[PaperNotes]2019.A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection

文章目录
A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection
文章地址:https://arxiv.org/abs/1907.09693
作者:Qinbin Li, Zeyi Wen, Zhaomin Wu, Sixu Hu, Naibo Wang, Bingsheng He
发表:arXiv
截止当前(2020.12.19)引用次数:35
Zotero链接: 从我的文库打开
| 标签1 | 标签2 | 标签3 | 标签4 |
|---|---|---|---|
| Federated Learning Systems | Survey |
[toc]
本文笔记总体结构同原文,部分省略,仅保留重点。
Conclusion
本文受以前的联邦系统启发,文中展示了在实用FLSs设计中heterogeneity和autonomy是两个重要因素。从六个方面对FLSs做了全面的分类,及对所属研究调查和概述。在现存的FLSs之间对其特点和设计做了对比。给出了FLSs设计指导,案例研究以及主流的开源FLSs并对它们进行简单分析,为研究者选择使用提供参考。进一步的指出FL的机会,从benchmarks到新型平台(如blockchain)的整合。
Introduction
从系统的角度对现有的Federated Learning Systems进行调查。
- 与传统的federated systems相比,FLSs的定义
- 分析FLSs的系统成分,包含参与方(parties)、管理者(manager)和计算-通信(computation-communication)框架。
- FLSs的6种分类
- data distribution
- machine learning model
- privacy mechanism
- communication architecture
- scale of federation
- motivation of federation
- 基于以上的这些,系统的总结现存的用于指导FLSs设计的研究
- 提出未来工作的研究方向使得FL更加实用和强大
Related Survey
-
Yang et al.【197】的一份重要survey介绍了FL的基础和概念,进一步地提出了全面的安全的FL框架。
Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2):12, 2019.
-
WeBank【187】发表的白皮书v2.0介绍了FL的背景和相关工作,重点呈现了发展路线图,包括建立本地和全局标准、建立用户案例和形成工业数据联盟。这篇文章目标用户是相对少数的群体—尤其是企业数据拥有者。
China” ”WeBank, Shenzhen. Federated learning white paper v1.0. In https://www.fedai.org/static/flwp-en.pdf, 2018.
-
Lim et al.【109】对mobile edge computing的FL综述。
Wei Yang Bryan Lim, Nguyen Cong Luong, Dinh Thai Hoang, Yutao Jiao, Ying-Chang Liang, Qiang Yang, Dusit Niyato, and Chunyan Miao. Federated learning in mobile edge networks: A comprehensive survey, 2019.
-
Li at el.【105】总结了在大量的移动网络和边缘设备环境中FL的挑战和未来方向。
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Challenges, methods, and future directions, 2019.
-
Kairouz et al.【85】从不同的研究课题对FL的特点和面临的挑战进行了全面的描述。
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aur´elien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977, 2019.
