[Linux服务器开发]Linux高并发服务器开发笔记

文章目录
1.Linux系统编程入门

-
GCC工作流程
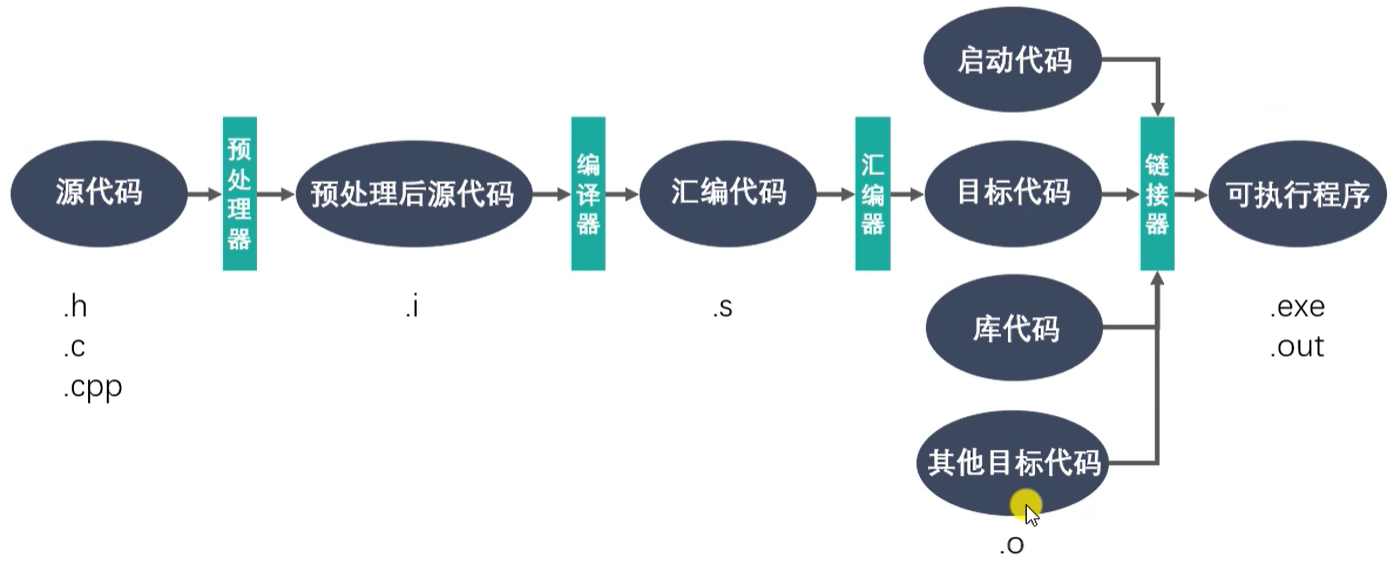
-
GCC常用参数选项
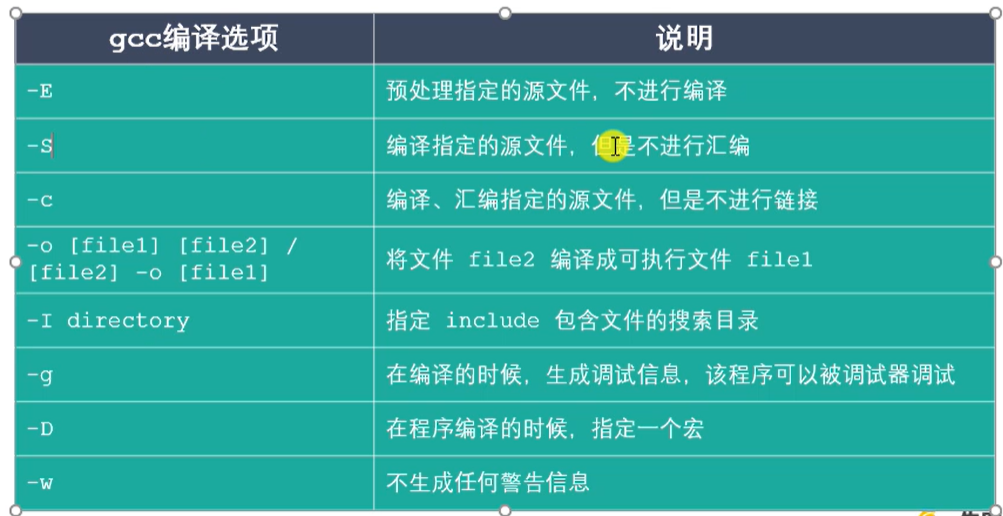
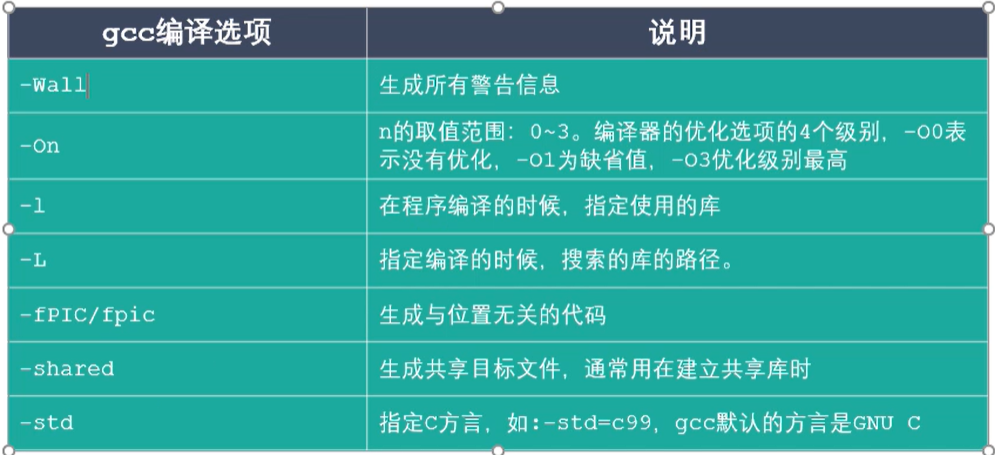
使用如:
1 2 3gcc test.c -E -o test.i #预处理源文件 gcc test.i -S -o test.s # 编译经过预处理的源文件test.i,但不进行汇编 gcc test.s -s -o a -
两种库文件:静态库 和 动态库(共享库)。区别:
- 静态库在程序的链接阶段被复制到程序中;
- 动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。
库的好处:1)代码保密;2)方便部署和分发。
-
静态库的制作
-
命名规则:
-
Linux:libxxx.a
- lib : 前缀(固定)
- xxx : 库的名字,自己起
- .a : 后缀(固定)
-
Windows:libxxx.lib
-
-
静态库制作
-
gcc获得.o文件; gcc -c xxx.c -I 路径
-
将.o文件打包,使用ar工具(archive)
ar rcs libxxx.a xxx.o xxx.o
- r 将文件插入备存文件中;
- c 建立备存文件;
- s 索引。
-
-
-
静态库的使用
- gcc main.c -o app -I ./include/ -L ./lib/ -l 库名称
- -I 头文件所在目录
- -l 搜索使用的库名称
- -L 库路径
-
动态库的制作和使用
-
制作
-
命名规则:
-
Linux:libxxx.so
- lib: 固定前缀
- xxx : 库的名字,自己起
- .so :固定后缀
在Linux下是一个可执行文件
-
Windows:libxxx.dll
-
-
动态库的制作
-
gcc得到.o文件,得到和位置无关的代码
gcc -c -fpic/-fPIC a.c b.c
-
gcc 得到动态库
gcc -shared a.o b.o -o libcalc.so
-
-
-
-
静态库 与 动态库的工作原理
-
静态库:GCC进行链接时,会把静态库中的代码打包到可执行程序中
-
动态库:GCC进行链接时,动态库的代码不会被打包到可执行程序中
-
程序启动之后,动态库会被动态加载到内存中,通过 **ldd(list dynamic dependencies)**命令检查动态库依赖关系
-
如何定位共享库文件呢?
当系统加载可执行代码的时候,能够知道其所依赖的库的名字,但是还需要知道绝对路径。此时需要系统的动态载入器来获取该绝对路径。对于elf格式的可执行程序,是由 ld-linux.so来完成的,它先后搜索elf文件的 DT_RPATH段 => 环境变量 LD_LIBRARY_PATH => /etc/ld.so.cache文件列表 => /lib/, /usr/lib 目录找到库文件后将其载入内存。【不推荐使用第三种方式,系统自带了文件,可能同名】
