迁移学习笔记(一)

文章目录
# 写在前面
计划在这几天看一些TL相关综述论文,并初步写一点学习笔记(待完善,又挖坑了)。本文主要参考《A survey on transfer learning.2016》和《[迁移学习研究进展](<a href="<a href=" https:="" pan.baidu.com="" s="" 1bpautob#'="" target="_blank">https://pan.baidu.com/s/1bpautob#' target='_blank'>https://pan.baidu.com/s/1bpautob),2015》。欢迎留言交流或批评指正
【】内表示原论文中的参考文献条目。
TransferLearning-GitHub:https://github.com/jindongwang/transferlearning
声明:图中所引图片或原始内容归原作者所有,本文仅作学习使用。
迁移学习(TL)研究进展-2015
TL放宽了传统机器学习中的两个基本假设
- 用于学习的训练样本与新的测试样本满足独立同分布的条件;
- 必须有足够可利用的训练样本才能学习得到一个好的分类模型
目的:迁移已有的知识来解决目标领域中仅有少量有标签样本数据甚至没有的学习问题
机器学习中的一个重要问题:如何利用少量的有标签训练样本或源领域数据,建立一个可靠的模型对目标领域数据进行预测(源领域数据和目标领域数据可以不具有相同的数据分布)
【1】指出数据分类首先要解决训练集样本抽样问题,如何抽到具有代表性的样本作为训练集是一个值得研究的重要问题,【1】提出极小样本集抽样方法用于基于超曲面分类算法,该方法可感知非结构化数据的分布并且指出了极小样本集有多少种表达方式
划分方式与分类
-
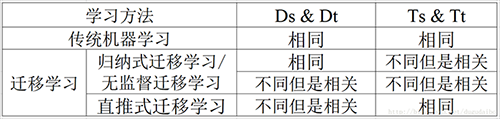
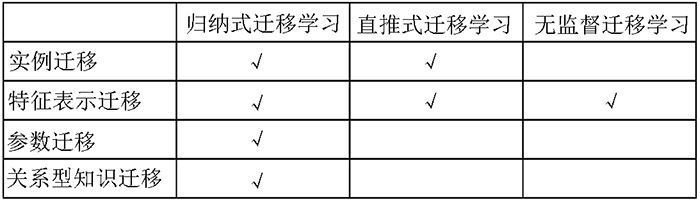
针对源领域和目标领域样本是否标注以及任务是否相同,可以将迁移学习工作划分为1)归纳迁移学习;2)直推式迁移学习;3)无监督迁移学习
-
按照前一方法采用的技术划分:1)基于特征选择的迁移学习算法研究;2)基于特征映射的迁移学习算法研究;3)基于权重的迁移学习算法研究
按源领域和目标领域样本是否标注以及任务是否相同划分
- 根据源领域和目标领域中是否有标签样本可将迁移学习划分为 1)目标领域中有少量标注样本的归纳迁移学习(inductive transfer learning);2)只有源领域中有标签样本的直推式迁移学习(transductive transfer learning);3)源领域和目标领域都没有标签样本的无监督迁移学习
- 根据源领域中是否有标签样本把归纳迁移学习划分为 1)多任务学习;2)自学习;
- 根据训练样本和测试样本是否来自于同一个领域,把直推式迁移学习划分为 1)样本选择偏差;2)协方差偏移;3)领域自适应学习
按采用的技术划分
半监督学习