以上主要集中在cross-device FL,其中参与者是大量的移动或物联网设备。
Contribution
本文作者表示,截止本文时,缺乏review现有系统和基础设施以及如何提高人们对创建FL系统的关注的综述(survey)— 类似DL中prosperous system research
- 第一个提出从系统的角度,(包括系统成分、分类、总结、设计以及远景)做一个全面的分析
- 对FLSs在六个不同的方面(data distribution, machine learning model, privacy mechanism, communication architecture, scale of federation, and motivation of federation——FLSs的常见构建模块和系统抽象)的全面的分类
- 根据领域(方便研究者和开发者参考的)总结现存的典型和最前沿的(state-of-the-art)研究
- 介绍一个成功的FLS的设计因素,并全面回顾每个场景的解决方案
- 对未来的FLSs提出了有趣的研究方向和挑战。
An Overview of Federated Learning Systems
Background
略
Definition
略
Compare with Conventional Federated Systems
1990, Federtead Database Systems(FDBSs)。FDBSs:为共同利益而合作的自治数据库的集合。
FDBSs的重要组成部分:自治(autonomy)、异构(heterogeneity)和分布(distribution)
Federated Cloud(FC)的两个基本特点:1)资源迁移(resource migration);2)资源冗余(resource redundancy)。其中,不同资源的调度(the scheduling of different resources)是federated cloud system设计的关键因素。
FLSs与传统的联邦系统的异同点:联邦的概念仍然相同,即共同的和基本的思想是多个独立方的协作(cooperation)。==»FLSs仍然考虑异质和自治特性。
