联邦学习笔记(三)

文章目录
写在前面
参考文献《Federated Learning: Challenges, methods, and future, 2020》,较为详细的介绍当前FL的挑战和解决方法以及未来可能的研究方向或切入点。
Federated Learning: Challenges, methods, and future
摘要
联邦学习在保持数据本地化的同时涉及在远程设备或孤立的数据中心(例如手机或医院)上训练统计模型。在异构网络和潜在大规模网络中进行训练带来了新的挑战,这些挑战要求从根本上区别于大规模机器学习,分布式优化和隐私保护数据分析的标准方法。在本文中,我们讨论了联邦学习的独特特征和挑战,提供了当前方法的广泛概述,并概述了未来的几个方向
因为设备(智能手机、可穿戴设备和自动驾驶车辆)计算力的上升以及对隐私信息转移的担忧,所以将数据保存于本地和网络计算边缘化变得更加有吸引力。 ==» 边缘计算
正因为在分布式网络下这些设备的存储和计算能力使得利用每台设备上的增强(enhanced)本地资源成为可能,此外,用户隐私信息保存于本地避免了隐私担忧。 ==» 联邦学习
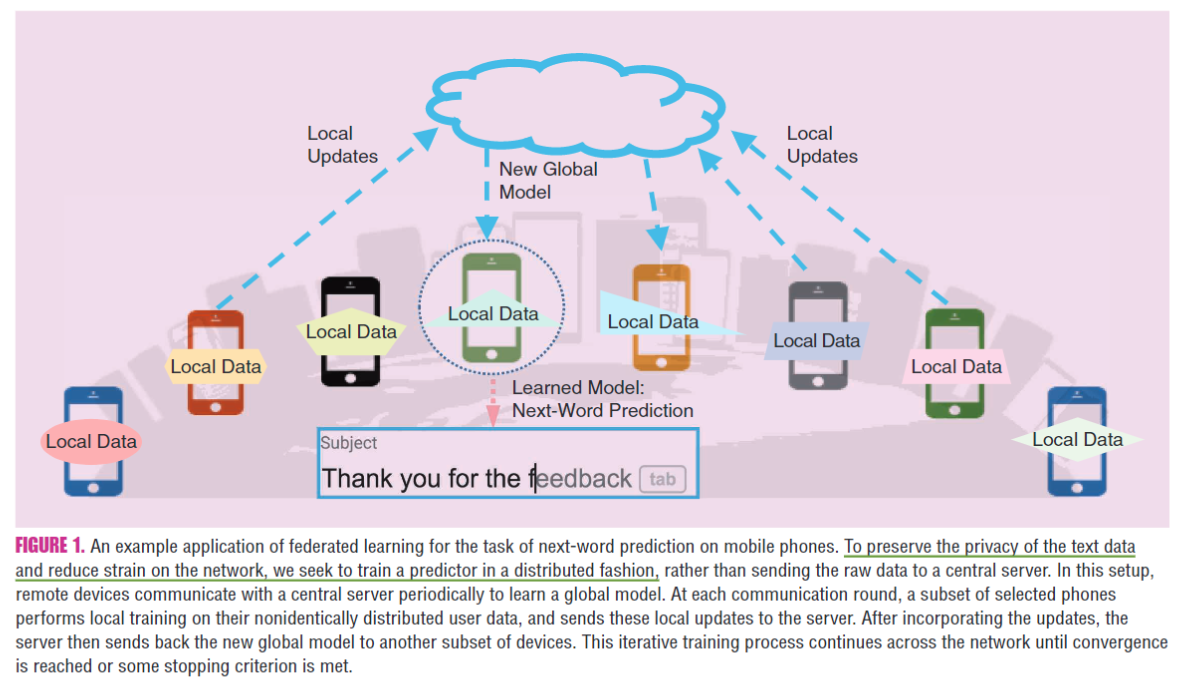
FL的应用
-
智能手机
-
单词联想 《A. Hard, K. Rao, R. Mathews, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage, Federated learning for mobile keyboard prediction. 2018. [Online]. Available: arXiv:1811.03604》
-
挑战:用户为了保护个人隐私可能不愿意分享数据或者节省手机有限的带宽/电量
-
FL有潜力在不损害用户体验或泄露隐私信息前提下在智能手机上启用预测功能
-
-
组织机构 –医疗机构
- L. Huang, Y. Yin, Z. Fu, S. Zhang, H. Deng, and D. Liu, LoAdaBoost: Loss-based adaboost federated machine learning on medical data. 2018. [Online]. Available: arXiv:1811.12629
-
物联网– 可穿戴设备、自动驾驶车辆、智能家居
FL方法在公司的应用
- K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konecnyet al., “Towards federated learning at scale: System design,” in Proc. Conf. Machine Learning and Systems, 2019.