【38】目前能够利用少量有标签数据和大量没有标签样本数据的技术分为3类:1)半监督学习(semi-supervised learning);2)直推式学习(transductive learning);3)主动学习(active learning)
多视角学习(multi-view learning)也是半监督学习的一个重要的学习任务
自学习(self-taught learning)也是一个利用大量无标签数据来提高给定分类聚类任务性能的方法,自学习被应用于迁移学习中,因为它不要求无标签数据的分布与目标领域中的数据分布相同
【54】提出了一种自学习的方法,它利用稀疏编码技术对无标签的样本数据构造高层特征,然后少量有标签的数据以及目标领域无标签的样本数据都由这些简洁的高层特征表示,实验结果表明:这种方法可以极大提高分类任务的准确率
基于特征选择方法
基于特征选择的迁移学习方法是 识别出源领域与目标领域中共有的特征表示,然后利用这些特征进行知识迁移
【55】 与样本类别高度相关的那些特征应该在训练得到的模型中被赋予更高的权重,因此在领域适应问题来训练一个通用的分类器;然后从目标领域无标签样本中选择特有特征来对通用分类器进行精华从而得到适合于目标领域数据的分类器
【4】提出了一种基于联合聚类(co-clustering)的预测领域外文档的分类方法CoCC
CoCC算法的关键思想是识别出领域内(也称为目标领域)与领域外(也称源领域)数据共有的部分,即共有的词特征。然后类别信息以及知识通过这些共有的词特征从源领域传到目标领域
基于特征映射方法
基于特征映射的迁移方法是把各个领域的数据从原始高维特征空间映射到低维特征空间,在低维空间下,源领域数据与目标领域数据拥有相同的分布【3,58-61】。该方法与特征选择的区别在于:这些映射得到的特征不在原始的特征当中,是全新的特征
基于权重方法
在TL中,有标签的源领域数据的分布与无标签的目标领域数据的分布是不一样的,因此那些有标签的样本数据并不一定是全部有用的。 如何侧重选择那些对目标领域分类有利的训练样本? —— 这是基于实例的迁移学习所要解决的问题
基于实例的迁移学习通过度量有标签的训练样本与无标签的测试样本之间的相似度来重新分配源领域中样本的采样权重。相似度大的即对训练目标模型有利的训练样本被加大权重,否则削弱
【26】提出 一种实例权重框架来解决自然语言处理任务下的领域适应问题,首先从分布的角度分析了产生领域适应问题的原因,主要有两方面:1)实例的不同分布;2)分类函数的不同分布 ==» 提出了一个最小化分布差异化的风险函数,来解决领域适应性问题
【12】将Boosting学习算法扩展到迁移学习中,提出了TrAdaBoost算法
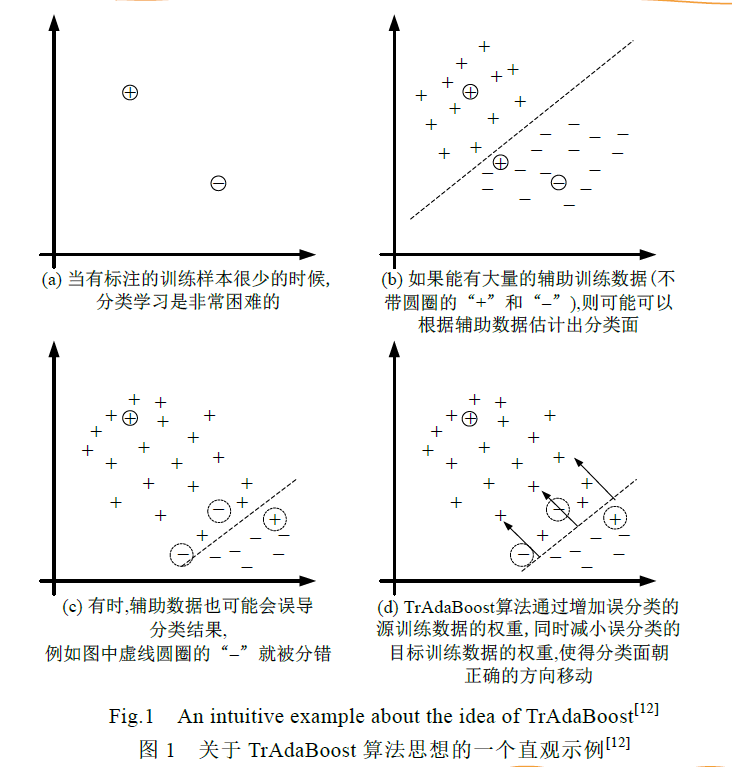
根据是否从多个源领域数据学习,迁移学习算法可以分为单个领域以及多个源领域的迁移学习
迁移学习相关理论研究
理论层面,TL研究以下问题:
- 什么条件下从源领域数据训练出的分类器能够在目标领域表现出优异的分类性能, 即什么条件下可进行迁移?