-
-
静态库 和 动态库 的对比
-
程序编译成可执行程序的过程
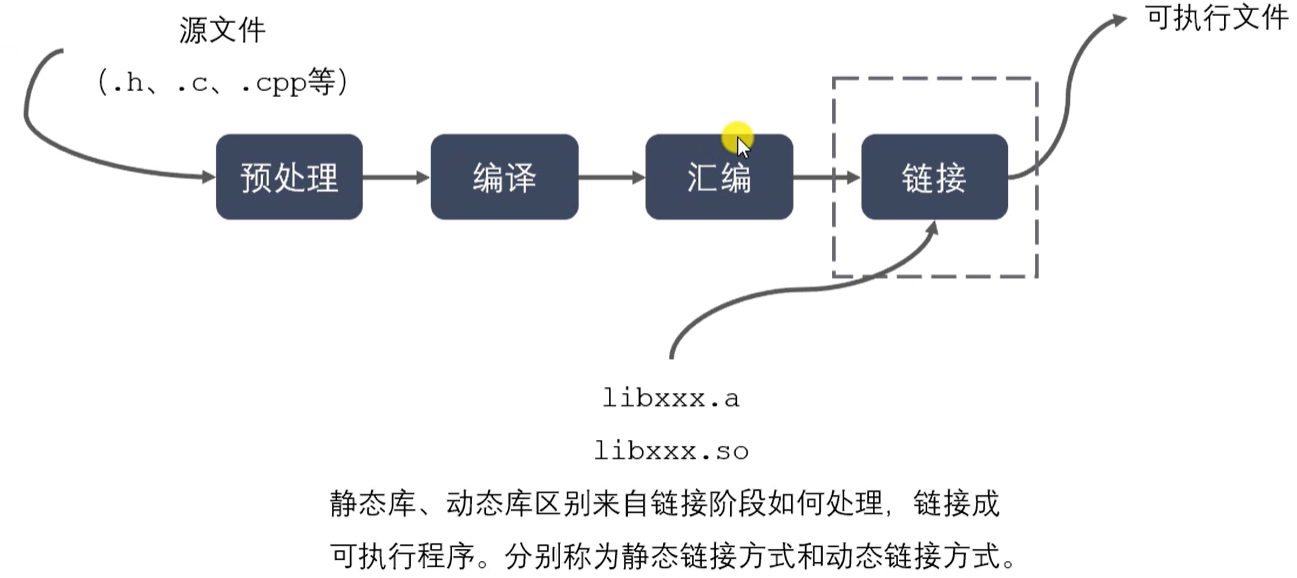
-
静态库制作过程
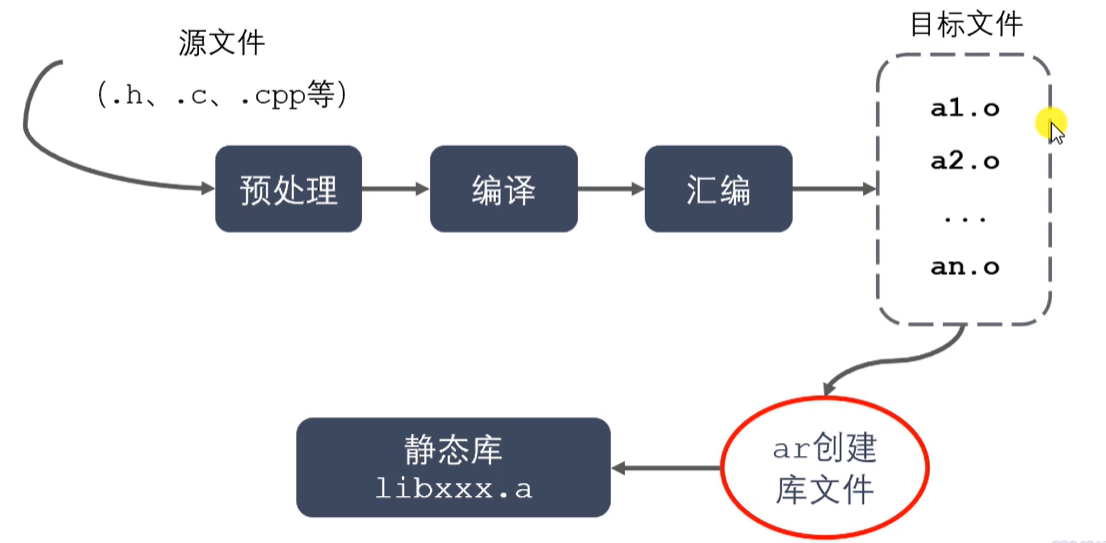
-
动态库制作过程 (-fpic/-fPIC 生成与位置无关的目标代码)
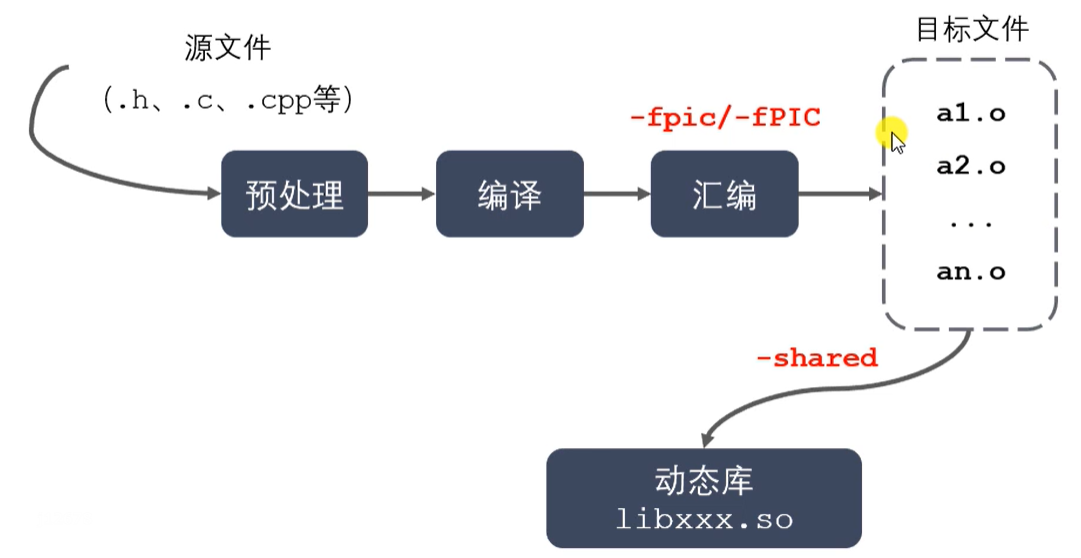
-
静态库的优缺点
- 优点:
- 静态库被打包到应用程序中加载速度快
- 发布程序无需提供静态库,移植方便;
- 缺点:
- 消耗系统资源,浪费内存;
- 更新、部署、发布麻烦
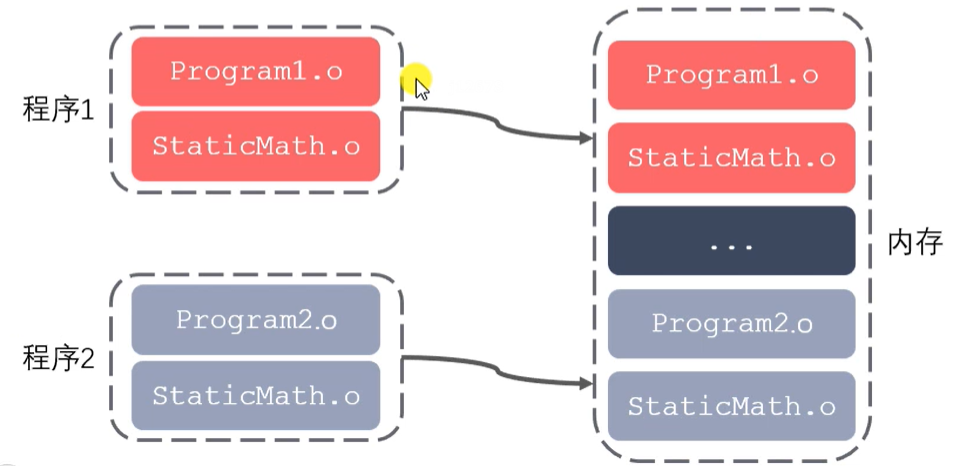
- 优点:
-
动态库的优缺点
- 优点:
- 可以实现进程间资源共享(共享库)
- 更新、部署、发布简单
- 可以控制何时加载动态库
- 缺点:
- 加载速度比静态库慢;
- 发布程序时需要提供依赖的动态库。
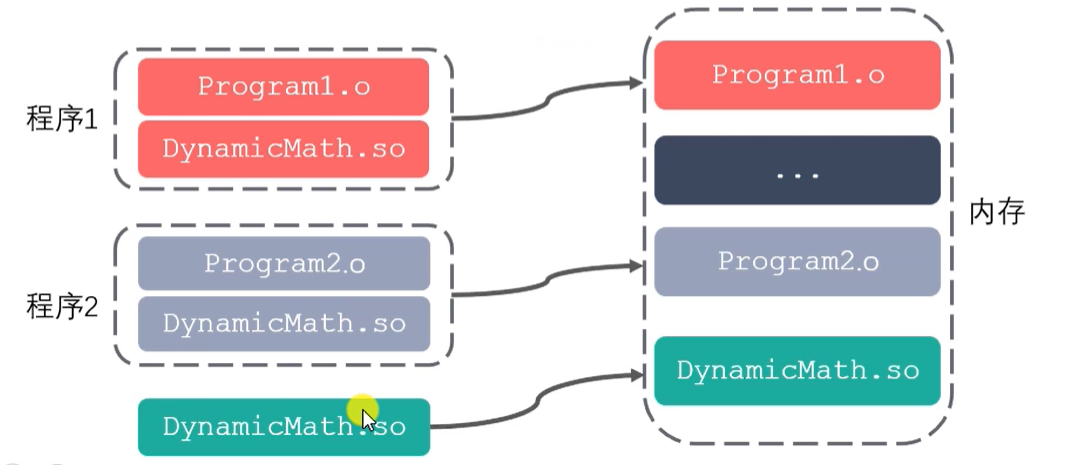
- 优点:
-
-
Makefile
Makefile文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至进行更复杂的功能操作,因为Makefile文件就像一个Shell脚本一样,也可以执行操作系统的命令。
好处:“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。 make 是一个命令工具,是一个解释 Makefile文件中指令的命令工具,一般来说,大多数的 IDE 都有这个命令, 比如Delphi 的make,Visual C++的 nmake, Linux下 GNU 的make。
-
Makefile文件命名和规则
-
文件命名
- makefile或者Makefile
-
Makefile 规则
-
一个Makefile 文件中可以有一个或者多个规则
目标 … : 依赖 …
命令(shell命令)
…
- 目标:最终要生成的文件(伪目标除外)
- 依赖:生成目标所需要的文件或是目标
- 命令:通过执行命令对依赖操作生成目标(命令前必须Tab缩进)
-
Makefile 中的其他规则一般都是为第一条规则服务的。
-
-
-
工作原理
-
命令在执行之前,需要先检查规则中的依赖是否存在
- 如果存在,执行命令;
- 如果不存在,向下检查其他的规则,检查有没有一个规则是用来生成这个依赖的,如果找到了,则执行该规则中的命令
-
检查更新,在执行规则中的命令时,会比较目标和依赖文件的时间;
- 如果依赖的时间比目标的时间晚,需要重新生成目标;
- 如果依赖的时间比目标的时间早,目标不需要重新更新,对应规则中的命令不需要被执行。
-
-
变量
-
自定义变量
- 变量名 = 变量值 var = hello
-
预定义变量
AR :归档维护程序的名称,默认值为ar
CC:C编译器的名称,默认值为cc
CXX:C++编译器的名称,默认值为g++
$@:目标的完整名称 # 自动变量只能在规则的命令中使用
$<:第一个依赖文件的名称
$^:所有的依赖文件
-
获取变量的值
$(变量名)