如何在参与方之间分享数据会影响系统的效率;而这些联邦系统在collaboration(协同)和constrains上有不同emphasis。FDBSs侧重分布式数据的管理,FCs侧重资源的调度,FLSs更关注在多个参与方之间的安全计算。FLSs带来了新的挑战,如分布式训练的算法设计和在隐私限制下数据保护。
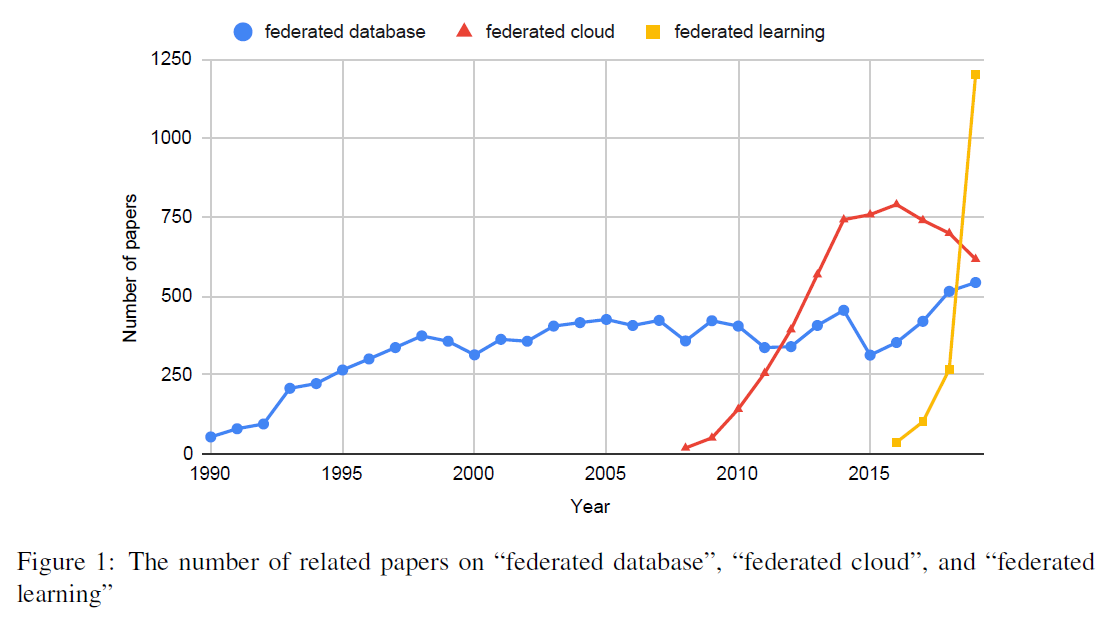
System Components
三个主要组成成分:1)参与方(如client);2)管理者(如server);3)通信-计算框架
Parties
考虑可能影响FLSs设计的参数方属性
- 参与方的硬件容量
- 计算能力和存储
- 手机容量小,参与方无法做大的计算以及训练大的模型 => Wang at el.【184】考虑FL中资源受限的设置
- 参与方的规模和稳定性
- 参与方之间的数据分布 – non-iid data distribution, TL,meta-learning,multi-task learning结合使用
Manager
Blockchain作为一种去中心化方法引入来提高系统可靠性,因为central server无法提供精确的计算结果时,FLS可能产生一个不好(bad)模型。【93】
Problem:很难找到一个可信服务器或参与方作为管理者,尤其是在cross-silo setting中。 => fully-decentralized setting,在这种架构中,all the parties are the manager。【103】提出一种联邦梯度提升决策树框架。
设计一个具有合理通信开销的完全去中心化的FLS是一个挑战
Communication-Computation Framework
FLSs中,在参与方与管理者上进行计算,同时在参与方与管理者之间进行通信。通常计算是用于模型训练,通信是用于交换模型参数。
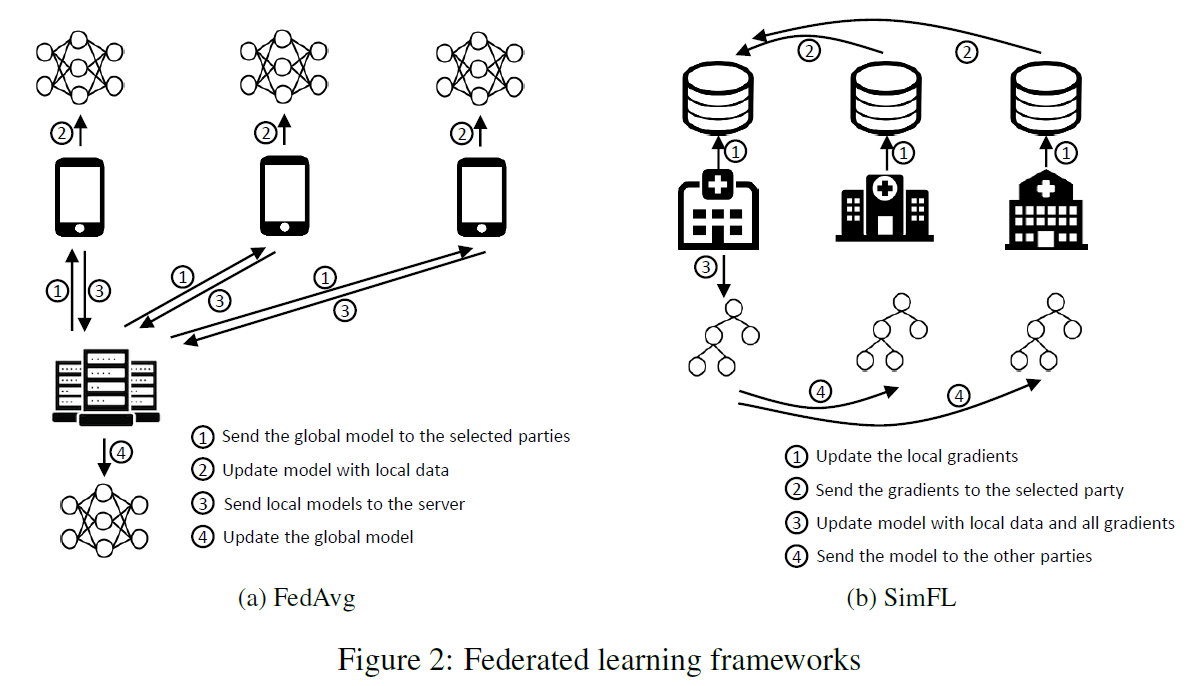
FedAvg - 中心化FL框架, SimFL【105】- 去中心化FL框架
一个重要且具有挑战性的研究方向,即 计算与通过新开销的平衡 【108】在non-IID data上对FedAvg的收敛做了很好的研究
另一个重要方向:除了模型参数外,还需要更多的信息来计算和通信满足隐私保证; 可能的解决方法:SMC =>加解密和通信开销可能是整个FL的瓶颈 ==» 【已经做的工作】研究减少overheads,尤其是通信规模
