 可以帮助更好的决策。缺点是执行缓慢,具体如下
Shortcomming:Slow during Execution

Centralized Training with Decentralized Execution

Centralized Training



Decentralized Execution

Parameter Sharing?

网络之间是否要共享参数呢?
根据具体场景来,比如 足球机器人比赛,agents是不可交换的(理解为负责的任务不同),所以不能共享参数。无人车由同样的网络控制,所以参数可以共享。
Summary
-
Fully Decentralized

-
Fully Centralized

-
Centralized Training with Decentralized Execution

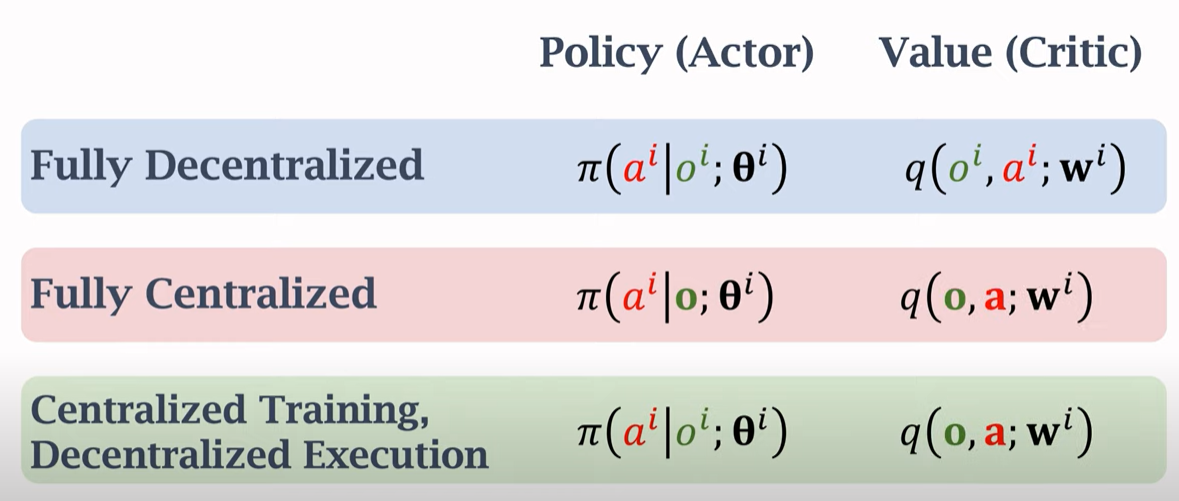
三种架构的对比
References
文章作者 fzhiy
上次更新 2021-02-22