- M. J. Sheller, G. A. Reina, B. Edwards, J. Martin, and S. Bakas, “Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation,” in Proc. Int. MICCAI Brainlesion Workshop, 2018, pp. 92–104. doi: 10.1007/978-3-030 -11723-8_9.
隐私敏感应用
- T. S. Brisimi, R. Chen, T. Mela, A. Olshevsky, I. C. Paschalidis, and W. Shi, “Federated learning of predictive models from federated electronic health records,” Int. J. Medical Informatics, vol. 112, Apr. 2018, pp. 59–67. doi: 10.1016/j.ijmedinf.2018.01.007
- L. Huang, Y. Yin, Z. Fu, S. Zhang, H. Deng, and D. Liu, LoAdaBoost: Loss-based adaboost federated machine learning on medical data. 2018. [Online]. Available: arXiv:1811.12629
挑战
目标: 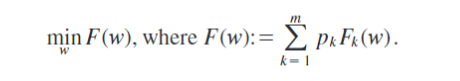
m表示总设备数量,p_k>=0 且 SUM(p_k)=1,F_k为第k个设别的本地目标函数
-
昂贵的通信费用
- 为了使模型适用于联邦网络中设备产生的数据,需要开发通信效率高的方法,该方法可以迭代地发送small message或者将模型更新作为训练过程的一部分,而不是通过网络发送整个数据集
- 进一步减少这种设置下的通信,需要考虑两个关键方面
- 减少通信回合总数量
- 减少每个回合发送信息的大小
-
系统异质性
由于硬件(CPU和内存)、网络连接(3G、4G、5G、WiFi)、能量(电池等级)的差异,因此联邦网络中每个设备的存储、计算和通信能力都各不相同
- 系统级别的特性极大地加剧了诸如straggler mitigation和容错(fault tolerance)之类的挑战;
- 已进行的FL方法有
- 预计参与人数少
- 容忍异质的硬件
- 通信网络中足够坚固以防设备掉落
-
统计异质性
设备经常以高度不相同的方式在网络上生成和收集数据
- [42]《V. Smith, C.-K. Chiang, M. Sanjabi, and A. Talwalkar, “Federated multi-task learning,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 4424–4434》 数据生成范例违反了分布式优化中经常使用的独立且均匀分布(i.i.d.)的假设,可能会增加问题建模,理论分析和解决方案的经验评估方面的复杂性
- 多任务学习和元学习都支持个性化或特定于设备的建模,这通常是一种更自然的方法来处理数据的统计异构性,以实现更好的个性化
-
隐私问题
- 安全多方计算SMC
- 差分隐私DP
- 以上方法通常以减少模型表现或系统高效性为代价换取隐私保护, 因此平衡两者关系是一个挑战
相关工作