-
-
模式匹配

-
函数
-
$(wildcard PATTERN…)
-
功能:获取指定目录下指定类型的文件列表;
-
参数:PATTERN指的是某个或多个目录下的对应的某种类型的文件,如果有多个目录,一般使用空格间隔;
-
返回:得到的若干个文件的文件列表,文件名之间使用空格间隔
示例:
*$(wildcard .c ./sub/*.c)
返回值格式:a.c b.c c.c d.c e.c f.c
- $(patsubst
, , ) - 功能:查找
中的单词(单词以“空格”、“Tab”或“回车”“换行”分割)是否符合模式 ,如果匹配的话,则以 替换; 可以包括通配符 %, 表示任意长度大的字符串。如果中也包含 %,那么,中的这个 %将是中的那个%所代表的字串。(可以用 \来转移,以%来表示真实含义的%字符)- 返回:函数返回被替换过后的字符串;
示例:
$(patsubst %.c, %.o, x.c bar.c)
返回值格式:x.o bar.o
.PHONY 尾目标,可以用于最后的clean目标,用于删除 .o 目标文件
-
-
-
GDB调试
-
什么是GDB
一般来说,GDB主要帮助完成下面四个方面的功能:
- 启动程序,可以按照自定义的要求随心所欲的运行程序
- 可让被调试的程序在所指定的位置的断点处停住(断点可以是条件表达式)
- 当程序被停住时,可以检查此时程序中所发生的事;
- 可以改变程序,将一个BUG产生的影响修正从而测试其他BUG
-
准备工作
通常在为调试而编译时,会关掉编译器的优化选项
-o,并打开调试选项-g。另外,-Wall在尽量不影响程序行为的情况下选项打开所有warning,也可以发现许多问题,避免一些不必要的BUG。gcc -g -Wall program.c -o program
-g的作用是在可执行文件中加入源代码的信息,比如 可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证 gdb 能找到源文件。 -
GDB命令 —— 启动、退出、查看代码
-
启动和退出
gdb 可执行程序
quit
-
给程序设置参数 / 获取设置参数
set args 10 20
show args
-
GDB 使用帮助 help
-
查看当前文件代码
list/l (从默认位置显示)
list/l 行号(从指定的行显示)
list/l 函数名(从指定的函数显示)
-
查看非当前文件代码
list/l 文件名:行号
list/l 文件名:函数名
-
设置显示的行数
show list/listsize
set list/listsize行数
-
-
GDB命令——断点操作
-
设置断点
b/break 行号
b/break 函数名
b/break 文件名:行号
b/break 文件名:函数
-
查看断点
i/info b/break
-
删除断点
d/del/delete 断点编号
-
设置断点无效
dis/disable 断点编号
-
设置断点生效
ena/enable 断点编号
-
设置条件断点(一般用在循环的位置)
b/break 10 if i == 5
-
-
GDB命令——调试命令
-
运行GDB程序
start (程序停在第一行)
run(遇到断点才停)
-
继续运行,到下一个断点停
c/continue
-
向下执行一行代码(不会进入函数体)
n/next
-
变量操作
p/print 变量名(打印变量值)
ptype 变量名(打印变量类型)
-
向下单步调试(遇到函数进入函数体)
s/step
finish(跳出函数体)
-
自动变量操作
display num(自动打印变量的值)
i/info display
undisplay 编号
-
其他操作
set var 变量名=变量值
until (跳出循环)
-
-
-
文件IO
-
标准C库IO函数 (可以跨平台)
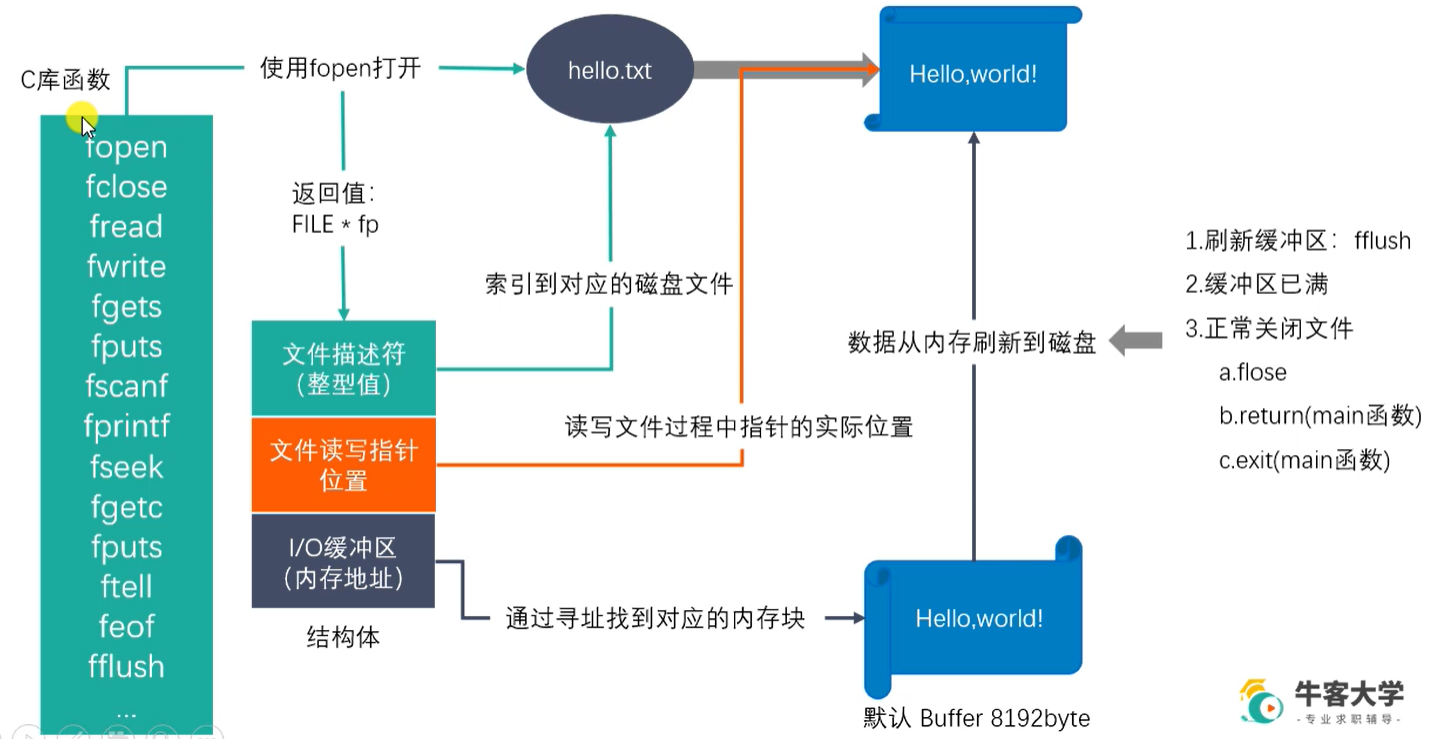
-
标准C库IO和Linux系统IO的关系 (调用和被调用)
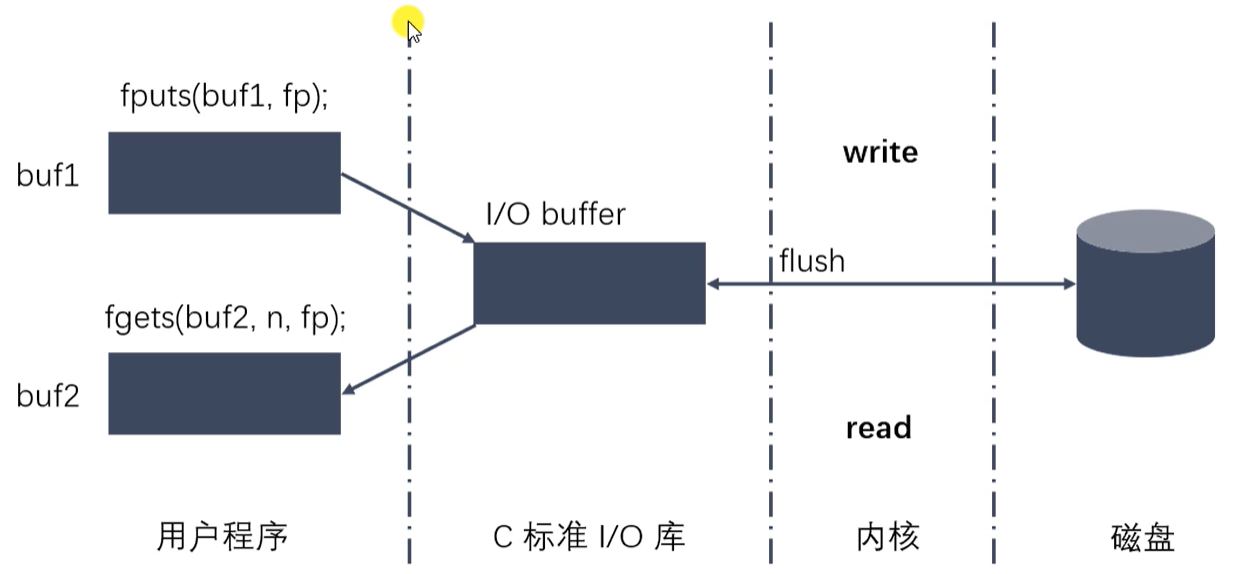
-
虚拟地址空间
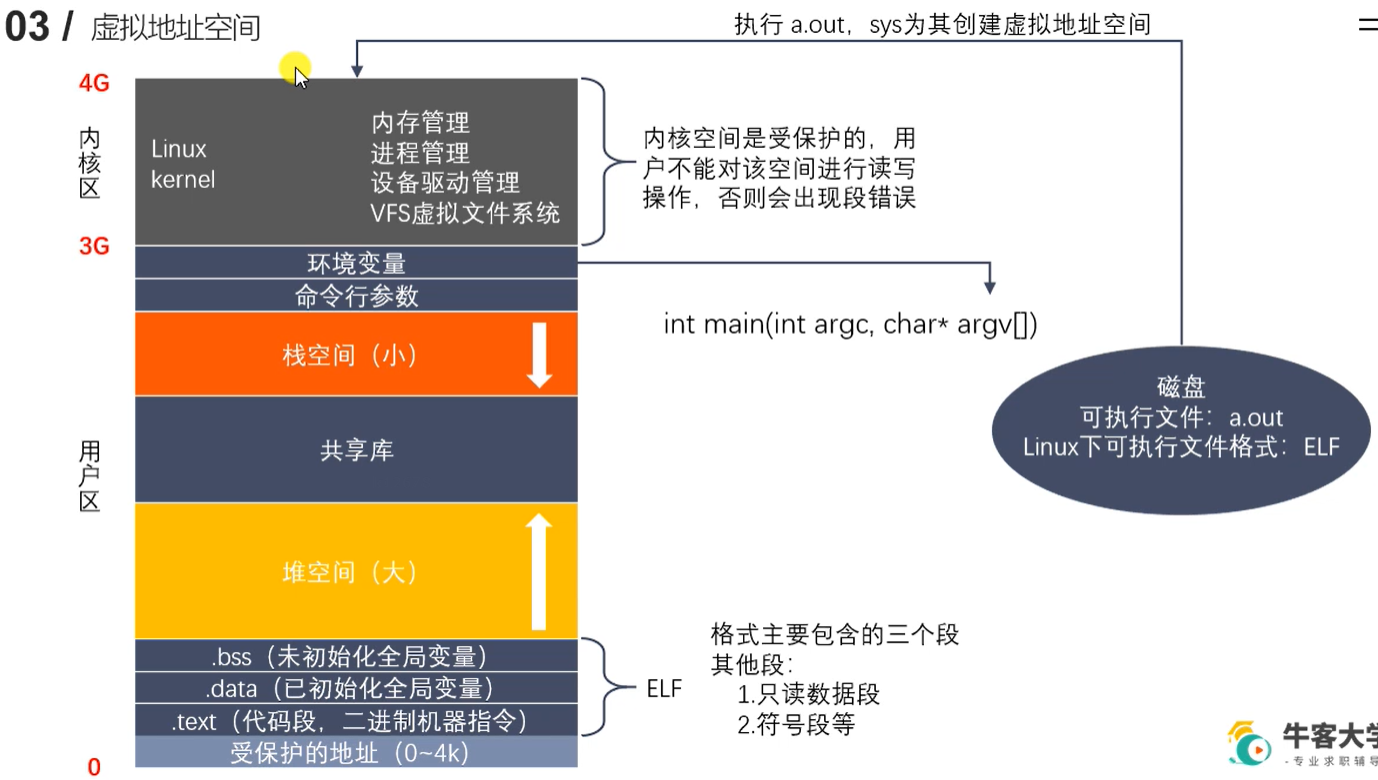
MMU(内存管理单元)将虚拟地址映射到物理地址。
-
文件描述符
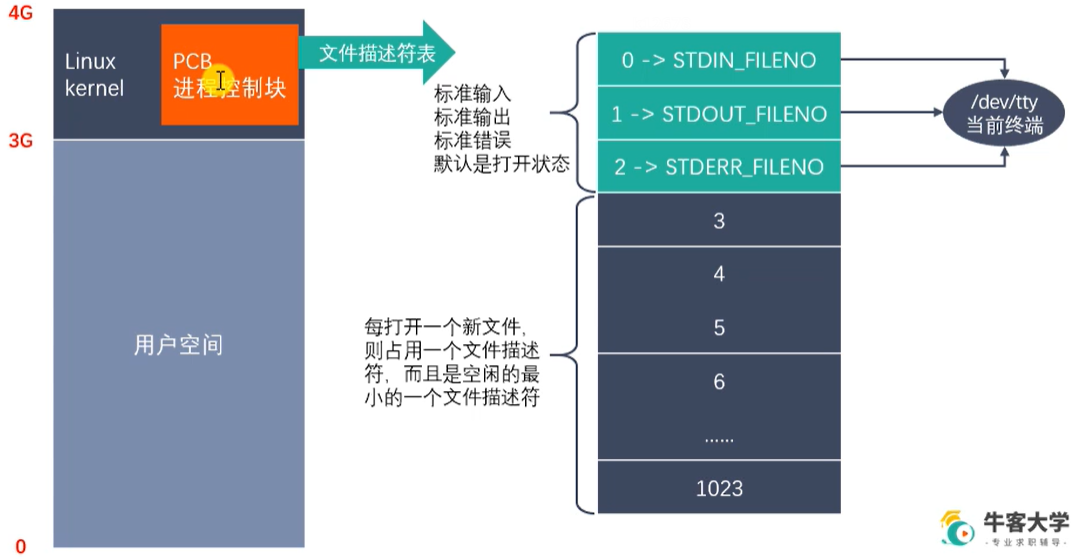
-
Linux 系统IO函数
标准C库的 API,使用
man 3 函数名查看,Linux 系统IO函数,使用man 2 函数名查看说明。1 2 3 4 5 6int open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); int close(int fd); ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count); off_t lseek(int fd, off_t offset, int whence); -
stat结构体