- 给定无标注目标领域, 或者有少量的标记数据,如何在训练过程中与大量有标记的源数据结合使得测试时的误差最小, 即迁移学习算法的研究 。目前对迁移学习理论研究比较多的主要是在领域适应性方面
【2】最早提出关于领域适应性问题的理论分析,该文 最有价值的贡献在于定义了分布之间的距离,此距离y与领域适应性有关。 在此基础上,对有限VC维情况,【76】从有限个样本估计适应推广能力。但当VC 维不是有限的情况下会有什么样的结论该文并未给出研究,需要进一步探讨.另外,不同的领域分布之间的距离会得出不同精度的误差估计,由此可以通过研究各具特色的距离以解决领域适应性问题。
基于生成模型的迁移学习方法
- 基于判别模型的学习算法【13,58-60】
- 根据给定源领域数据X,直接训练得到判别模型P(Y|X) ==» 由于源领域与目标领域数据分布不一致,判别模型未考虑联合概率P(X,Y),因此有时不能得到很好的预测结果
- 基于生成模型的学习算法
- 先计算得到联合概率P(X,Y),再计算P(Y|X),这样可以对源领域和目标领域数据不同分布进行建模,从而实现源领域和目标领域之间的知识迁移以及提高算法的性能【68,82-84】
【82】对为什么采用生成模型进行迁移学习算法研究进行了讨论.由于生成模型对联合概率进行建模,具有更强的领域间不同数据分布的建模能力,所以更适合于迁移学习
【82】研究基于生成模型的挖掘多领域之间共性与特性的跨领域分类方法,对有效挖掘词特征聚类与文档类别关联关系进行了深入研究。主要思想如下图:
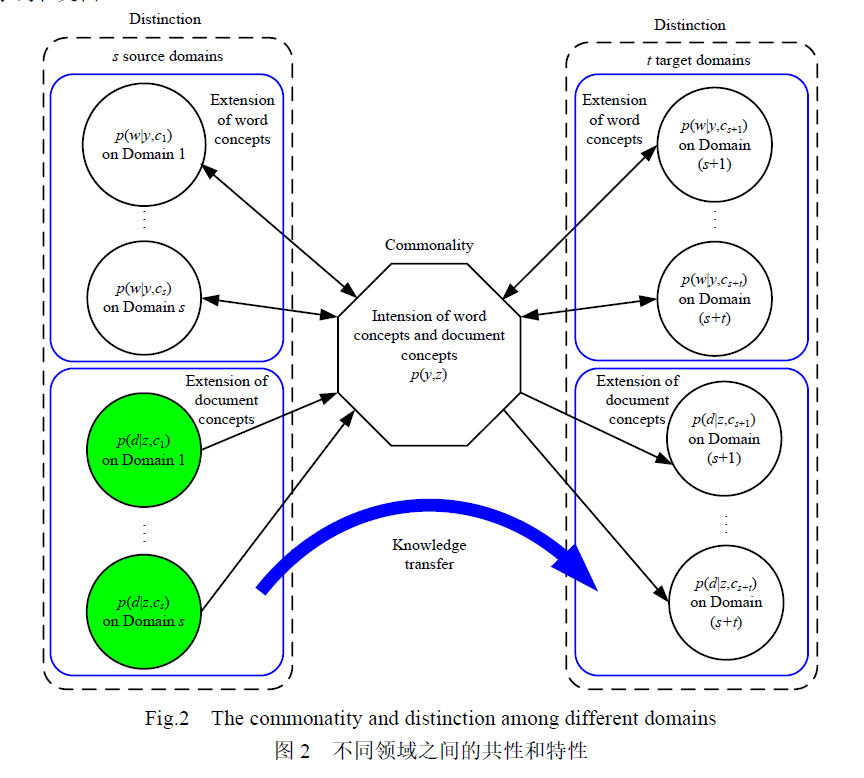
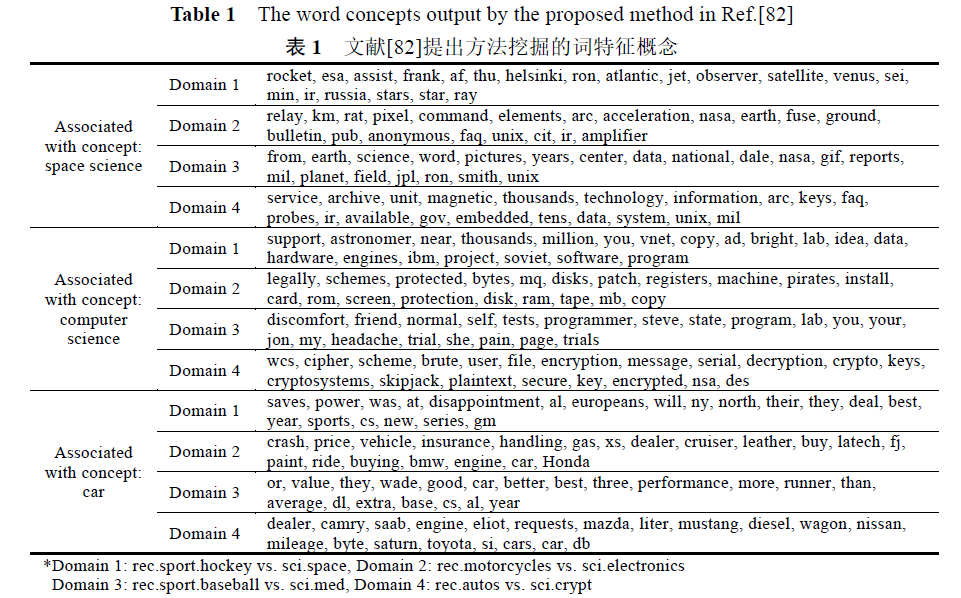
迁移学习应用研究
目前(2015),迁移学习典型的应用方面的研究主要包含有 文本分类、文本聚类、情感分类、图像分类、协同过滤、基于传感器的定位估计、人工智能规划等
