联邦学习笔记(一)

文章目录
写在前面
笔记主要参考《Federated Machine Learning Concept and Applications》和《联邦学习》。作为一个入门笔记,可以当作是论文译文也可以作为进一步学习的框架。按照该论文做的一个框架,同时尽量将《联邦学习》书中部分内容进行整合,当然最好是能够利用好这本书相关研究内容。
摘要
当今人工智能仍然面临两大挑战:
- 在大多数工业中,数据以 “孤岛”形式存在
- 加强数据隐私和安全问题
针对上述挑战提出可能的解决方法: 安全联邦学习(secure federated learning)
全面介绍了安全联邦学习的框架,包括
1)横向联邦学习(horizontal federated learning),
2)纵向联邦学习(vertical federated learning),
3)联邦迁移学习(federated transfer learning)
提供FL定义、架构、FL框架的应用,以及在这个学科领域已存在工作的全面调查研究;此外,提出基于联邦机制在各个组织者之间建立数据网络 作为一种有效方案使知识在不被侵害用户隐私情况下共享。
1.引言
当今,在几乎每种工业领域正在展现它的强大之处。然而,回顾AI的发展,不可避免地是它经历了几次高潮与低谷。**AI将会有下一次衰落吗?什么时候出现?什么原因?**当前 大数据的可得性 是驱动AI上的public interest的部分原因:2016年 AlphaGo使用20万个游戏作为训练数据取得了极好的结果。
**然而,真实世界的情况有时是令人失望的:除了一部分工业外,大多领域只有有限的数据 或者 低质量数据,这使得AI技术的应用困难性超出我们的想象。有可能通过组织者间转移数据把数据融合在一个公共的地方吗? 事实上,非常困难, 如果可能的话,很多情况下要打破数据源之间的屏障。**由于工业竞争、隐私安全和复杂的行政程序,即使在 同一公司的不同部分间的数据整合 都面临着严重的限制。几乎不可能整合遍布全国和机构的数据,否则成本很高。
同时,意识到大公司在数据安全和用户隐私上的危害,重视数据隐私和安全已经成为世界范围的重大事件。 公众数据泄露的新闻正在引起公众媒体和政府的高度关注。 例如,Facebook最近的数据泄露引起了广泛抗议。作为回应,世界各个州正在加强法律保护数据安全和隐私。例如 欧盟在2018.5.25实施的**《通用数据保护条例》General Data Protection Regulation(GDPR),旨在保护用户个人隐私和提供数据安全。** 它要求企业使用清晰明了的语言来达成用户协议,并授予用户“被遗忘的权力”,也就是说,用户可以删除或撤回其个人数据。违反该法案的公司将面临严厉罚款。 **2017年实施的《中国网络安全法》和《民法通则》**要求互联网业务在与第三方做数据交易时禁止在手记个人信息时进行泄露和篡改,并且他们需要确保提出的合同遵守法律数据保护业务。 **这些法规的建立显然将有助于建立一个更加文明的社会,但也将给当今AI中普遍使用的数据交易程序带来新的挑战。**
更具体地,AI传统的数据处理模型通常参与简单的数据交易模型, 一方参与者收集和转移数据到另一方,其他参与者负责清洗和融合数据,最终一个第三方机构 将拿走整合的数据 建立模型models给其他参与者使用。 这些模型models通常是最终产品作为服务售卖。 这种传统的程序面临以上新数据法规的挑战。并且,因为用户可能不清楚模型的未来用途,所以交易违反了GDPR等法律。
因此,我们面临着一个难题,即我们的数据是孤立的孤岛形式,但是在许多情况下,我们被禁止在不同地方收集、融合和使用数据进行AI处理。如何合法地解决数据碎片和隔离问题是当今AI研究人员和从业人员面临地主要挑战。