-
st_mode变量
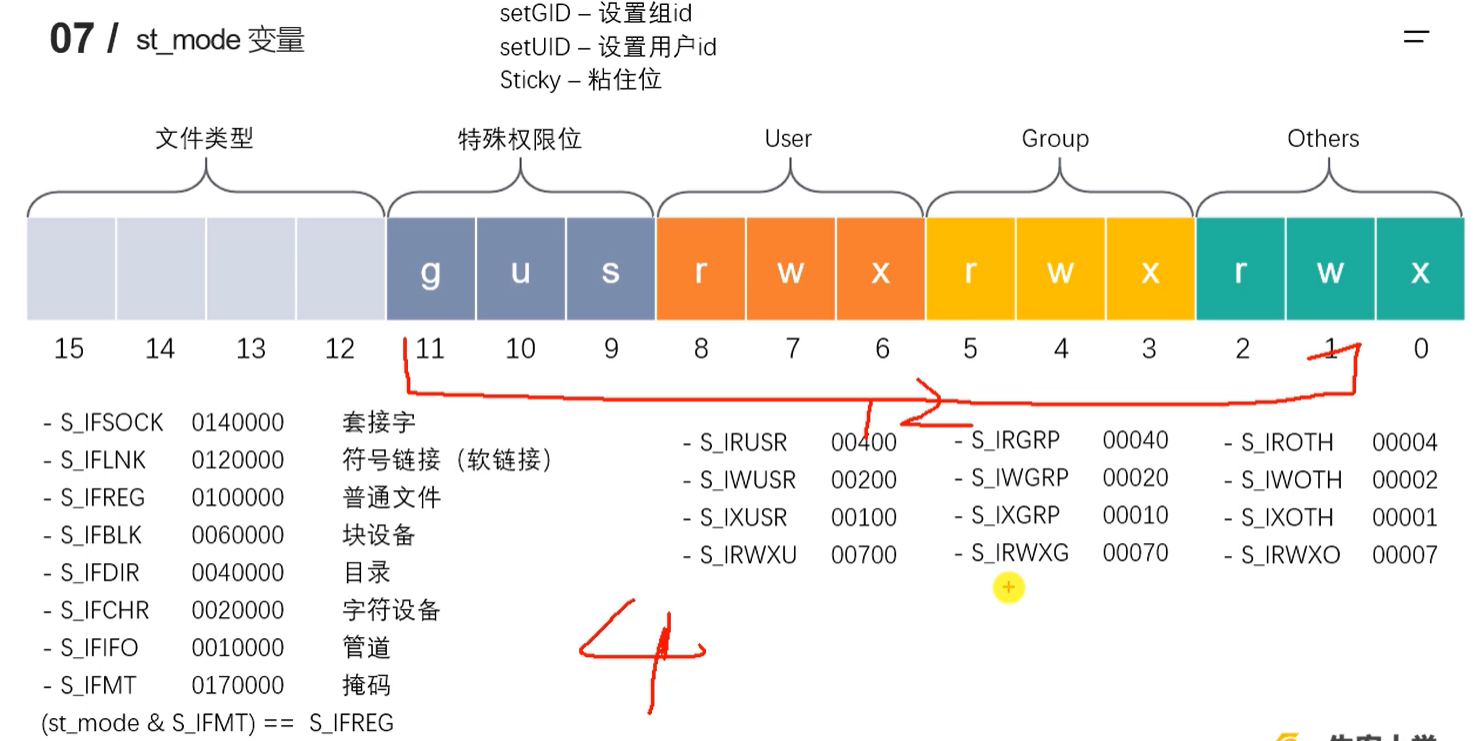
-
-
模拟实现
ls -l命令 (见lesson12的ls-l.c) -
文件属性操作函数
1 2 3 4int access(const char *pathname, int mode); int chmod(const char *filename, int mode); int chown(const char *path, uid_t owner, gid_t group); int truncate(const char *path, off_t length); // 缩减或扩展文件的尺寸至指定的大小 -
目录操作函数
1 2 3 4 5int mkdir(const char *pathname, mode_t mode); int rmdir(const char *pathname); int rename(const char *oldpath, const char *newpath); int chdir(const char *path); char *getcwd(char *buf, size_t size); -
目录遍历函数
|
|
dirent结构体和d_type

-
dup、dup2函数
1 2int dup(int oldfd); // 复制文件描述符 int dup2(int oldfd, int newfd); // 重定向文件描述符 -
fcntl函数
1 2 3int fcntl(int fd, int cmd, ... /* arg */); // 复制文件描述符, // 设置/获取文件的状态标志
2.Linux多进程开发
-
进程概述
-
程序和进程
- 程序(占用磁盘大小,不占用内存和CPU资源)是 包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程。(二进制格式标识、机器语言指令、程序入口地址、数据、符号表及重定位表、共享库和动态链接信息 和 其他信息。)
- 进程(占用内存资源和CPU资源) 是正在运行的程序的实例。
-
单道、多道程序设计
- 单道程序,即在计算机内存中只允许一个程序运行;
- 引入多道程序设计技术的 根本目的是 为了提高CPU的利用率。
-
时间片(timeslice)
- 又称为 “量子(quantum)”或“处理器片(processor slice)” 是操作系统分配给每个正在运行的微观上的一段CPU时间。
- 时间片 由 操作系统内核的调度程序分配给每个进程。
-
并行和并发
-
进程控制块(PCB)
-
Linux内核的进程控制块是 task_struct 结构体。
-
其内部成员(需要掌握的)有:

-
当前工作目录
-
umask掩码
-
文件描述符表,包含很多指向file结构体的指针
-
和信号相关的信息
-
用户id和组id
-
会话(session)和进程组
-
进程可以使用的资源上限(
ulimit -a)
-
-
-
进程状态转换
-
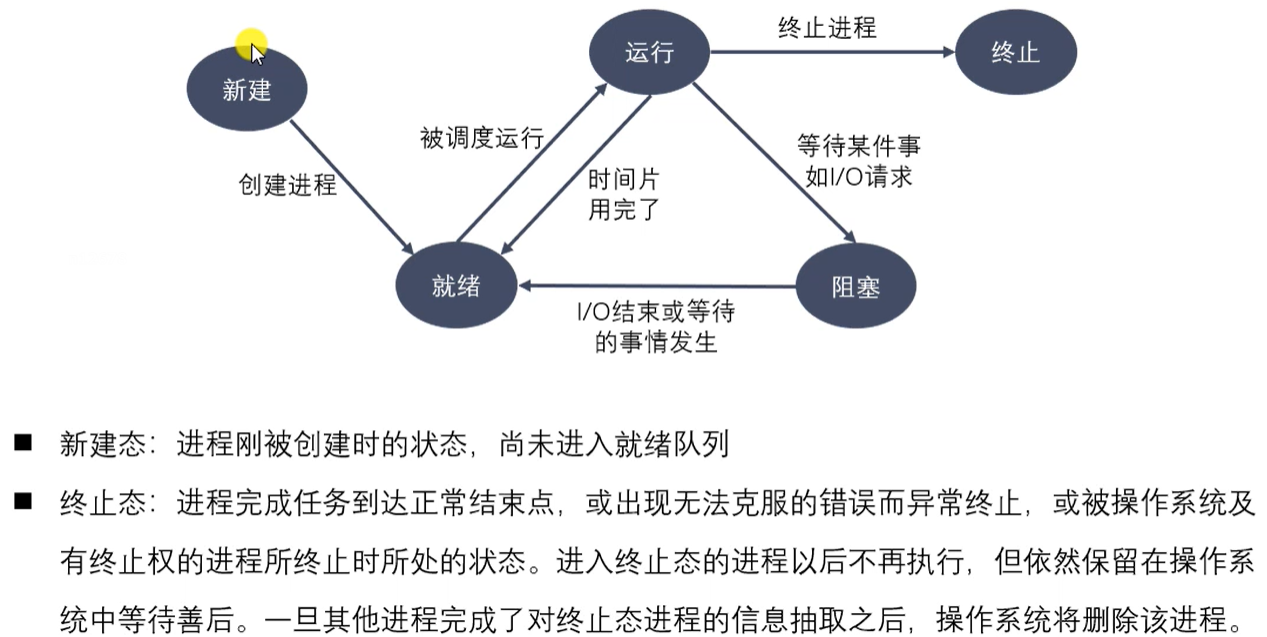
进程的状态
-
在三态模型中,分为三个基本状态:就绪态、运行态、阻塞态。

-
在五态模型中,分为新建态、就绪态、运行态、阻塞态、终止态。
-
-
进程相关命令
-
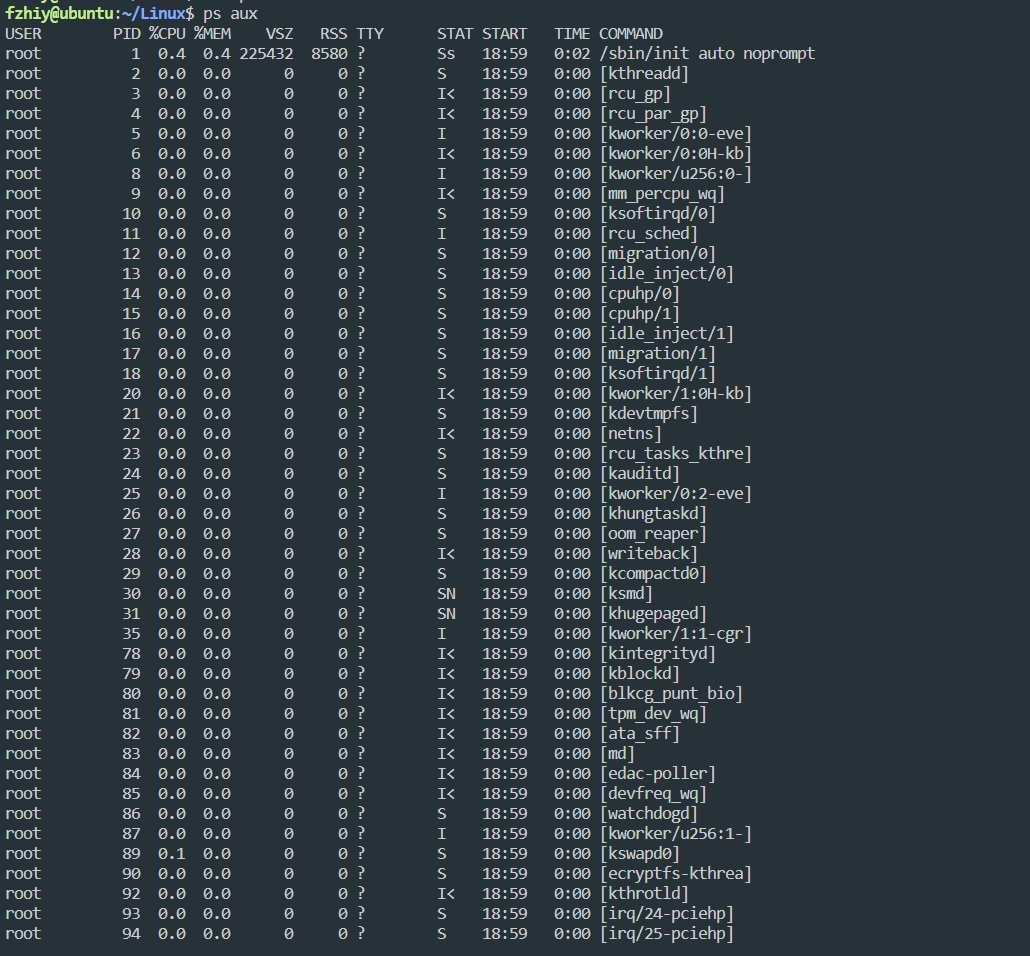
查看进程
-
ps aux / ajx
a:显示终端上的所有进程,包括其他用户的进程
u:显示进程的详细信息
x:显示没有控制终端的进程
j:列出与作业控制相关的信息
-
STAT参数意义
D 不可中断 Uninterruptible (usually IO)
R 正在运行,或 在队列中的进程
S(大写) 出于休眠状态
T 停止 或 被追踪
Z 僵尸进程
W 进入内存交换(从内核2.6开始无效)
X 死掉的进程
< 高优先级
N 低优先级
s(小写) 包含子进程
+ 位于 前台的进程组
-
实时显示进程状态
top
可以在使用
top命令时加上-d来指定显示信息更新的事件间隔,在top命令执行后,可以按以下按键对显示的结果进行排序:- M 根据内存使用量排序
- P 根据 CPU 占用率排序
- T 根据进程运行事件长短排序
- U 根据用户名来筛选进程
- K 输入指定的PID杀死进程
-
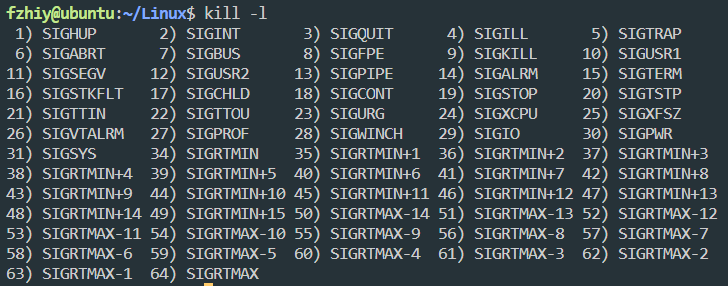
杀死进程
kill [-signal] pid
kill -l 列出所有信号
kill -SIGKILL 进程ID
kill -9 进程ID (强制杀死某个进程)
killall name 根据进程名杀死进程
-
-
-
进程号和相关函数