- 文本处理领域有【4,5,18,24,56,62,69,83,85】,【4】联合聚类方法,【56】在概念层面上对文本进行处理,提出挖掘文档概念与词特征概念的迁移学习方法. 【69】提出双重迁移模型,进一步对概念进行划分,提高分类准确率。。。
- 图像处理,【16】提出了翻译迁移学习方法
- 协同过滤方面【75,89-92】
- 香港科技大学Qiang Yang实验室,一系列的室内定位的迁移学习方面的工作。
- 智能规划方面,【95】提出一种新的迁移学习框架TRAMP,将迁移学习用于人工智能规划中的动作模型获取。
已有的算法还不能满足实际的应用需求,处理的数据量还比较小,而且算法复杂度也比较高.下一步的 研究应更关注于高效算法的设计上,以做到确实满足实际需要.
未来研究方向
-
针对领域相似性、共同性的度量,目前还没有深入的研究成果,那么首要任务就是研究准确的度量方法;
-
在算法研究方面,不同的应用,迁移学习算法的需求有所不同.目前很多研究工作主要集中在迁移学习分类算法方面**,其他方面的应用算法有待进一步研究**,比如情感分类、强化学习、排序学习、度量学习,人工智能规划等;
-
关于迁移学习算法有效性的理论研究还很缺乏,研究可迁移学习条件,获取实现正迁移的本质属性,**避免负迁移,**也是方向之一;
-
最后,在大数据环境下,研究高效的迁移学习算法尤为重要.
目前的研究主要仍集中在研究领域,数据量小而且测试数据非常标准,应把研究的算法瞄准实际应用数据,以顺应目前大数据挖掘研究浪潮.
A survey on transfer learning-2016
概述
主要讲述三个问题(重点在1,3)
-
迁移什么:提出了迁移哪部分知识的问题;

-
何时迁移:提出了哪种情况下迁移手段应当被运用;
-
如何迁移:迁移学习的方式。
具体内容方法
同质(homogeneous)迁移学习及各方法特征

大多数**同质迁移学习(homogeneous transfer learning)**解决方案采用以下三种通用策略之一,其中包括 1)尝试校正源中的边缘分布差异;2)尝试校正源中的条件分布差异;3)尝试校正源中的边缘和条件分布差异。
 !!!