2.FL总览
Google提出FL的概念,其主要想法是 基于分布在多个设备上的数据集构建机器学习模型,同时防止数据泄露。 最近的改进集中在克服联邦学习中的统计挑战[60, 77]和提高安全性[9, 23]。也有研究工作使联邦学习更加个性化[13, 60]. 上面的工作全部集中在设备上的联合学习中,其中设计分布式移动用户交互,并且大规模分配,不平衡数据分配和设备可靠性中的通信成本是优化的一些主要隐私。此外,数据由用户ID或设备ID划分,因此在数据空间中 水平划分。 如[58]所述,该工作线与隐私保护机器学习高度相关,因为它也考虑了分散式协作学习环境中的数据隐私。为了将联邦学习的概念扩展到组织之间的协作学习方案,我们将原始的“联邦学习”扩展到所有保护隐私的分散式协作式机器学习技术的通用概念。在[71]中,我们对联合学习和联合转移学习技术进行了初步概述。在本文中,我们将进一步调查相关的安全基础,并探讨与其他几个相关领域的关系,例如多主体理论和隐私保护数据挖掘。在本节中,我们提供了一个更全面的联邦学习定义,其中考虑了数据分区,安全性和应用程序。我们还描述了联合学习系统的工作流和系统架构。
2.1 定义
$$
M_{FED}表示数据所有者共同训练的模型,V_{FED}表示模型M_{FED}的准确率(accuracy)\
M_{SUM}表示使用D=D_1 \cup D_2 \cup … \cup D_n 训练的模型,V_{SUM}表示M_{SUM}的准确率
$$

如果满足上式,则我们说联邦学习算法有 $$ \sigma 准确率的损失 $$
2.2 FL隐私
-
安全多方计算(Secure Multiparty Computation (SMC))
SMC安全模型涉及多方,并在定义明确的仿真框架中提供安全性证明,以确保完全零知识,也就是说,除了输入和输出外,每一方都不知道。零知识是高度期望的,但是这种期望的属性通常需要复杂的计算协议,并且可能无法有效实现。在某些情况下,如果提供安全保证,则可以认为部分知识公开是可以接受的。可以在较低的安全性要求下用SMC建立安全性模型以换取效率[16]《Privacy-preserving multivariate statistical analysis:Linear regression and classification,2004》。最近,一项研究[46]使用SMC框架来训练带有两个服务器和半诚实假设的机器学习模型。在[33]中,MPC协议用于模型训练和验证,而用户无需透露敏感数据。最先进的SMC框架之一是Sharemind [8]《 A framework for fast privacy-preserving com-putations,2008》。 [44]《 mixed protocol framework for machine learning,2018**》的作者以诚实的多数提出了3PC模型[5,21,45],并**考虑了半诚实和恶意假设中的安全性。这些作品要求参与者的数据在非竞争服务器之间秘密共享。
-
差分隐私(Differential Privacy)