Taxonomy
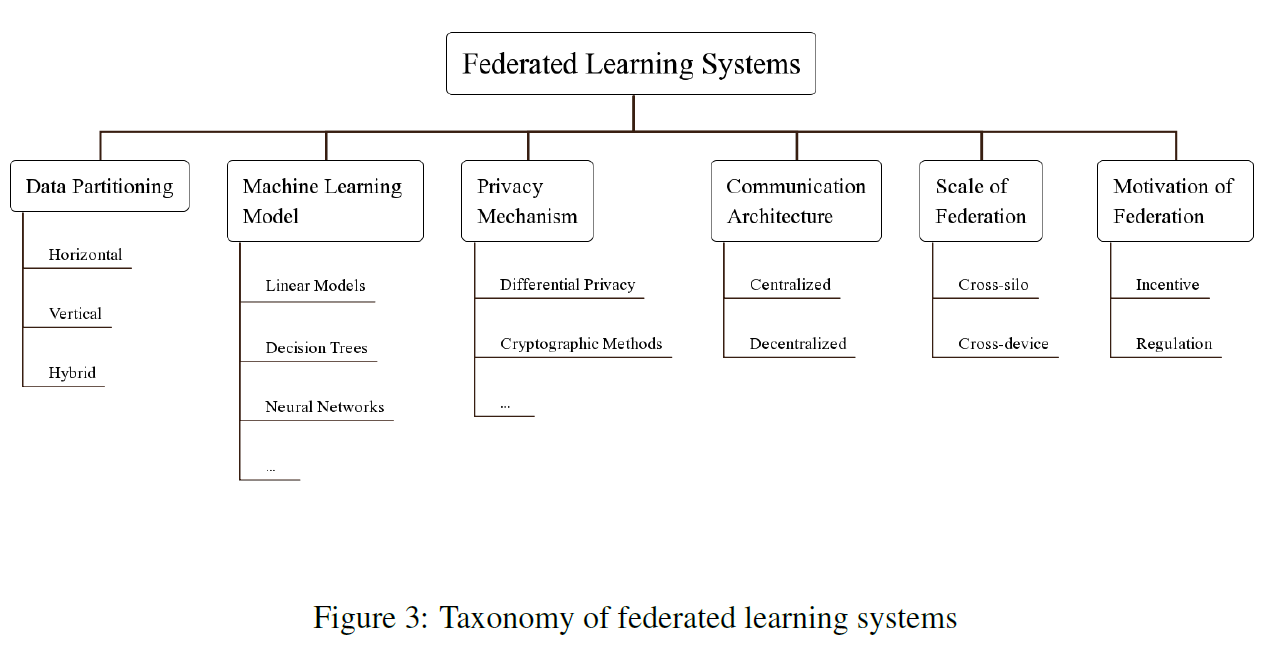
- data partitioning:研究病人的病历(代表数据)是如何在各医院(代表参与者或中心服务器)之间分配的,利用FL中的非重叠实例和特性
- machine learning model:弄清楚这样的任务应该采用哪种机器学习模型
- privacy mechanism:决定用哪种技术做隐私保护
- communication architecture:确定通信框架,若存在可信中心服务器,则在FL中它是管理者;否则采用去中心化架构
- scale of federation:联邦规模与FL过程参与方的计算能力
- motivation of federation:考虑各方的动机来鼓励它们参与到FL中(激励机制的设计)
其中scale of federation和motivation of federation是依赖于具体问题的。
Summary of Existing Studies
本文在Google Scholar和arXiv中搜索关键词“Federated Learning”查找最新关键词。若更加系统严谨可参见[PaperNotes]2020.A Systematic Literature Review on Federated Machine Learning: From A Software Engineering Perspective 的方法。
Individual Studies
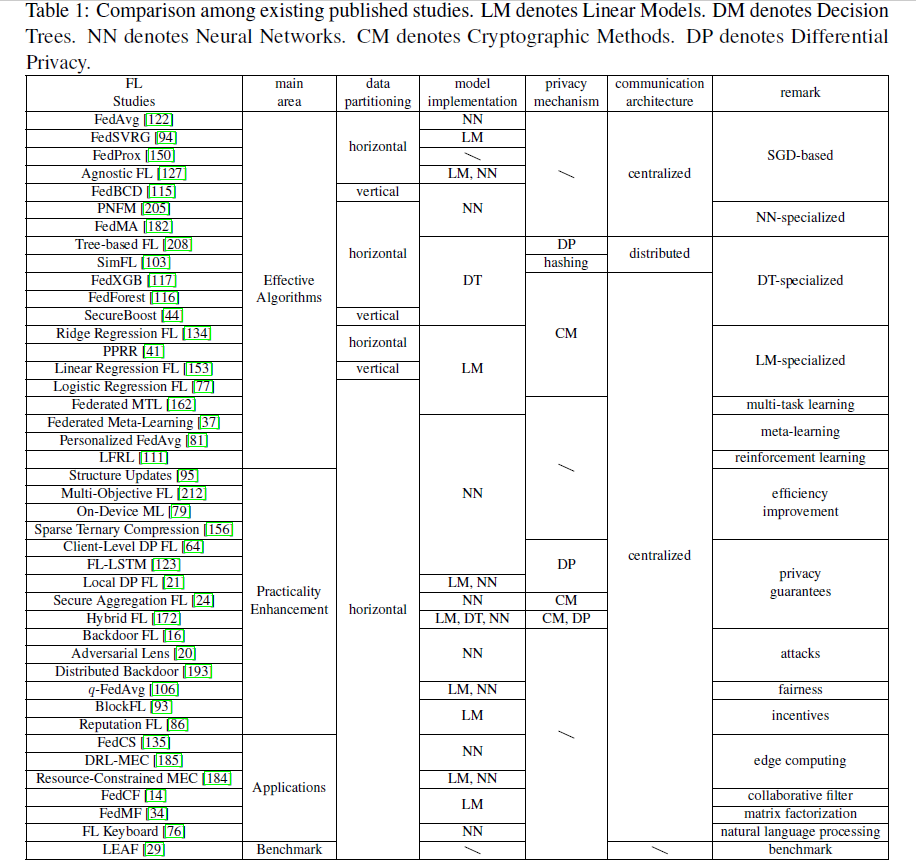
从上表可得四个关键发现:
- 现存的大多研究考虑的是水平数据划分(horizontal data partitioning,即横向联邦学习);VFL在现实世界中也很常见,特别是在不同的组织之间。VFL可以让不同的团体之间进行更多的合作。因此,为了填补这一空白,还需要在垂直FL上付出更多的努力。
- 大多数研究考虑在没有任何隐私保证的情况下交换原始模型参数;当下隐私保证的主流方法是DP和加密方法 (SMC、HE),由于差分隐私可能会影响最终模型的质量,加密方法会带来额外的计算和通信开销并且可能是FLSs的瓶颈。因此,期望以一种便宜的方式,合理的隐私保障来满足法规的要求