已经提出许多方法来解决优化和信号处理社区中的昂贵通信问题[28, 40, 43],但是这些方法无法完全处理联邦网络规模和系统与统计异质性的挑战
-
通信效率
尽管提供对通信效率高的学习方法的独立概述不在本文的讨论范围内,但我们指出了几个总体方向,我们将其归类为1)本地更新方法,2)压缩方案和3)分散培训本地更新
-
本地更新
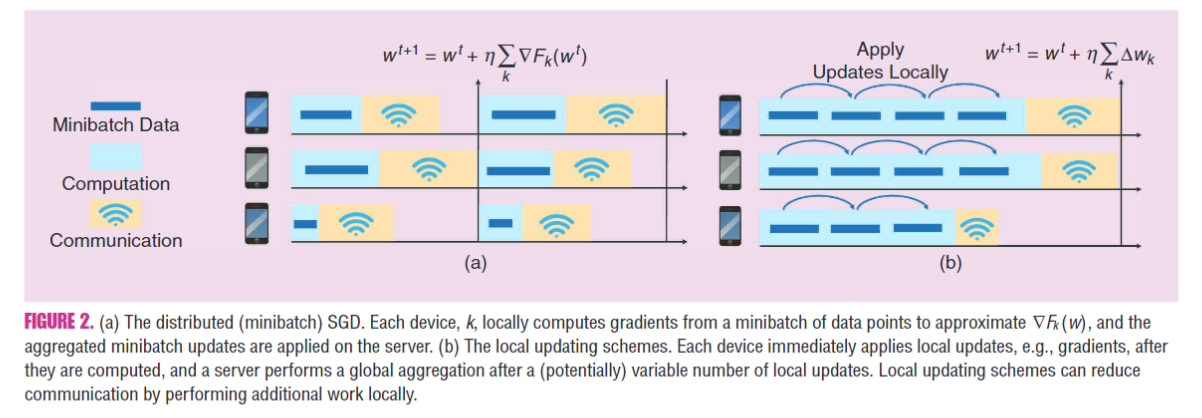
- 小批处理优化方法涉及扩展经典的随机方法以一次处理多个数据点,已成为数据中心环境中分布式机器学习的流行范例。然而,实际上,他们在适应通信计算权衡方面显示出有限的灵活性[53]《S. Zhang, A. E. Choromanska, and Y. LeCun, “Deep learning with elastic averaging SGD,” in Proc. Advances in Neural Information Processing Systems, 2015, pp. 685–693》
- 最近的一些方法:通过允许在每个通信回合中并行地将变量应用于每台计算机(而不是仅局部地计算它们然后集中地应用它们)来提高分布式设置中的通信效率。 [44]《S. U. Stich, “Local SGD converges fast and communicates little,” in Proc. Int. Conf. Learning Representations, 2019.》。这使得计算量与通信量相比更加灵活。
- 对于凸目标,分布式局部更新原始方法已经成为解决此类问题的一种流行方法[43]《V. Smith, S. Forte, C. Ma, M. Ta kac, M. I. Jordan, and M. Jaggi, “CoCoA: A general framework for communication-efficient distributed optimization,” J. Mach. Learning Res., vol. 18, no. 1, pp. 8590–8638, 2018》;一些分布式局部更新原始方法对非凸目标也可有额外的好处
- 最常用的优化方法是联邦平均(FedAvg)算法,已经证明FedAvg在实际中可以很好地工作,特别是对于非凸问题,但是它没有收敛保证,并且在数据异构情况下会在实际设置中发散[25]《T. Li, A. K. Sahu, M. Sanjabi, M. Zaheer, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” in Proc. Conf. Machine Learning and Systems, 2020.》
-
压缩方案
- 尽管本地更新方法可以减少通信回合的总数,但是模型压缩方案(例如稀疏化和量化)可以显著减少每次回合传递的消息的大小。全面回顾[47]《 H. Wa ng, S. Sievert, S. Liu, Z. Charles, D. Papailiopoulos, and S. Wright, “ATOMO: Communication-efficient learning via atomic sparsification,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 1–12.》
- 在FL环境中,设备的参与度低、分布不均的本地数据和本地更新方案对模型压缩方法提出新挑战
- FL设置中的实用策略
- 迫使更新模型稀疏和低等级[22]
- 使用结构化随机旋转实现量化[22]