另一工作线使用差异隐私技术[18]《Differential privacy: A survey of results. 2008》或k-匿名用户技术[63]《K-anonymity: A model for protecting privacy.2002》进行数据隐私保护[1,12,42,61]。差异隐私,k匿名和多样化的方法[3]《Privacy-preserving data mining.2000》涉及给数据添加噪声,或使用归纳法掩盖某些敏感属性,直到第三方无法区分个人为止,从而使数据无法恢复保护用户隐私。但是,这些方法的根本仍然要求将数据传输到其他地方,这通常需要在准确性和隐私之间进行权衡。在[23]《Differentially private federated learning: A client level perspec-tive.2017》中,作者介绍了一种用于联合学习的差分隐私方法,目的是通过隐藏客户在培训期间的贡献来为客户数据提供保护。
-
同态加密(Homomorphic Encryption)
在机器学习过程中,也采用同态加密[53]《 On data banks and privacy homomorphisms.1978》来通过加密机制下的参数交换来保护用户数据隐私[24,26,48]。**与差异隐私保护不同,数据和模型本身不会被传输,也不会被另一方的数据猜中。**因此,在原始数据级别泄漏的可能性很小。最近的工作采用同态加密来集中和训练云上的数据[75,76]。在实践中,加性同态加密[2]《A survey on homomorphic encryptionschemes: Theory and implementation.2018》被广泛使用,并且需要采用多项式近似来评估机器学习算法中的非线性函数,从而在准确性和隐私性之间进行权衡[4,35]。
2.2.1 非直接信息泄露
联邦学习的先驱作品揭示了中间结果,例如来自诸如随机梯度下降(SGD)之类的优化算法的参数更新[41,58]。但是,没有提供安全保证,当与数据结构一起暴露时,例如在图像像素的情况下,这些梯度的泄漏实际上可能会泄漏重要的数据信息[51]《Privacy-preserving deeplearning via additively homomorphic encryption.2018》。
在[6]《How To BackdoorFederated Learning.2018》中,作者证明有可能将隐藏的后门插入一个联合全局模型中,并提出一种新的**“约束和规模”模型中毒方法(“constrain-and-scale” model-poisoning methodology)**以减少数据中毒。
在[43]《Inference attacks against collab-orative learning.2018》中,研究人员发现了协作机器学习系统中的潜在漏洞,在协作机器学习系统中,当事方在协作学习中使用的训练数据很容易受到推理攻击。他们表明,对抗性参与者可以推断出成员资格以及与训练数据子集相关的属性。他们还讨论了针对这些攻击的可能防御措施。
在[62]《 Securing distributed machine learning in high dimensions.2018》中,作者揭示了与不同方之间的梯度交换相关的潜在安全问题,并提出了梯度下降方法的安全变体。他们表明,它可以承受恒定比例的拜占庭工人。
研究人员还开始考虑将区块链作为促进联邦学习的平台。在[34]《On-Device Federated Learning via Blockchainand its Latency Analysis.2018》中,研究人员考虑了区块链联邦学习(BlockFL)架构,利用区块链交换和验证移动设备的本地学习模型更新。他们考虑了最佳的块生成,网络可伸缩性和健壮性问题。
2.3 FL分类
讨论根据数据的分布特征对联邦学习进行分类。 $$ D_i表示数据用户i拥有的数据。矩形的每一行代表一个样本,每一列代表一个特征。同时,一些数据集可能也\包含标签数据。定义X为特征空间,y为标签空间,I为样本ID空间。(I,X,y)构成完整的训练集。 $$