- 当前主流的实现方式是中心化设计;在FL实践中,去中心化架构应该做更多研究
- FL的主要研究方向(也是挑战):提高有效性、效率和隐私,这也是评价FL的三个重要指标。其他有趣可做的topic,如fairness、incentive mechanisms
注:已存在的FL研究会周期性更新,截止当前最新更新 April 2, 2020, 见https://arxiv.org/abs/1907.09693
Effective Algorithms
- SGD-based
- Neural Networks
- Trees
- Linear/Logistic Regression
- Others
Summary
- SGD-based框架得到广泛研究和使用,最近大多研究集中在模型专用的FL。=>期望使用model specialized methods来实现更好地模型准确率。本文作者鼓励研究federated decision trees models(如GBDTs)。与神经网络相比,树形模型具有模型规模小、易于训练等优点,可以降低FL中的通信和计算开销。
- 对FL的研究还处于起步阶段。虽然简单的神经网络在联邦环境中得到了很好的研究,但很少有研究将FL应用于训练state-of-the-art的神经网络,如ResNeXt[121]和EfficientNet[169]。如何在复杂的机器学习任务中设计一种有效的、实用的算法仍然是一个具有挑战性和不断发展的研究方向。
- 虽然大部分的研究都集中在水平FL上,但是对于VFL的算法还没有很好的发展.然而,vertical federated setting在实际应用中很常见,其中涉及多个组织。我们期待着在这一有希望的领域进行更多的研究。
Practicality Enhancement
- Efficiency
- Privacy and Attacks
- Fairness and Incentive Mechanisms
Summary
- 除了有效性,效率和隐私是FLS的另外两个重要因素。与这三个领域相比,对公平和激励机制的研究较少。=> 本文作者期待更多关于公平和激励机制的研究,以鼓励使用FL在现实世界中。