- 使用有损压缩和丢失来减少服务器到设备的通信[9]
- 理论上,先前的工作探索了存在不完全相同的数据情况下进行低精度训练的收敛性保证[45],但所做假设未考虑联邦环境的共同特征,例如设备参与度低 或 本地更新优化方法
-
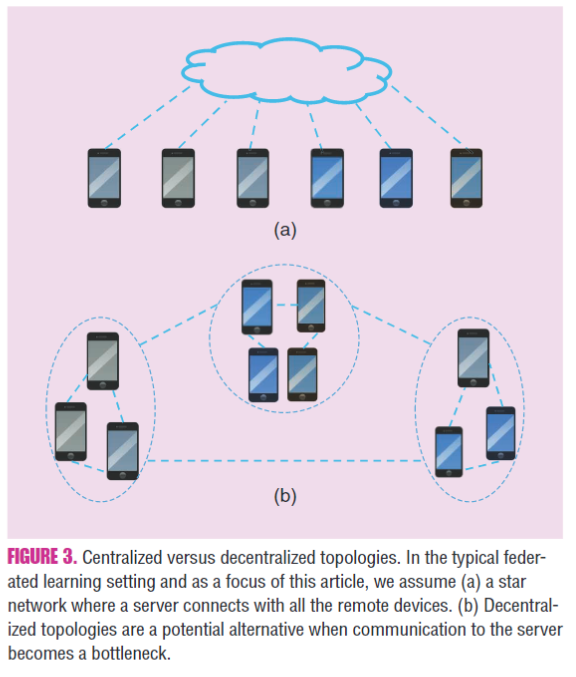
去中心化(分布式)训练
-
在数据中心环境中,在低带宽或高延迟的网络上运行时,分布式训练已证明比集中式训练要快。一些工作提出了基于截止日期(deadlines-based)的方法,所有工人在固定的全球周期内使用可变数量的样本来计算局部梯度,这有助于减轻流浪者的影响[16],[39]。 (全面回顾[18])
[18] L. He, A. Bian, and M. Jaggi, “Cola: Decentralized linear learning,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 4541–4551.
-
在联邦学习中,理论上分布式算法可以减少中央服务器上的高通信成本。最近的一些工作研究了使用本地更新方案对异构数据进行分散训练[18]。但是,它们要么局限于线性模型[18],要么假定完全参与设备
-
-
-
系统异质性
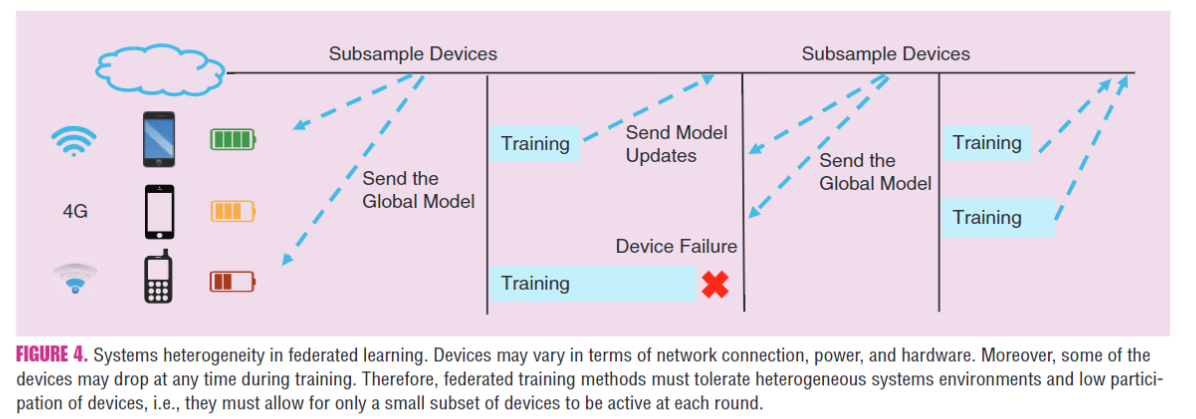
- 异步通信
- 主动采样(active sampling)
- 容错能力
- 尽管一些工作研究了FL变体方法理论上的收敛保证,但是很少的工作允许低参与或者直接研究掉线设备的影响。 FedProx
- 编码计算(Coded computation)通过引入算法冗余 [11]
-
统计异质性
- 建模异构数据
- 元学习、多任务学习[12, 14, 21],如MOCHA[42]
- non-iid数据的收敛保证
- 在IID设置中[38,48,53]已经分析了Parallel SGD及其相关变体使得本地更新类似于FedAvg。但是,结果依赖一个前提,即每个本地求解器是同一个随机过程的副本(iid假设),在典型的联邦设置中情况不是这样
- FedProx, 关键思想:系统异质性和统计异质性之间存在相互作用。FedProx对FedAvg方法进行了较小的修改,它允许根据基础的系统约束跨设备执行部分工作,并利用近端项来安全地合并部分工作。 可以将其视为FedAvg的重新参数化
- 建模异构数据
-
隐私
-
机器学习中的隐私
在这些各种隐私方法中,由于**差分隐私[13]**强大的信息理论保证,算法简单性以及相对较小的系统开销,因此被最广泛地使用
- 差分隐私以传达嘈杂的数据草图
- 同态加密以对加密数据进行操作
- 安全功能评估(SFE)或多方计算
- k-anonymity匿名和σ-presence存在
HE和SMC全面回顾[7]《R. Bost, R. A. Popa, S. Tu, and S. Goldwasser, “Machine learning classification over encrypted data,” in Proc. Network and Distributed System Security Symp., 2015. doi: 10.14722/ndss.2015.23241》
-
联邦学习中的隐私

联邦学习隐私分类:1)全局隐私,2)本地隐私
- 当前工作旨在提高联邦学习隐私,这些工作经常建立在以前经典密码协议(SMC[4]和DP[2])的基础上
- 安全聚合是一种无损方法并且可以保持高度隐私保护的情况下保留原始准确性。但是最终方法会产生大量的额外通信成本