2.3.1 横向联邦学习
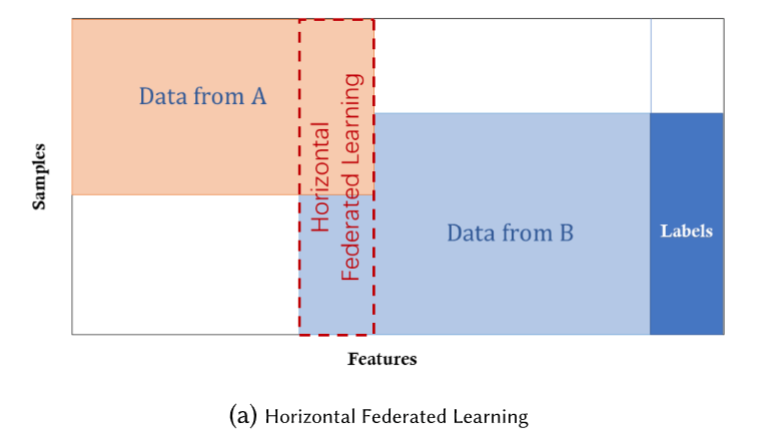
横向联邦学习(Horizontal Federated Learning,HFL)也称按样本划分的联邦学习,可以应用于联邦学习的各个参与方的数据集有相同的特征空间和不同的样本空间的场景,类似于在表格视图中对数据进行水平划分。举例,两个地区的城市商业银行可能在各自的地区拥有非常不同的客户群体,所以他们的客户交集非常小,他们的数据集有不同的样本ID。但是他们的业务模型非常相似,因此他们的数据集的特征空间是相同的,这两家银行可以联合起来进行横向联邦学习来构建更好的风控模型。横向联邦学习的条件总结如下:
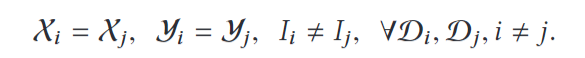
HFL安全性定义
通常假设HFL系统的参与方都是诚实的,需要防范的对象是一个 诚实但好奇的聚合服务器。即通常只有服务器才能使数据参与方的隐私安全受到威胁。
相关研究
-
《Practical secure aggregation for privacy-preserving machine learning.2017》提出一种在联邦学习框架下对用户模型更新或者对梯度信息进行安全聚合(secure aggregation)方法;
-
《Privacy-preserving deeplearning via additively homomorphic encryption.2018》提出一种适用于模型参数聚合的加性同态加密(Additive Homorphic Encryption, AHE)方法,能够防御联邦学习系统里的中央服务器窃取模型信息或者数据隐私;
-
《Federated multi-task learning.2017》提出了一种 多任务形式的联邦学习系统,允许多个参与方通过分享知识和保护隐私的方式完成不同的机器学习任务。多任务学习模型还可以进一步解决通信开销、网络延迟以及系统容错等问题;
-
《Federated learning of deepnetworks using model averaging.2016》提出了一种安全的“客户-服务器”架构。其中, 联邦学习系统的迅雷数据存储在客户端(即参与方),每个客户端在其本地利用其拥有的数据训练机器学习模型,每个客户端将自己训练的模型参数发送给一个联邦学习服务器(即协调方),并在该服务器上通过融合的方法(如 模型平均)构建一个全局模型。该模型构建过程确保了数据不会暴露,很好地保护了数据安全和用户隐私。 进一步地, 《Federated optimization: Distributedmachine learning for on-device intelligence. 2016》提出了一种 减少通信开销的方法,以此利用分布在移动设备中的数据训练中心模型;
-
《 Deep gradient compression: Reducing thecommunication bandwidth for distributed training.2017》提出了一种叫做**深度梯度压缩(Deep Gradient Compression,DGC)**的压缩方法,能够大幅降低在大规模分布式训练中需要的通信带宽;
-
《Deep models under the GAN: Information leakagefrom collaborative deep learning.2017》考虑了恶意用户的安全模型, 带来联邦学习新的安全挑战。当联邦模型训练结束时,聚合模型和整个模型的参数都会暴露给所有的参与方