!!!
迁移学习解决方案发展的最新趋势是:
- 解决源域和目标域之间边缘和条件分布差异的解决方案;
- 与两阶段流程相比,执行一个阶段(one-stage) process。
在选择过程中要评估的一个重要特征是给定源域和目标域之间存在何种类型的差异。
被调查的同质迁移学习工作未专门应用于大数据解决方案; 但是,并没有排除它们在大数据环境中的使用。
异质(heterogeneous)迁移学习
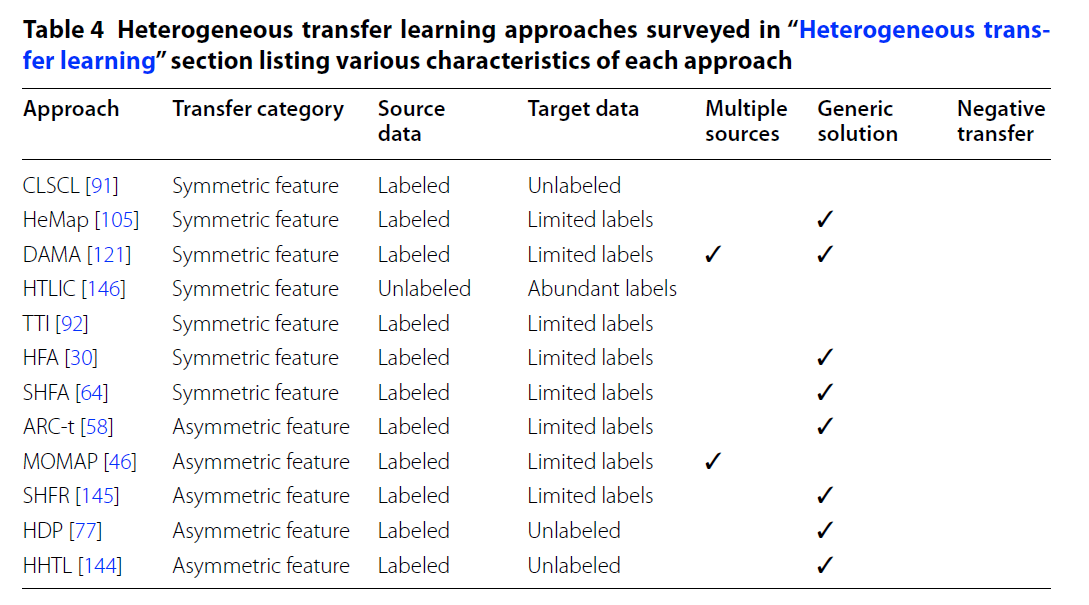
本节涵盖的异构迁移学习应用程序包括图像识别[30、58、146、105、92、64],多语言文本分类[145、30、91、144、64、124],单语言文本分类[121 ],药物功效分类[105],人类行为分类[46]和软件缺陷分类[77]。 异构转移学习也直接适用于大数据环境。
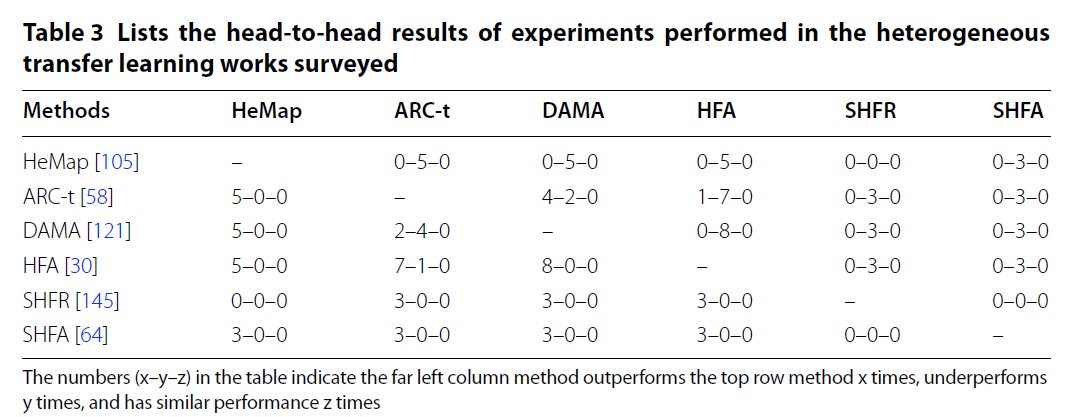
异构迁移学习仍然是一个相对较新的研究领域,涉及该主题的大多数著作已在过去5年中发表。
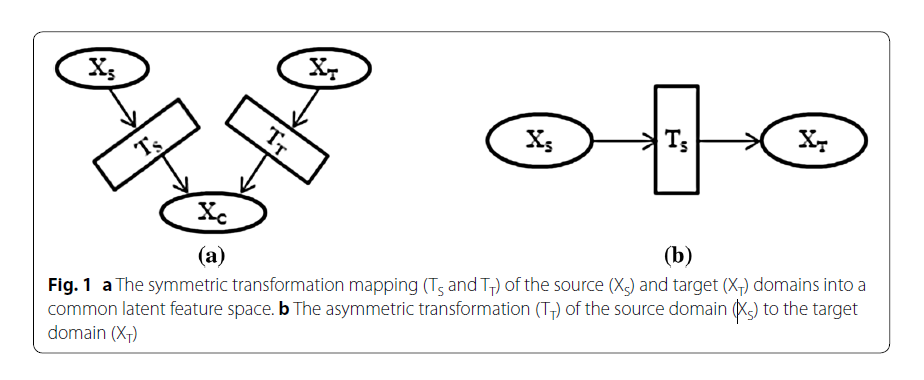
当可以在**没有上下文特征偏差(context feature bias)**的情况下转换源域和目标域中的相同类实例时,最好使用非对称转换(asymmetrical transformation)方法。 许多调查的异质迁移学习解决方案仅解决输入特征空间在源域和目标域之间不同的问题,而不解决边缘 和/或 条件分布差异所需的其他域适应步骤。
负迁移(Negative transfer)
迁移学习的高层次概念是通过使用来自相关源域的数据来改善目标学习者;
如果源域与目标域的相关性不佳,目标学习者会受到这种弱关系的负面影响,这被称为负迁移。