- 对于FLSs的效率提高,通信开销仍然是主要的挑战。大多数研究[95,79,156]试图减少每次迭代的通信规模。如何合理设置沟通轮数也是很有前景的[212]。计算和通信之间的权衡仍需进一步研究;
- 在隐私保证方面,差分隐私和安全多方计算是两种比较流行的技术。然而,不同的隐私可能会严重影响模型的质量,安全的多方计算可能非常耗时。设计一个实用的方案仍然是一个挑战。FLS具有强大的隐私保障。此外,针对中毒攻击的有效防御算法还没有被广泛采用。
Applications
- Edge Computing
- Recommender System
- Natural Language Processing
Summary
- 边缘计算自然适合cross-device federated setting。如何有效地利用和管理边缘资源是将FL应用于边缘计算的一个重要问题。FL的使用可以给用户带来好处,特别是对于提高移动设备的服务。
- FL可以解决许多传统的机器学习任务,如图像分类和工作预测。由于法规和“数据岛”,联邦设置可能在未来几年成为一种常见设置。随着FL的快速发展,相信在计算机视觉、自然语言处理、医疗保健等领域将会有更多的应用。
Benchmark
开源benchmark,LEAF,由[29]提出。LEAF包含公共联邦数据集、一组统计和系统指标,以及一组参考实现。然而,它缺乏衡量FLSs的隐私和效率的指标。此外,目前叶的实验还局限在几个方面FL实现,它不够全面。
Open Source Systems
open source FLSs有:
-
Federated AI Technology Enabler (FATE)
-
GoogleTensorFlow Federated (TFF)
-
OpenMined PySyft
-
Baidu PaddleFl
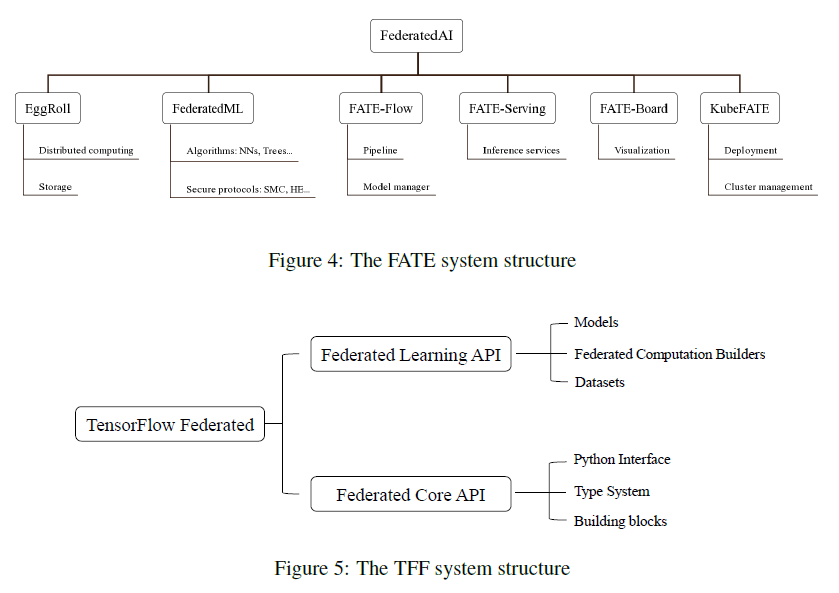


总的来说,FATE和PaddleFL试图提供算法级别的api供用户直接使用,而TFF和PySyft尝试提供更详细的构建块,以便开发人员可以轻松地实现他们的FL过程。表2显示了开源系统之间的比较。在算法层面,FATE是最全面的系统,在水平和垂直设置下都支持许多机器学习模型。TFF和PySyft只实现FedAvg。PaddleFL支持目前在NNs和逻辑回归上的几种水平FL算法。与FATE和TFF相比,PySyft和PaddleFL提供了更多的隐私机制。PySyft涵盖了TFF支持的所有列出的特性,而TFF是基于TensorFlow的,PySyft可以更好地使用PyTorch。