2.3.2 纵向联邦学习
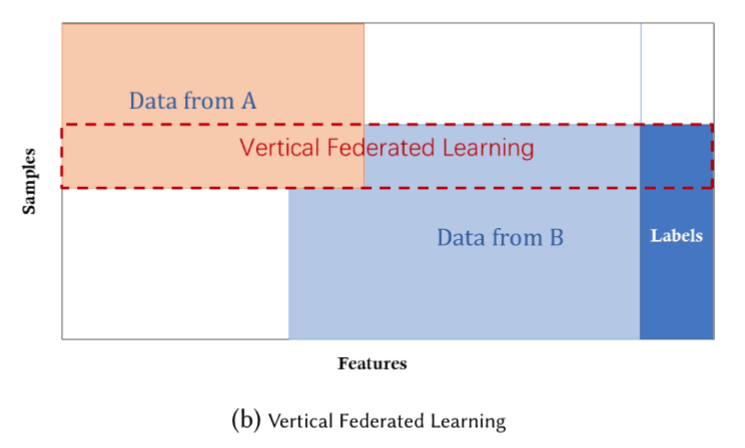
纵向联邦学习(Vertical Federated Learning,VFL)也可以理解为 按特征划分的联邦学习,可应用于数据集上具有 相同的样本空间、 不同的特征空间的参与方所组成的联邦学习。 出于不同的商业目的,不同组织拥有的数据集通常具有不同的特征空间,但这些组织可能共享一个巨大的用户群体,如上图。 通过使用VFL,我们可以利用分布于这些组织的异构数据,搭建更好的机器学习模型,并且不需要交换和泄露隐私数据。
纵向联邦学习条件为:
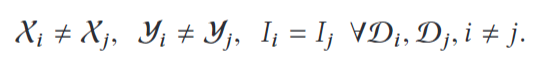
在VFL的设置中,存在一些关于实现安全和隐私保护的假设。
- VFL假设参与方都是诚实但好奇的。(这意味着参与方虽然遵守安全协议,但将会尝试通过从其他参与方处获得的信息,尽可能地推理出信息中包含的具体内容。由于各参与方也想要搭建一个更加精确的模型,所以他们相互之间不会共谋)
- VFL假设信息的传输过程是安全且足够可靠的,能够抵御攻击。此外,还假设通信是无损的,不会使得中间结果的内容发生变化。
VFL安全定义
假设一个VFL系统中存在诚实但好奇的参与方。例如,在一个两方场景中,双方不会共谋且最多有一个参与方被敌对方破坏。 安全定义 是指敌对方只能从其破坏的参与方拥有的数据上进行学习,而不能访问到其他参与方的数据。为了使两方之间的安全计算更加便利,有时会加入一个STP,并假设该STP不会与任一方共谋。MPC提供了这些协议的正式隐私证明《How to play any mental game. 1987》。在学习过程的最后,每一个参与方只会拥有与自己的特征相关的模型参数,因此在推理过程中,两方也需要协作地生成输出结果。
相关研究
已经提出了针对垂直划分的数据的隐私保护机器学习算法,包括协作统计分析[15],关联规则挖掘[65],安全线性回归[22,32,55],分类[16]和梯度下降[68]。
最近,[27《Private federated learning on vertically partitioned data via entity resolution and additively homo-morphic encryption.2017》,49《Entity resolution and federated learning get a federated resolution.2018》]的作者提出了一种纵向联邦学习方案,以训练保持隐私的逻辑回归模型。作者研究了实体分辨率(entity resolution)对学习性能的影响,并将泰勒逼近应用于损失和梯度函数,从而可以将同态加密用于隐私保护计算。
2.3.3 联邦迁移学习

HFL和VFL要求所有的参与方具有相同的特征空间或样本空间,从而建立起一个有效的共享机器学习模型。
但是,在更多的实际情况下,各个参与方拥有的数据集可能存在高度的差异:
- 参与方的数据集之间可能只有少量的重叠样本和特征;
- 这些数据集的分布情况可能差别很大;
- 这些数据集的规模可能差异巨大;
- 某些参与方可能只有数据,没有或只有很少的标注数据
为解决上述问题,联邦学习可以结合迁移学习技术,使其可以应用于更广的业务范围,同时可以帮助只有少量数据(较少重叠的样本和特征)和若监督(较少标记)的应用建立有效且精确的机器学习模型,并且遵守数据隐私和安全条例的规定。 将这种组合称为 联邦迁移学习。