-
-
进程创建
-
系统允许一个进程创建子进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
1 2 3#include <sys/types.h> #include <unistd.h> pid_t fork(void);
父子进程指定代码的情况:
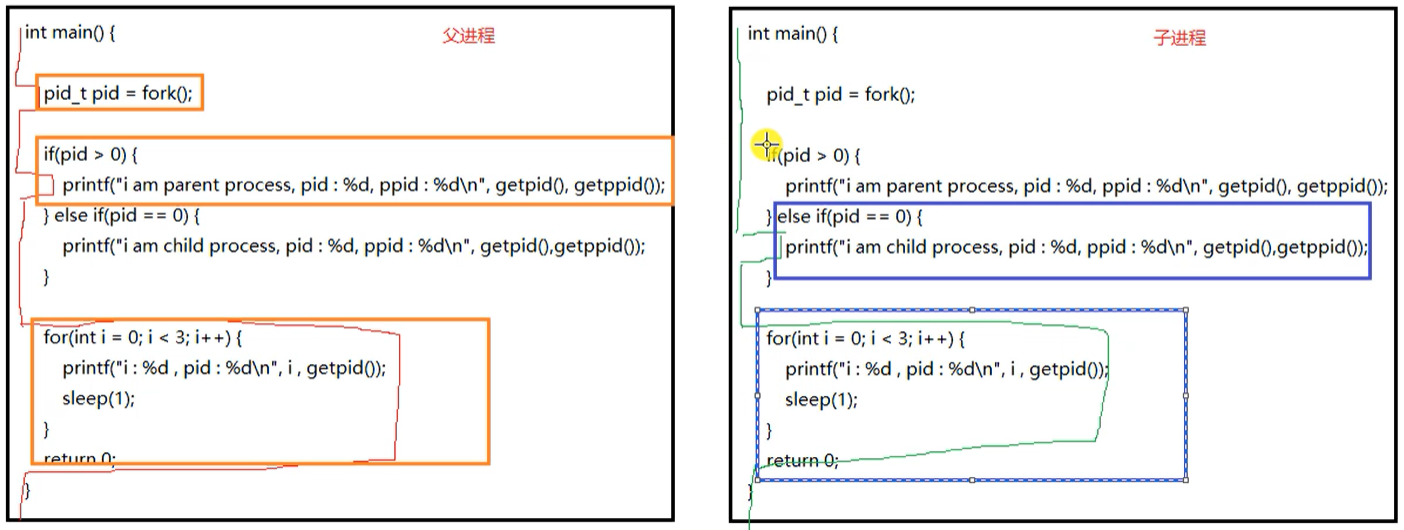
-
-
父子进程虚拟地址空间情况
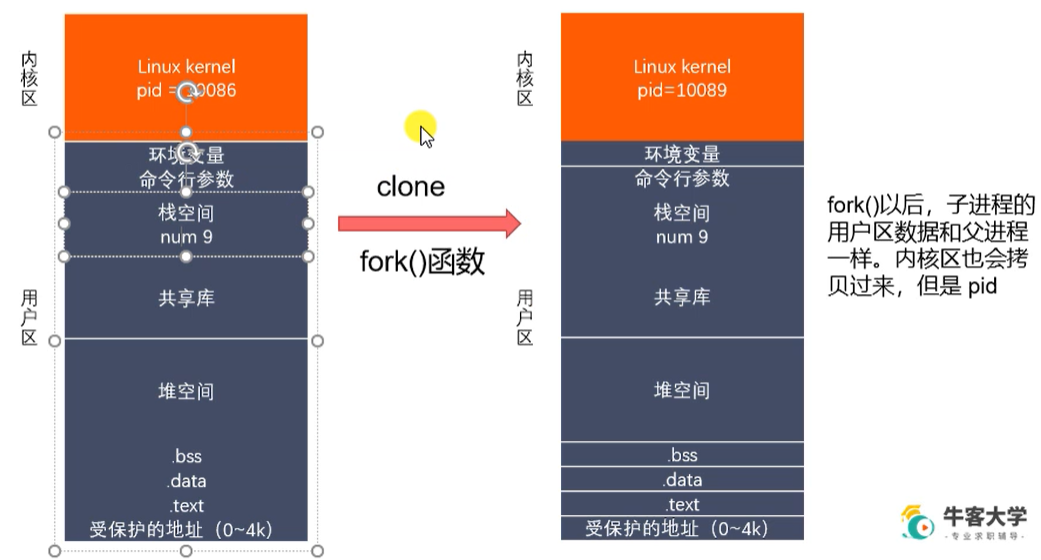
父子进程中的变量在各自的栈空间中,互不影响。
读时共享父进程虚拟地址空间,写时拷贝。
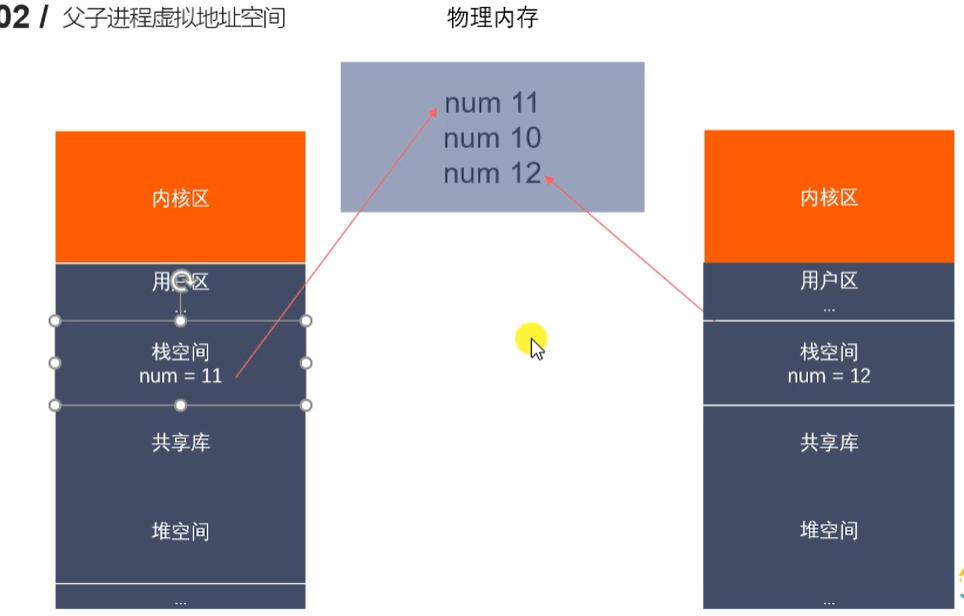
-
父子进程关系以及GDB多进程调试
-
父子进程关系

-
GDB多进程调试(面试考 调试命令)
使用GDB调试时,GDB默认只能跟踪一个进程,可以在fork函数调用之前,通过指令设置GDB调试工具跟踪父进程或子进程,默认跟踪父进程。
设置调试父进程或子进程:
set follow-fork-mode [parent(默认) | child]设置调试模式:
set detach-on-fork [on | off] 默认为on,表示调试当前进程时,其他的进程继续运行;如果为off,调试当前进程时,其他进程被GDB挂起。
查看调试的进程:info inferiors
切换当前调试的进程:inferior id
使进程脱离GDB调试:detach inferiors id
-
exec函数簇
-
作用:根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,换句话说,就是在调用进程内部内执行一个可执行文件。
-
exec函数簇的函数执行册成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程ID等一些表面上的信息仍保持原样,颇有些“三十六计”中的“金蝉脱壳”。看上去还是旧的躯壳,却已经注入了新的灵魂。只有调用失败了,他们才会返回-1,从原程序的调用点接着往下执行。
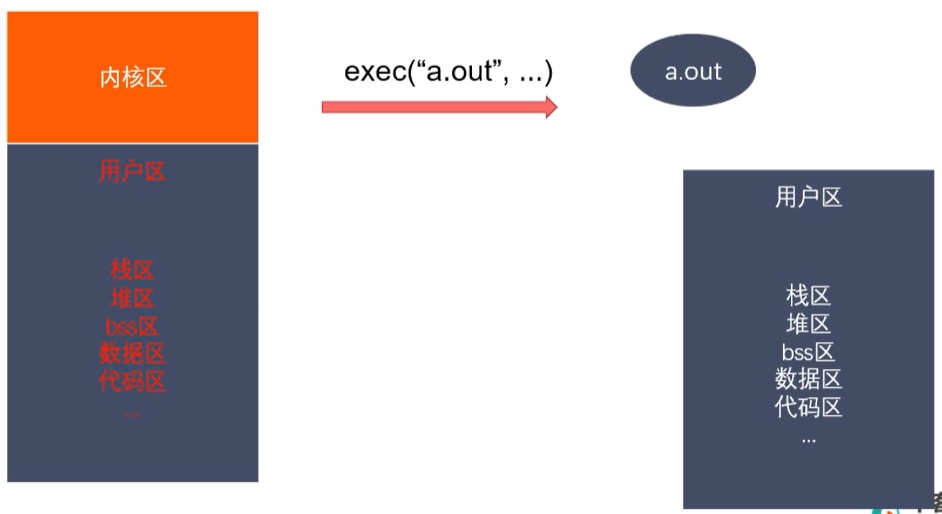