System Design
在FLS的设计中需要考虑的有:effectiveness,efficiency,privacy,autonomy。
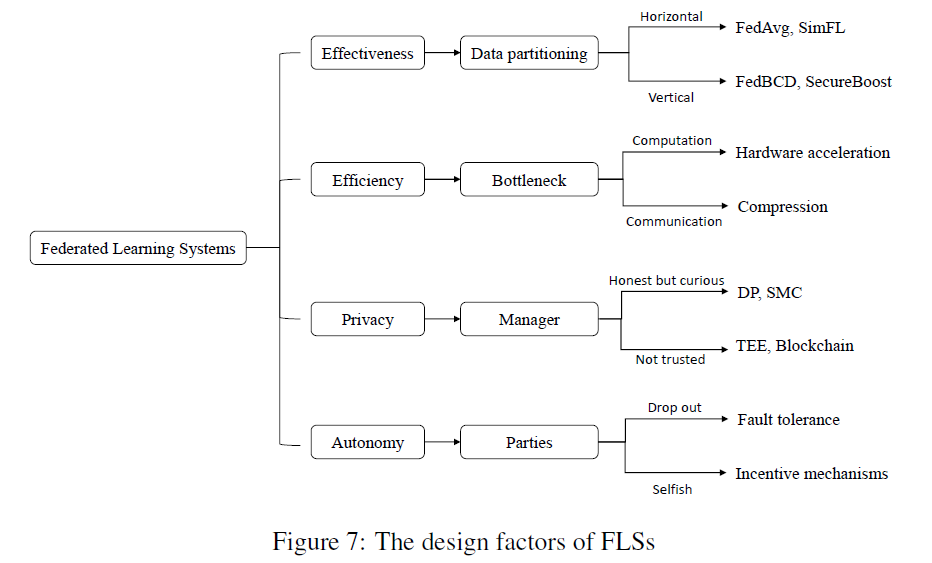
The Design Guideline
- 首先从实际场景出发,通过对系统方面的分析,确定FL算法。这些方面包括数据划分、联邦规模、通信体系结构和机器学习模型。一旦参与实体确定,数据划分和联邦规模基本确定
- 下一步是满足隐私需求。虽然当前的法规没有对模型参数的传输施加明确的限制,但是如果单个记录非常敏感的话,FLS应该保护它们免受推理攻击
- 最后一步是考虑激励机制。激励机制的基本要求是保证当事人的贡献越大,获得的回报就越大。区块链是一个提供稳定和可验证激励的选项[93,86,87]。
Case Study

Vision
一些未来的研究工作
- Heterogeneity 各方在可访问性、隐私需求、对联邦的贡献和可靠性方面可能有所不同。因此,在FL中考虑这些实际问题是很重要的。
- Dynamic scheduling 【25】【210】
- Diverse privacy restrictions【10】
- Intelligent benefits
- Robustness【71】【66】【142,92】
- System Development ——为了推动FLSs的发展,除了算法的详细设计外,还需要从高层次的角度进行研究。
- System architecture 一个通用的系统架构,它提供了多种聚合方法和不同设置的学习算法
- Model market 【191,86,87】
- Benchmark【29】【75】
- Data life cycles
- FL in Domains
- Internet-of-thing【165,199,128】【109,131】【80】【151,54】
- Regulations【73】【152】【67】
文章作者 fzhiy
上次更新 2022-01-01 (cab8260)