FTL是对现存联邦学习系统的一种重要拓展,因为它能处理超出HFL和VFL能力范围的问题:
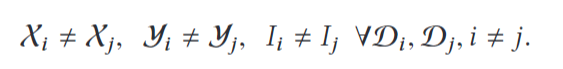
FTL安全定义
联邦转移学习系统通常涉及两方。如下一节将显示的,其协议类似于VFL中的协议,在这种情况下,可以在此处扩展VFL的安全性定义。
FTL与传统的TL的不同
从技术角度看,主要分为两方面:
- 联邦迁移学习基于分布在多方的数据来建立模型,并且每一方的数据不能集中到一起或公开给其他方。传统迁移学习没有这样的限制;
- 联邦迁移学习要求对用户隐私和数据(甚至模型)安全进行保护,这在传统迁移学习中并不是一个主要关注点。
2.4 联邦学习系统架构
2.4.1 横向联邦学习
两种HFL系统架构, 分别称为 客户-服务器(client-server)架构和 对等(Peer-to-Peer, P2P)架构。
1)客户-服务器架构
典型的HFL系统的客户-服务器架构如下图,也称为 主-从(master-worker) 或者 轮辐式(hub-and-spoke)架构。
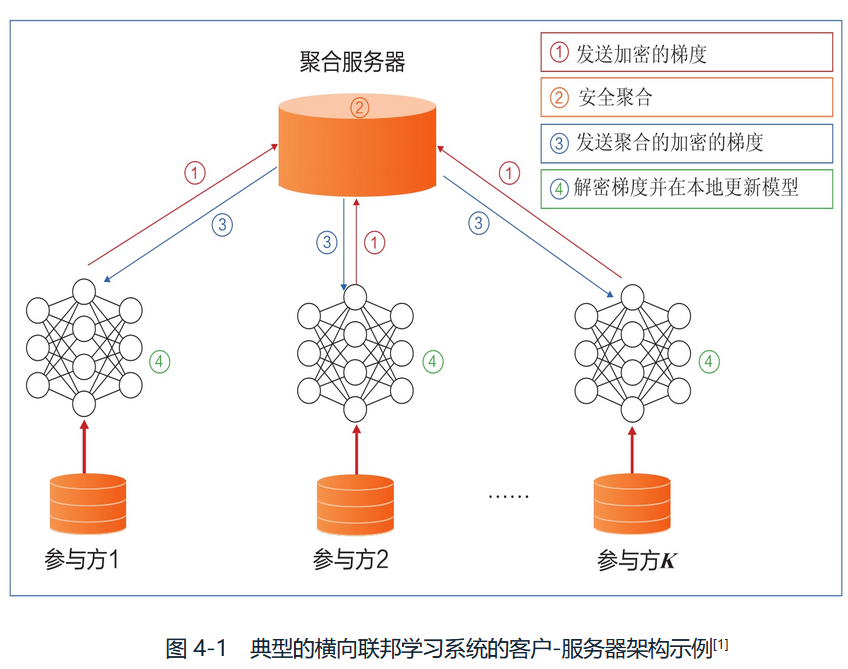
HFL系统的训练过程:
- 各参与方在本地计算模型梯度,并使用同态加密、差分隐私或秘密共享等加密技术,对梯度信息进行掩饰,并将掩饰后的结果(简称 加密梯度)发送给聚合服务器;
- 服务器进行安全聚合(secure aggregation)操作,如使用基于同态加密的加权平均
- 服务器将聚合后的结果发送给各参与方;
- 各参与方对收到的梯度进行加密,并使用解密后的梯度结果更新各自的模型参数
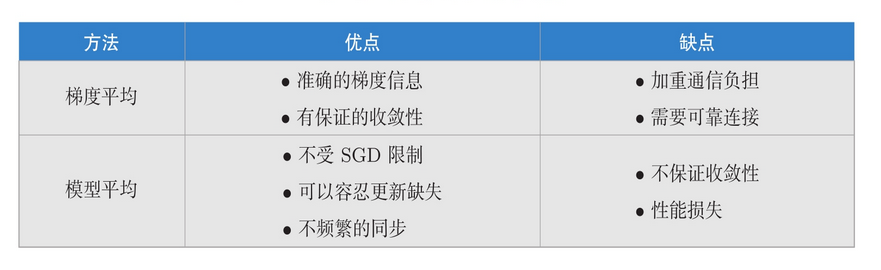
联邦平均算法(Federated Adveraging,FedAvg),分为梯度平均和模型平均。两者均为聚合服务器收到参与方的梯度信息或模型参数 进行 计算加权平均时使用的方法。
安全分析
如果联邦平均算法使用你了安全多方计算(SMC)或者同态加密技术,则上述框架能防范半诚实服务器的攻击,并防止数据泄露。但是,在协同学习过程中,若有一个恶意的参与训练生成对抗网络(GAN),将可能导致系统容易遭受攻击《Deep models under the GAN: Information leakagefrom collaborative deep learning.2017》。
2)对等网络架构
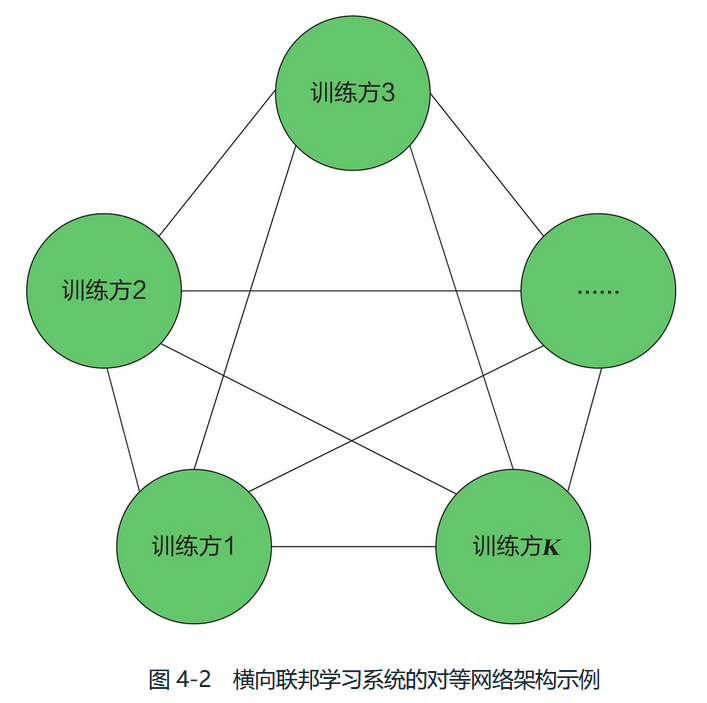
由于对等网络架构中不存在中央服务器,训练方们必须提前商定发送和接收模型参数信息的顺序,主要有两种方法可以达到这个目的:
- 循环传输
- 随即传输
优缺点
与客户-服务器相比,对等网络结构的一个明显 优点是去除了中央服务器(即参数或聚合服务器或协调方),而这类服务器在一些实际应用中可能难以获取或建立
**坏处:**在循环传输模式中,由于没有中央服务器,权重参数并不分批量更新而是连续更新,将导致训练模型耗费更多的时间。
2.4.2 纵向联邦学习
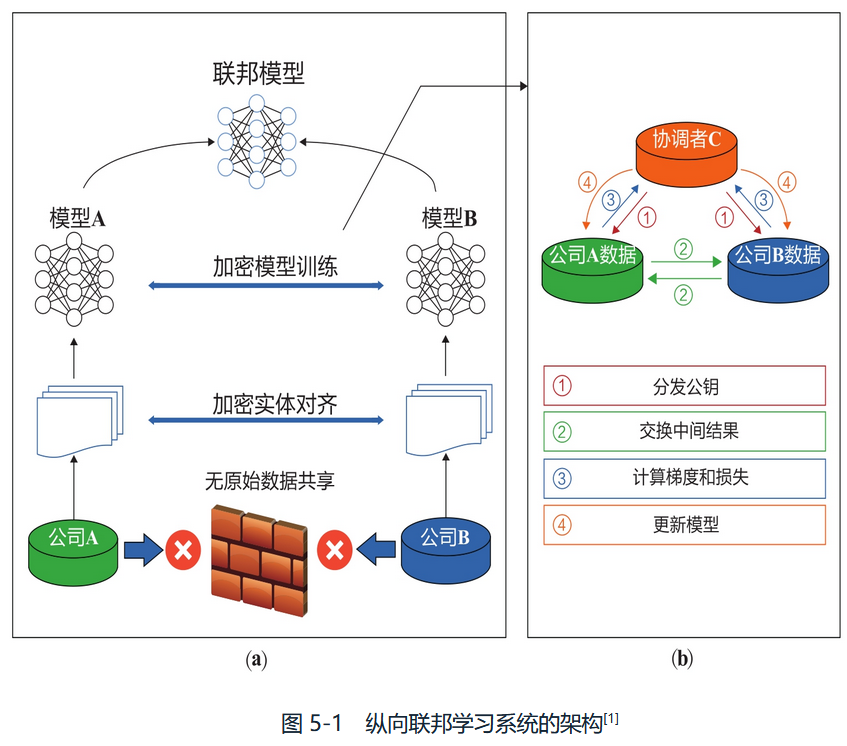
VFL系统训练过程一般由两部分组成:
-
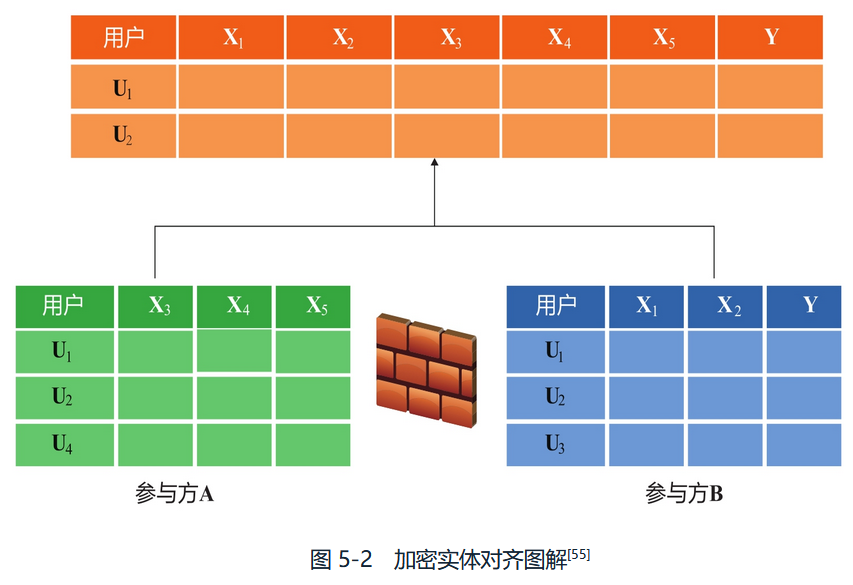
加密实体对齐(由于A方和B方公司的用户群体不同,系统使用一种基于加密的用户ID对齐技术)
-
《 Privacy preserving schema anddata matching. 2007》
如上面两篇文献中描述,使用该技术来确保A方和B方不需要暴露各自的原始数据便可以对其共同用户。如图5-2.