负转移领域尚未得到广泛研究,但以下论文开始解决这一问题。
- 【98】讨论了转移学习中负迁移的概念,并声称源域必须与目标域充分相关。 否则,从源头迁移知识的尝试可能会对目标学习者产生负面影响
- 【31】提出基于来自多个相关源域的可迁移性度量来构建目标学习者。【17】频谱图论理论
- 【40】声称由于存在不相关或不相关的源域,因此可以抑制知识迁移
- 。。。
结论与讨论
调查了异质迁移学习的一个相对较新的领域,它显示了域自适应的两种主要方法是不对称迁移和对称迁移。
由于缺少标记的目标数据,修正条件分布差异是一个具有挑战性的问题。 ==» 伪标签 ==» 该方法有问题 ==» 修正条件分布差异的改进方法是未来研究的一个方向。
未来的工作领域:
1)量化校正两种分布(条件分布、边缘分布)的优势以及在哪种情况下最有效;
2)量化任何性能收益,以同时解决两种分布差异。
使用领域特征的启发式知识探索可能的数据预处理步骤;在大多数情况下,这种启发式知识将用于特定的某个领域,这不会导致通用解决方案;但是如果这样的预处理步骤 ==»提高目标学习者的表现,则是可能值得付出努力。
在制定迁移学习解决方案时观察到的趋势是在执行一个阶段(one-stage)的过程而不是在两个阶段的过程中。
负迁移方向仍然是研究很少的领域。 ==» optimal transfer
参考文献
- [1]《A survey on transfer learning.2016》
- [2]《迁移学习研究进展,2015》
- [3] https://lingyixia.github.io/2019/04/23/TransferLearning/
–fzhiy.更新于2020年9月26日21点43分
文章作者 fzhiy
上次更新 2020-09-26