-
-
进程退出、孤儿进程、僵尸进程
-
进程退出
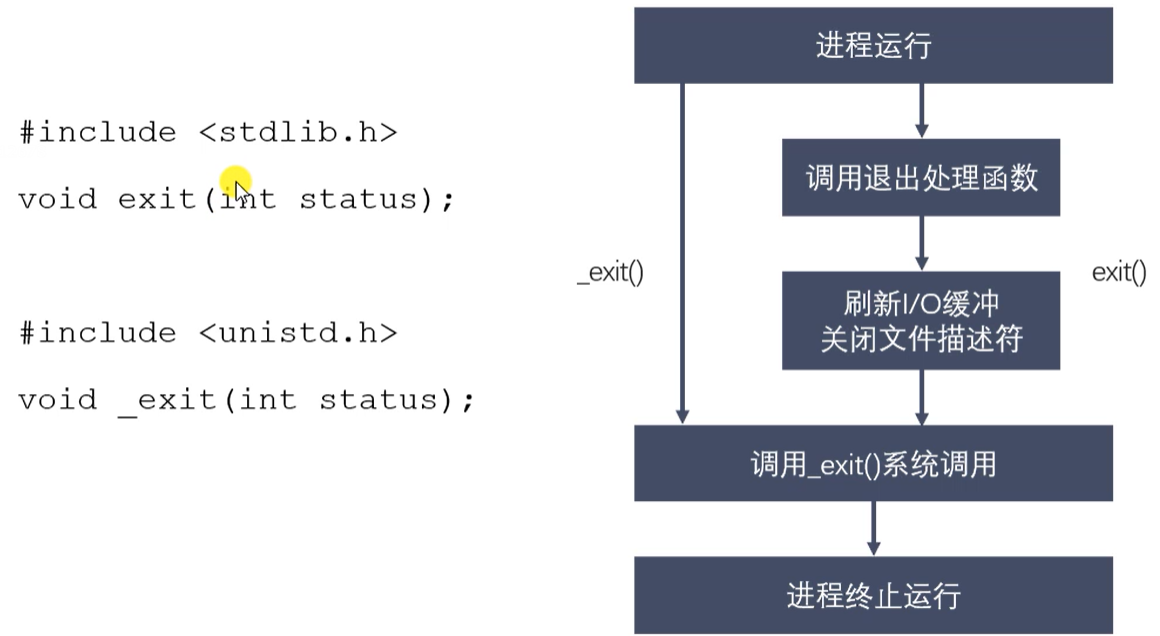
-
孤儿进程
- 父进程运行结束,但子进程还在运行(未运行结束),这样的子进程称为 孤儿进程(Orphan Process)
- 每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为 init, 而init进程会循环地 wait() 它的已退出地子进程。这样,当一个孤儿进程凄凉地结束其声明周期地时候,init进程就会代表党和政府出面处理它地一切善后工作。
- 因此孤儿进程并不会有什么危害。
-
僵尸进程
- 每个结束后,都会释放自己地址空间中的用户区数据,内核区的 PCB 没有办法自己释放掉,需要父进程去释放。
- 进程终止时,父进程尚未回收,子进程残留资源(PCB)存放在内核中,变成僵尸(Zombie)进程。
- 僵尸进程不能被
kill -9杀死。 - 这样会导致一个问题,如果父进程不调用wait() 或 waitpid() 的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免。
-
-
wait函数

-
进程回收

wait() 和 waitpid() 函数的功能一样,区别在于,wait()函数会阻塞,waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
注意:一次wait或waitpid 调用只能清理一个子进程,清理多个子进程应使用循环。
-
退出信息相关宏函数

-
-
waitpid函数
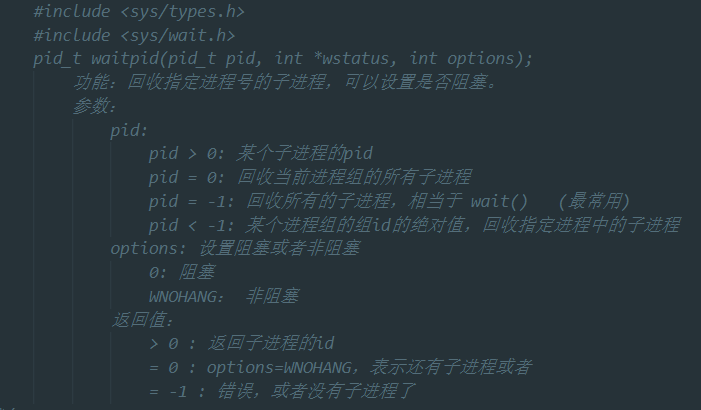
-
进程间通信简介

-
进程间通信(IPC,Inter Processes Communication)的目的:
- 数据传输:一个进程需要将它的数据发送给另一个进程;
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(他们)发生了某种事件(如进程终止时要通知父进程)。
- 资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供互斥和同步机制。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
-
Linux进程间通信的方式
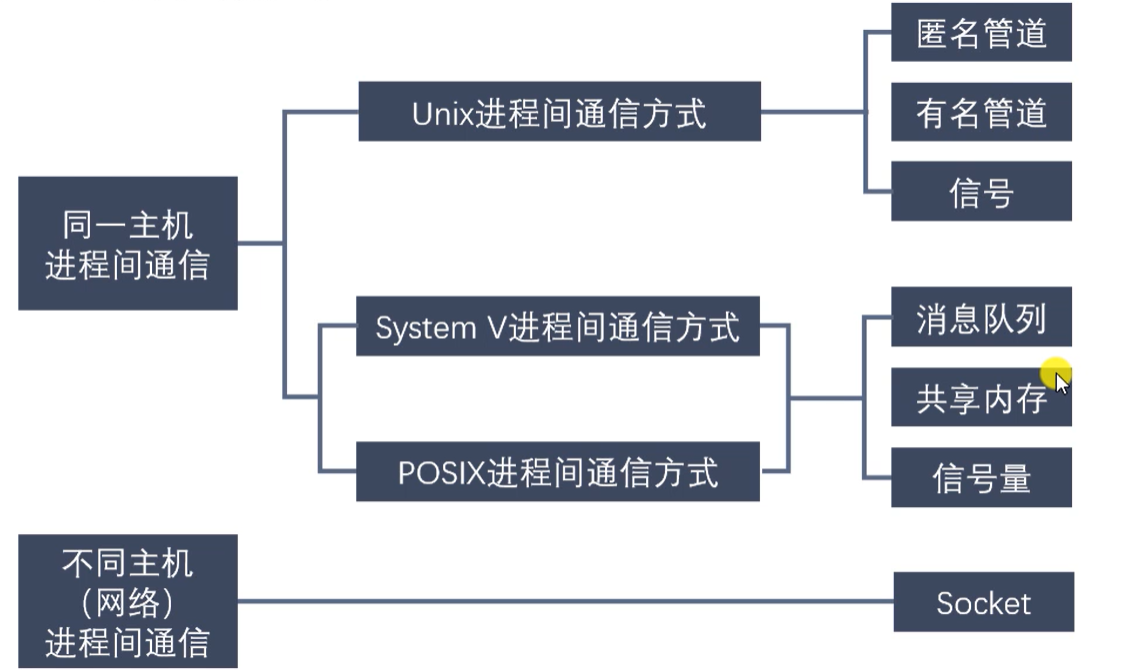
-
-
匿名管道概述
-
匿名管道
- 管道也叫 无名(匿名)管道,它是UNIX系统IPC的最古老形式,所有的UNIX系统都支持这种通信机制。
- 统计一个目录中文件的数目命令:
ls | wc -l,为了执行改命令,shell 创建了两个进程来分别执行ls和wc。