-
加密模型训练(分为4个步骤)
- 协调者C创建密钥对,并将公共密钥发送给A方和B方
- A方和B方对中间结果进行加密和交换。中间结果用来帮助计算梯度和损失值
- A方和B方计算加密梯度并分别加入附加掩码(additional mask)。B方还会计算加密损失。A方和B方将加密的结果发送给C方
- C方对梯度和损失信息进行加密,并将结果发送会A方和B方。A方和B方解除梯度信息上的掩码,并根据这些梯度信息来更新模型参数
VFL算法
其中两种,如 安全联邦线性回归 和 安全联邦提升树(SecureBoost,2019)
2.4.3 联邦迁移学习
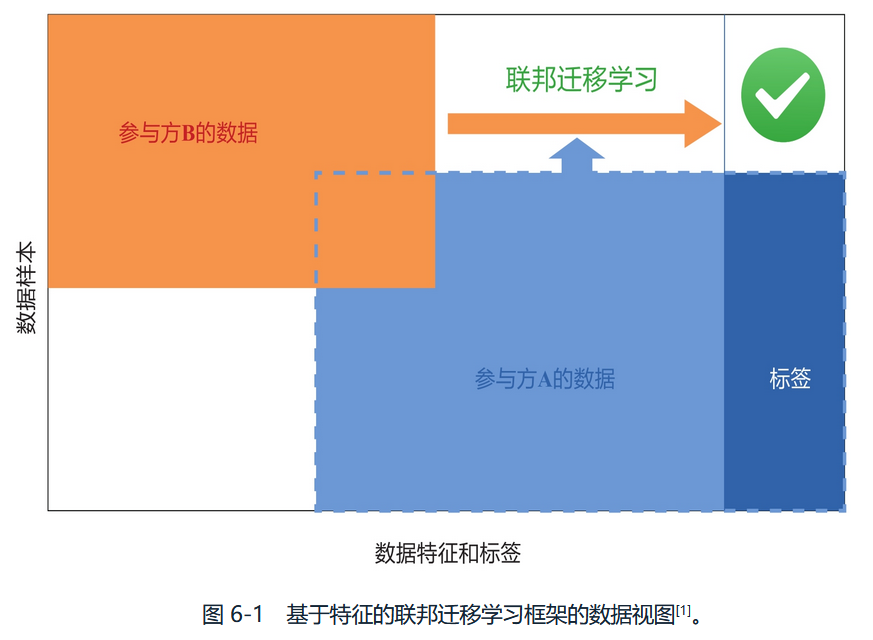
假设在上面的VFL示例中,参与方A和B仅具有非常少的重叠样本集,并且我们有兴趣了解参与方A中整个数据集的标签。仅适用于重叠的数据集。为了将其覆盖范围扩展到整个样本空间,我们引入了转移学习。这不会改变VFL所示的总体架构,但是会改变在甲方和乙方之间交换的中间结果的细节。具体而言,转移学习通常涉及学习参与方A和B的功能之间的通用表示,并通过利用源域参与方(在这种情况下为B)中的标签来最小化预测目标域参与方的标签中的错误。因此,甲方和乙方的梯度计算与垂直联合学习方案中的梯度计算不同。在推理时,仍然需要双方计算预测结果。
《Secure federated transfer learning.2018》提出的一种安全的、基于特征的联邦迁移学习框架。
下图描述了该联邦学习框架的数据视图:
2.4.4 激励机制
在联邦学习中,实现 如何建立激励机制使得参与方持续参与到数据联邦中 这一目标的关键是制定一种奖励方法,公平公正地与参与方们分享联邦产生地利润。联邦学习激励方法(Federated Learning Incentivizer,FLI)地各种激励分配方法的任务目标是 为最大化联邦的可持续经营,同时最小化参与方间的不公平性,动态地将给定的预算分配给联邦中的各个参与方,还可以扩展为一种能够帮助联邦抵御恶意的参与方的调节机制。
3 相关工作
3.1 隐私保护机器学习
联邦学习可以被认为是隐私保护和去中心化协作机器学习。因此,它与多方隐私保护机器学习紧密相关。过去,许多研究工作已致力于该领域。
例如,[17,67]的作者提出了用于垂直分割数据的安全多方决策树的算法。
Vaidyaand Clifton提出了用于垂直分区数据的安全关联挖掘规则[65],安全k均值[66]和朴素的贝叶斯分类器[64]。
[31]的作者提出了一种用于水平分割数据的关联规则的算法。
安全支持向量机算法已经被开发用于垂直分割的数据[73]和水平分割的数据[74]。
[16]的作者提出了用于多方线性回归和分类的安全协议。
[68]的作者提出了安全的多方梯度下降方法。这些作品全部使用SMC [25,72]进行隐私保护。
参考《联邦学习》第二章
3.2 联邦学习 vs 分布式机器学习
乍一看,横向联邦学习与分布式机器学习有些相似。分布式机器学习涵盖了许多方面,包括训练数据的分布式存储,计算任务的分布式操作以及模型结果的分布式分布。参数服务器[30]《 More effective distributed ML via a stale synchronous parallel parameter server. 2013》是分布式机器学习中的典型元素。作为加速训练过程的工具,参数服务器将数据存储在分布式工作节点上,并通过中央调度节点分配数据和计算资源,从而更有效地训练模型。对于HFL,工作节点代表数据所有者。它具有本地数据的完全自主功能。它可以决定何时以及如何加入联合学习。在参数服务器中,中央节点始终负责控制。因此,FL面临着更为复杂的学习环境。此外,联合学习强调在模型训练过程中对数据所有者的数据隐私保护。保护数据隐私的有效措施可以更好地应对未来日益严格的数据隐私和数据安全监管环境。
与分布式机器学习设置一样,联合学习也将需要解决non-IID数据。 [77]《Federated Learning withNon-IID Data.2018》的作者表明,使用non-IID本地数据,可以大大降低联合学习的性能。作为回应,作者提供了一种类似于转移学习的新方法来解决该问题。
参考《联邦学习》第三章
3.3 联邦学习 vs 边缘计算
因为联邦学习为协调和安全性提供了学习协议,所以可以将其看作是边缘计算的操作系统。
[69]《 When edge meets learning: Adaptive control for resource-constrained distributed machine learning.2018》的作者考虑了使用基于梯度下降的方法训练的机器学习模型的通用类。他们从理论的角度分
析了分布梯度下降的收敛范围,并在此基础上提出了一种控制算法,该算法确定局部更新和全局参数聚合之
间的最佳折中,以在给定资源预算下将损失函数最小化。
3.4 联邦学习 vs 联邦数据库系统