- 其他诸如将DP应用于联邦学习并提供全局差异隐私[32]的方法具有许多影响通信和准确性的超参数,因此必须谨慎选择。
- DP可以与模型压缩技术结合使用以减少通信同时获得隐私好处[1]《N. Agarwal, A. T. Suresh, F. X. X. Yu, S. Kumar, and B. McMahan, “cpSGD: Communication-efficient and differentially-private distributed SGD,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 7564–7575》
-
未来研究方向
-
极致的通信方案
- 尽管在传统的数据中心环境中已经探索了单次或分而治之的通信方案[29],但是在大规模和统计异构网络中,这些方法的行为还没得到很好的理解
-
通信减少与the Pareto frontier
- 联邦训练中减少通信的方法有本地更新和模型压缩,了解这些技术之间的相互关系以及系统分析每种方法的准确性和通信之间的权衡很重要
- 有效的神经网络推理对于FL通信减少技术中是有必要的
-
新颖的异步模型
- 批量同步方法
- 异步方法(假定延迟有限)
-
异质性诊断
开放性问题:
- 是否有简单的诊断方法可以快速地预先确定联邦网络中的异质性水平?
- 是否可以开发类似的诊断方法来量化与系统相关的异质性数量?
- 是否可以利用当前或新的异质性定义来设计新的经验和理论上具有改进收敛性的联邦优化方法?
-
细颗粒隐私限制
在实践中,隐私约束可能在设备之间甚至单个设备的数据点之间都不同,因此有必要将隐私问题细分
- sample-specific privacy[24]《J. Li, M. Khodak, S. Caldas, and A. Talwalkar, “Differentially private meta-learning,” in Proc. Int. Conf. Learning Representations, 2020》
- device-specifiv privacy
-
超越监督学习之外的
-
生产化联邦学习
除了本文讨论的主要挑战之外,在生产环境中运行联合学习时还存在许多实际问题。尤其是诸如概念漂移(当基础数据生成模型随时间变化时),昼夜变化(当设备在一天或一周的不同时间表现出不同的行为)之类的问题[14],以及冷启动问题(当新设备进入网络时)必须小心处理。
[5]《K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, J. Konecnyet al., “Towards federated learning at scale: System design,” in Proc. Conf. Machine Learning and Systems, 2019.》讨论了生产联邦学习系统中存在的一些与系统相关的实用问题
总结
与传统的分布式数据中心计算和经典的隐私保护学习相比,讨论了联邦学习的独特性质和相关挑战。提供了关于经典结果的广泛调查以及针对联邦环境的最新工作。最后,概述了一些有待进一步研究的未解决问题。提供这些问题的解决方案将需要众多研究社区的跨学科研究。
参考文献
- [1] Federated Learning: Challenges, methods, and future, 2020
–fzhiy.更新于2020年9月2日16点51分
文章作者 fzhiy
上次更新 2020-09-01