-
管道的特点

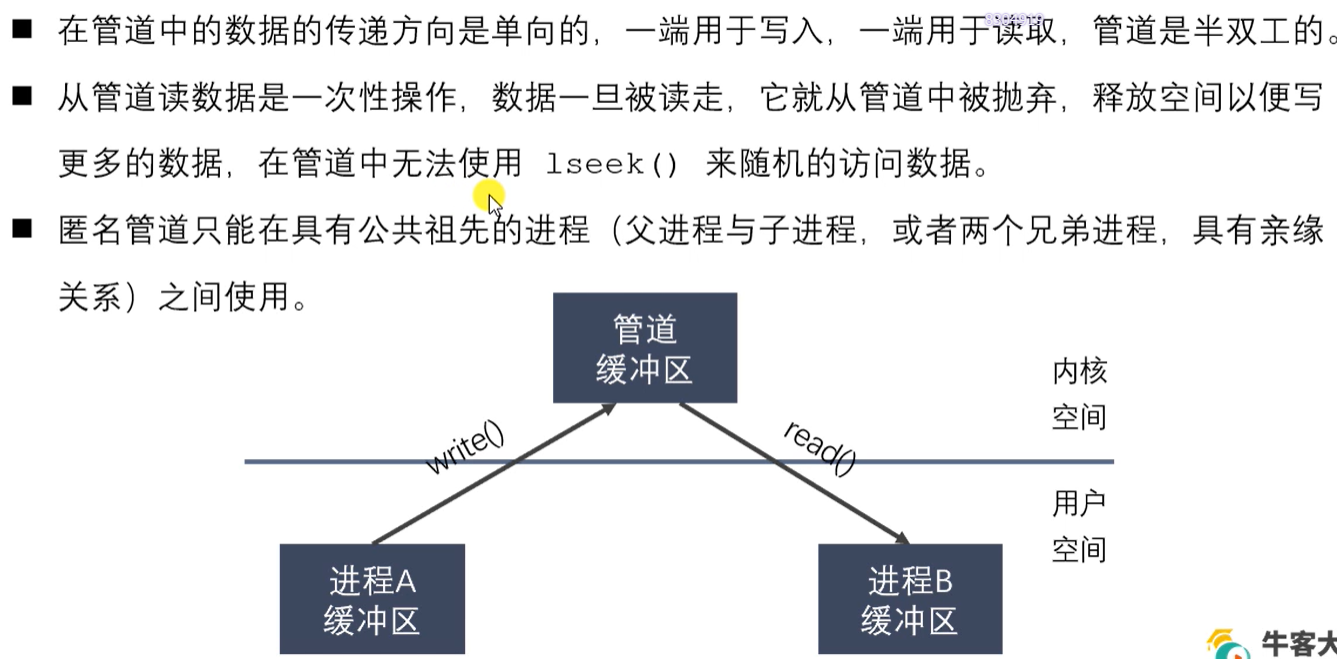
-
为什么可以使用管道进行进程间通信?
因为 父子进程 共享文件描述符。
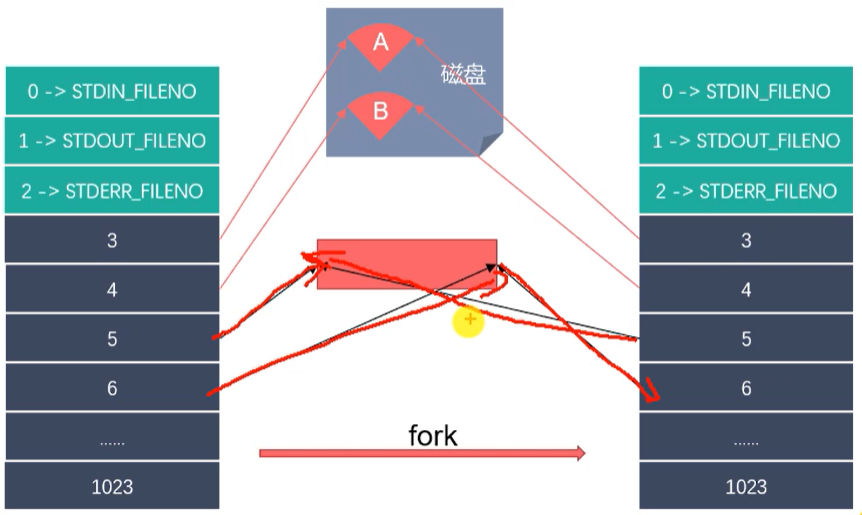
-
管道的数据结构
循环队列
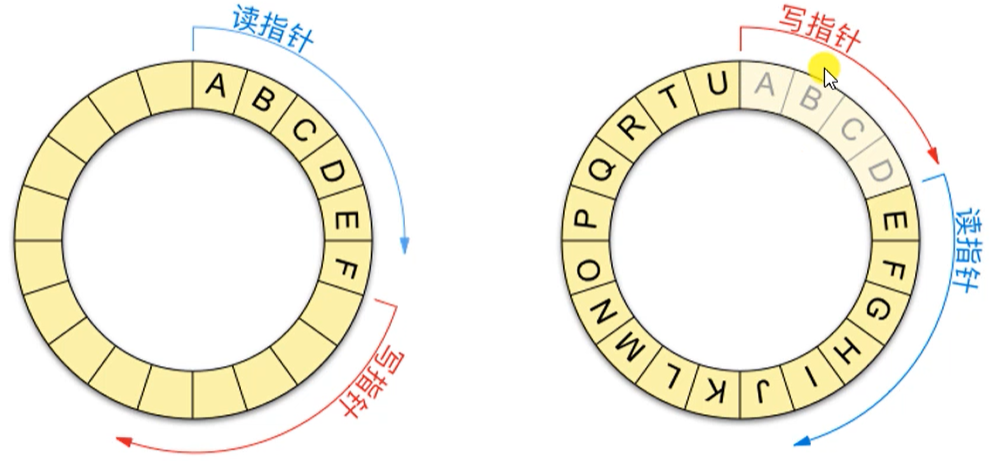
-
匿名管道的使用
-
创建匿名管道
1 2#include <unistd.h> int pipe(int pipefd[2]); -
查看管道缓冲大小命令
ulimit -a -
查看管道缓冲大小函数
1 2#include <unistd.h> long fpathconf(int fd, int name);
-
-
-
父子进程通过匿名管道通信
-
匿名管道通信案例
-
管道的读写特点和管道设置为非阻塞
-
有名管道介绍及使用
-
有名管道实现简单版聊天功能
3.Linux多线程开发
-
线程概述
- 概述
- 进程是 CPU **分配资源的最小单位,**线程是 操作系统调度执行的最小单位。
- 线程是轻量级的进程(LWP:Light Weight Process),在Linux环境下线程的本质仍是进程。
- 查看指定进程的LWP号:
ps -Lf pid
- 线程之间共享和非共享资源
- 共享资源
- 进程ID和父进程ID
- 进程组ID和会话ID
- 用户ID和用户组ID
- 文件描述符表
- 信号处置
- 文件系统的相关信息:文件权限掩码(umask)、当前工作目录
- 虚拟地址空间**(除栈、.text)**
- 非共享资源
- 线程ID
- 信号掩码
- 线程特有数据
- error变量
- 实时调度策略和优先级
- 栈,本地变量和函数的调用链接信息
- 共享资源
- 概述
-
创建线程
-
1 2int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
-
-
终止线程
-
连接已终止的线程
-
线程的分离
-
线程取消
-
线程属性
-
线程同步
-
互斥锁
-
死锁
-
读写锁
-
生产者和消费者模型
-
条件变量
-
信号量
4.Linux网络编程
-
网络结构模式
- C/S结构
- B/S结构
-
MAC地址、IP地址、端口
-
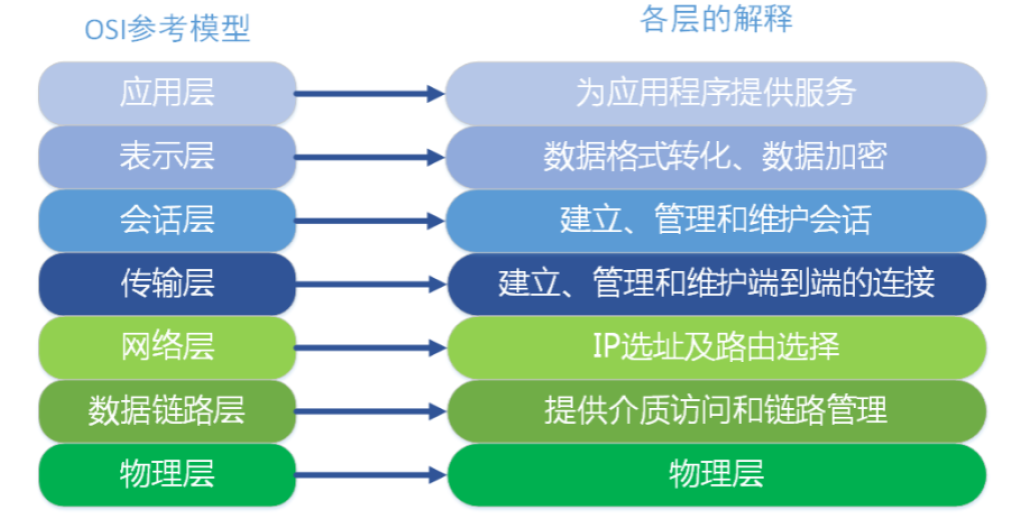
网络模型
-
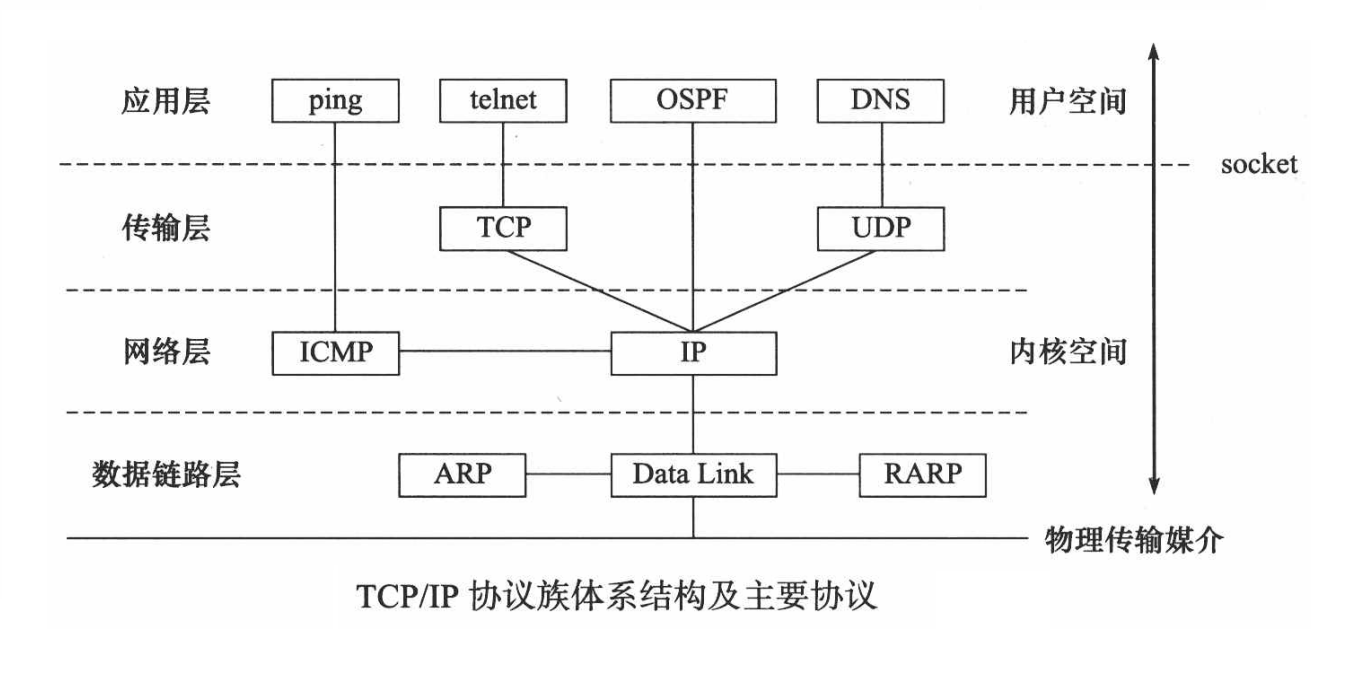
协议
-
网络通信的过程
-
socket介绍
-
字节序
-
字节序转换函数
-
socket地址
-
IP地址转换函数
-
TCP通信流程
-
socket函数
-
TCP通信实现(服务端)
-
TCP通信实现(客户端)
-
TCP三次握手
-
滑动窗口
-
TCP四次握手
-
多进程实现并发服务器
-
多线程实现并发服务器
-
TCP状态转换
-
半关闭、端口复用
-
IO多路复用简介
- I/O 多路复用使得程序能同时监听多个文件描述符,能够提高程序的性能,Linux 下实现 I/O 多路复用的系统调用主要有 select、poll 和 epoll。
-
select API介绍
-
select
select工作过程分析:

主旨思想:
- 首先要构造一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
- 调用一个系统函数(select),监听该列表中的文件描述符,直到这些描述符中的一个或者多个进行I/O操作时,该函数才返回。 a.这个函数是阻塞 b.函数对文件描述符的检测的操作是由内核完成的
- 在返回时,它会告诉进程有多少(哪些)描述符要进行I/O操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36// sizeof(fd_set) = 128 1024位 #include <sys/time.h> #include <sys/types.h> #include <unistd.h> #include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); - 参数: - nfds : 委托内核检测的最大文件描述符的值 + 1 - readfds : 要检测的文件描述符的读的集合,委托内核检测哪些文件描述符的读的属性 - 一般检测读操作 - 对应的是对方发送过来的数据,因为读是被动的接收数据,检测的就是读缓冲区 - 是一个传入传出参数 - writefds : 要检测的文件描述符的写的集合,委托内核检测哪些文件描述符的写的属性 - 委托内核检测写缓冲区是不是还可以写数据(不满的就可以写) - exceptfds : 检测发生异常的文件描述符的集合 - timeout : 设置的超时时间 struct timeval { long tv_sec; /* seconds */ long tv_usec; /* microseconds */ }; - NULL : 永久阻塞,直到检测到了文件描述符有变化 - tv_sec = 0 tv_usec = 0, 不阻塞 - tv_sec > 0 tv_usec > 0, 阻塞对应的时间 - 返回值 : - -1 : 失败 - >0(n) : 检测的集合中有n个文件描述符发生了变化 // 将参数文件描述符fd对应的标志位设置为0 void FD_CLR(int fd, fd_set *set); // 判断fd对应的标志位是0还是1, 返回值 : fd对应的标志位的值,0,返回0, 1,返回1 int FD_ISSET(int fd, fd_set *set); // 将参数文件描述符fd 对应的标志位,设置为1 void FD_SET(int fd, fd_set *set); // fd_set一共有1024 bit, 全部初始化为0 void FD_ZERO(fd_set *set);select缺点:
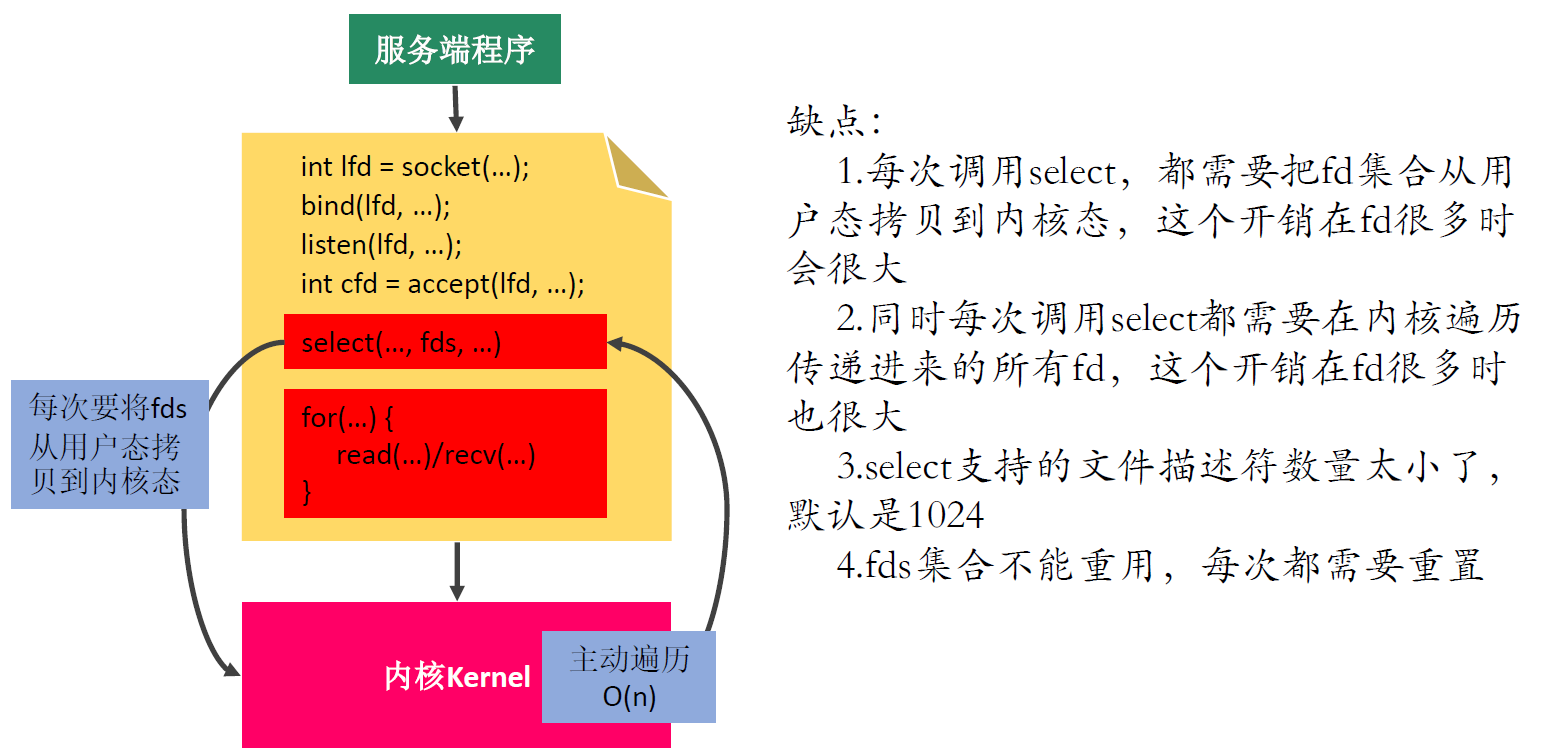
-
-
select代码编写
-
poll API介绍以及代码编写
-
poll
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20#include <poll.h> struct pollfd { int fd; /* 委托内核检测的文件描述符 */ short events; /* 委托内核检测文件描述符的什么事件 */ short revents; /* 文件描述符实际发生的事件 */ }; struct pollfd myfd; myfd.fd = 5; myfd.events = POLLIN | POLLOUT; int poll(struct pollfd *fds, nfds_t nfds, int timeout); - 参数: - fds : 是一个struct pollfd 结构体数组,这是一个需要检测的文件描述符的集合 - nfds : 这个是第一个参数数组中最后一个有效元素的下标 + 1 - timeout : 阻塞时长 0 : 不阻塞 -1 : 阻塞,当检测到需要检测的文件描述符有变化,解除阻塞 >0 : 阻塞的时长 - 返回值: -1 : 失败 >0(n) : 成功,n表示检测到集合中有n个文件描述符发生变化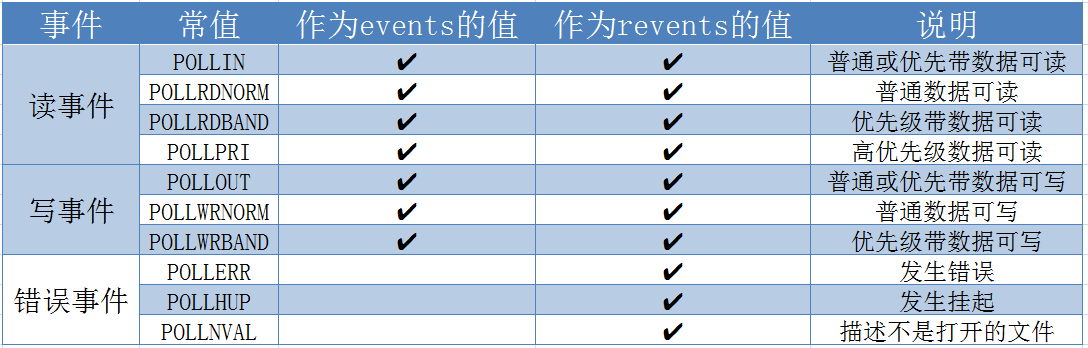
-
-
epoll API介绍
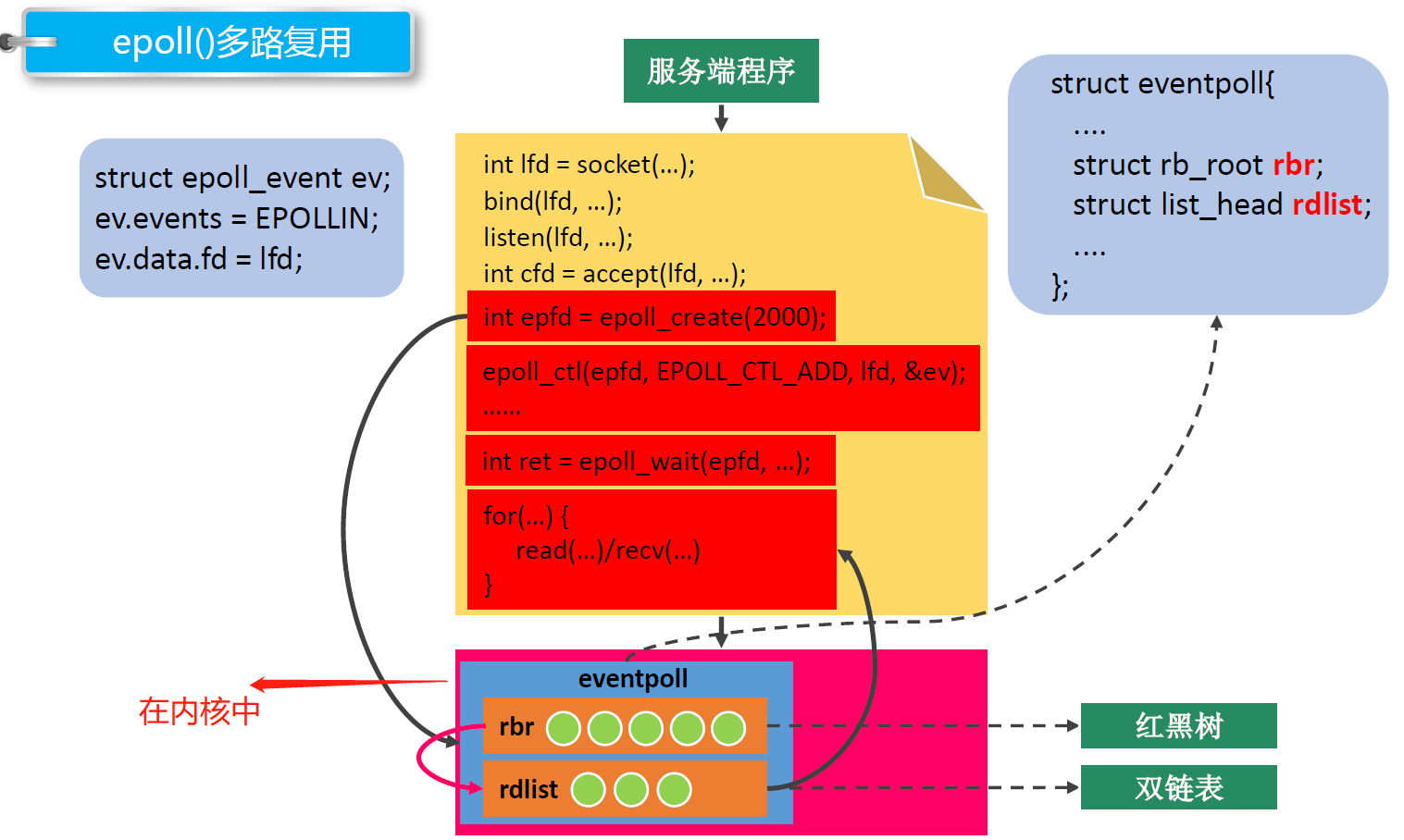
-
epoll
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51#include <sys/epoll.h> // 创建一个新的epoll实例。在内核中创建了一个数据,这个数据中有两个比较重要的数据,一个是需要检测的文件描述符的信息(红黑树),还有一个是就绪列表,存放检测到数据发送改变的文件描述符信息(双向链表)。 int epoll_create(int size); - 参数: size : 目前没有意义了。随便写一个数,必须大于0 - 返回值: -1 : 失败 > 0 : 文件描述符,操作epoll实例的 typedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t; struct epoll_event { uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ }; 常见的Epoll检测事件: - EPOLLIN - EPOLLOUT - EPOLLERR // 对epoll实例进行管理:添加文件描述符信息,删除信息,修改信息 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); - 参数: - epfd : epoll实例对应的文件描述符 - op : 要进行什么操作 EPOLL_CTL_ADD: 添加 EPOLL_CTL_MOD: 修改 EPOLL_CTL_DEL: 删除 - fd : 要检测的文件描述符 - event : 检测文件描述符什么事情 // 检测函数 int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); - 参数: - epfd : epoll实例对应的文件描述符 - events : 传出参数,保存了发送了变化的文件描述符的信息 - maxevents : 第二个参数结构体数组的大小 - timeout : 阻塞时间 - 0 : 不阻塞 - -1 : 阻塞,直到检测到fd数据发生变化,解除阻塞 - > 0 : 阻塞的时长(毫秒) - 返回值: - 成功,返回发送变化的文件描述符的个数 > 0 - 失败 -1
-
-
epoll代码编写
-
epoll的两种工作模式
-
LT 模式 (水平触发)
假设委托内核检测读事件 -> 检测fd的读缓冲区 读缓冲区有数据 - > epoll检测到了会给用户通知 a.用户不读数据,数据一直在缓冲区,epoll 会一直通知 b.用户只读了一部分数据,epoll会通知 c.缓冲区的数据读完了,不通知
LT(level - triggered)是缺省的工作方式,并且同时支持 block 和 no-block socket。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的 fd 进行 IO 操作。如果你不作任何操作,内核还是会继续通知你的。
-
ET 模式(边沿触发)
假设委托内核检测读事件 -> 检测fd的读缓冲区 读缓冲区有数据 - > epoll检测到了会给用户通知 a.用户不读数据,数据一致在缓冲区中,epoll下次检测的时候就不通知了 b.用户只读了一部分数据,epoll不通知 c.缓冲区的数据读完了,不通知
ET(edge - triggered)是高速工作方式,只支持 no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了。但是请注意,如果一直不对这个 fd 作 IO 操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once)。ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。epoll工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
-
-
UDP通信实现
-
广播
-
组播
-
本地套接字通信
5.项目实战与总结
- 阻塞和非阻塞、同步和异步
- Unix、Linux上的五种IO模型
- Web服务器简介以及HTTP协议
- 服务器编程基本框架和两种高效的事件处理模式
参考资料
- 牛客网——C++高薪面试项目 https://www.nowcoder.com/study/live/504
文章作者 fzhiy
上次更新 2022-04-20