联合数据库系统[57]《Federated database systems for managing distributed, heterogeneous, andautonomous databases.1990》是集成多个数据库单元并整体管理集成系统的系统。提出了联邦数据库概念以实现与多个独立数据库的互操作性。联邦数据库系统通常将分布式存储用于数据库单元,实际上,每个数据库单元中的数据都是异构的。因此,就数据类型和数据存储而言,它与联邦学习有很多相似之处。但是,联邦数据库系统在彼此交互的过程中不包含任何隐私保护机制,并且所有数据库单元对于管理系统都是完全可见的。此外,联邦数据库系统的重点是数据的基本操作(包括插入,删除,搜索和合并),而联邦学习的目的是在保护数据隐私的前提下为每个数据所有者建立联合模型 ,以便数据所包含的各种价值和规律可以更好地为我们服务。
4 应用
- 金融
- 医疗
- 教育
- 城市计算和智慧城市
- 边缘计算和智慧城市
- 区块链
- 5G
参考《联邦学习》第10章
5 联邦学习与企业数据联盟
众所周知,随着数据隐私和数据安全的重要性日益提高,以及公司利润与其数据之间的紧密关系,云计算模型受到了挑战。但是,联邦学习的业务模型为大数据的应用提供了新的范例。**当每个机构占用的孤立数据无法产生理想的模型时,联邦学习的机制使机构和企业无需数据交换就可以共享一个统一的模型。**此外,**借助区块链技术的共识机制,联邦学习可以为利润分配制定公平的规则。**数据拥有者,无论他们拥有的数据规模如何,都将被激励加入数据联盟并获得自己的利润。 我们认为应该将数据联盟的业务模型的建立与联邦学习的技术机制一起进行。我们还将制定各个领域的联合学习标准,以尽快将其投入使用。
6 挑战与展望
HFL
- HFL系统里,我们无法查看或检查分布式的训练数据。这导致了 很难选择机器学习模型的超参数以及设定优化器的问题,尤其是在训练DNN模型时。 人们一般会假设协作方或者服务器拥有初始模型,并且指导如何训练模型,但在实际情况中,由于并未提前收集任何训练数据,几乎不可能为DNN模型需那种正确的超参数并设定优化器;
- 一种可以在实际应用时考虑使用的方法,基于模拟的方法. 《Federated Learning,2018.05》,《Federated Learning,2018.08》
- 如何有效地激励公司和机构参与到HFL系统中来?
- 需要设计出有效地数据保护政策、适当的激励机制及用于HFL的商用模型
- 如何防止参与方的欺骗行为?
- 需要设计一种着眼全局的保护诚实参与方的办法
- 为了实现HFL的大规模商用,还需要研究 **掌握训练过程的机制,**如 由于模型训练和评估在每个参与方上都是本地进行的,我们需要发掘新的方法以避免过拟合以及触发提前停止训练
- 如何管理拥有不同可靠度的参与方?
VFL
- VFL训练很容易受到通信故障的影响,从而需要可靠并且高效的通信机制
- 可能需要设计一种 流式的通信机制,可以高效地安排每个参与方进行训练和通信的时机,以抵消数据传输的延迟。同时,对能够容忍在VFL过程中的发生崩溃的 容错机制,也是实现VFL系统所必须考虑的细节
- 由于VFL通常需要参与方之间进行更紧密和直接的交互,因此需要灵活高效的安全协议,以满足每一方的安全需求
- 之前的工作《Server-aided secure computation with off-line parties.2017》 ,《Machine learning classification over encrypted data.,2015》证明,只有具备针对性的安全工具,才能让不同的计算种类达到最有效果
- 高效的基于安全的实体对齐技术
TFL
- 需要制定一种学习可迁移知识的方案。该方案能够很好地捕捉参与方之间地不变性。在顺序迁移学习和集中迁移学习种,迁移知识通常使用一个通用地预训练模型来表示。联邦迁移学习中地迁移知识由各参与方地本地模型共同学习得到。每个参与方都对各自本地模型的设计和训练拥有完全的控制权。在联邦学习模型的自主性和泛化性能之间,需要寻求一种平衡;
- 需要确定如何保证所有参与方的共享表征的隐私安全的前提下,在分布式环境中学习迁移知识表征的方法;
- 需要设计能够部署在FTL中的高效安全协议。在设计或选择安全协议时需要仔细考虑,以便在安全性和计算开销之间取得平衡
最近,数据的隔离和对数据隐私的强调成为AI的下一个挑战,但联合学习给我们带来了新的希望。它可以为多个企业建立统一的模型,同时保护本地数据,以便企业可以在数据安全方面共同努力。
参考文献
-
Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.
-
《联邦学习》 杨强等著
由于个人能力有限,先整理到这,后面根据具体研究情况再更新~
–fzhiy.更新于2020年8月23日18点27分
文章作者 fzhiy
上次更新 2020-08-23