李宏毅机器学习笔记—Meta Learning

文章目录
概述
Life-long Learning 终身学习:one model for all the tasks (同一个模型在做学习)
Meta Learning元学习:How to learn a new model (不同的任务做不同的模型,利用过去的学习经验能够使之后的学习能够更快)
Meta Learning 中 机器之所以能够学习得更快并不是依赖于旧任务中已获取的“知识”,而是机器到了如何去获取知识的方法,并将这一方法应用到新任务当中,从而更快地提升学习效率。
Meta Learning 是一门 研究如何让机器学会更好地学习的新兴研究方向。
建模思路
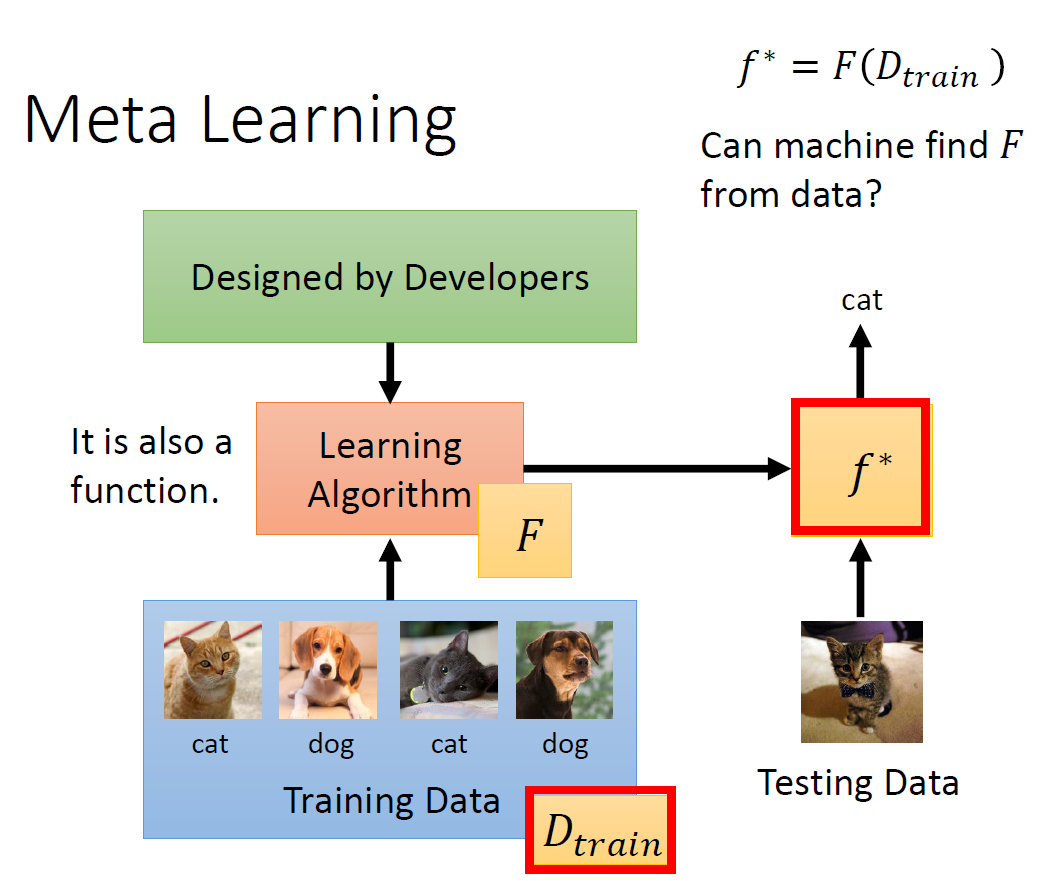
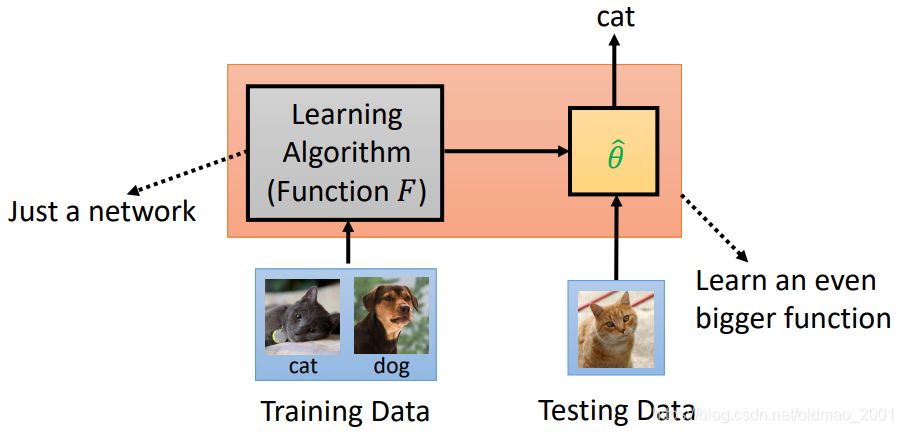
首先,上图描述的是传统机器学习在做的事情——由人来设计一套学习算法,然后这个算法会输入一堆训练资料,通过长时间的训练得到算法里的参数,这堆参数拟合出一个函数$f^$,然后用测试资料来测试这个$f^$,如果效果达标就证明机器学到了该特定任务的实现函数$f^*$。而Meta Learning做的事情与上述描述不同的地方在于,将其中由人来设计学习方法的过程,改成了由机器来设计一套学习方法。

从文字含义上理解,Meta Learning是Machine Learning的一个升级版,因为同样是输入都是训练数据(为了便于理解,不细分),而目的上Meta Learning能够达到Machine Learning的更高一级(找一个函数f – Meta Learning)。
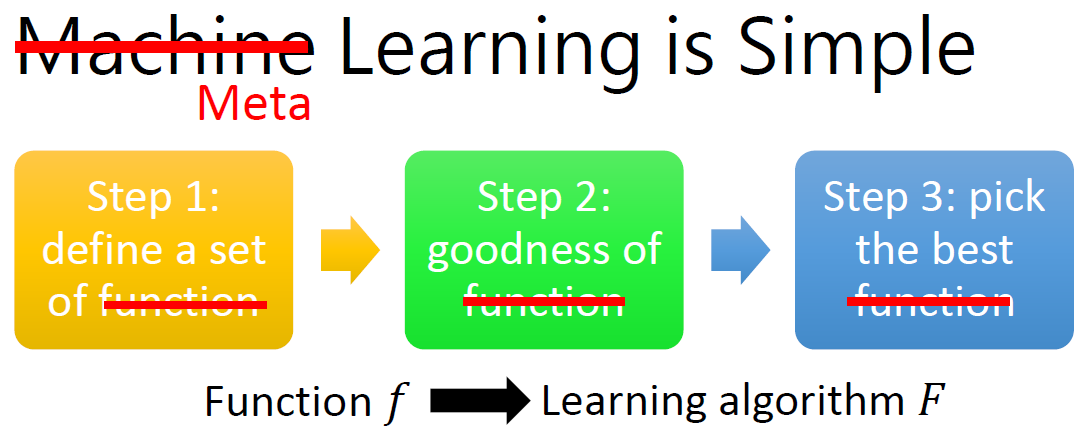
因此,上图中 由Machine Learning => Meta Learning 的变化便是将function f 改为 learning algorithm F。
Meta Learning步骤
- 定义一套学习算法
- 定义函数F的好坏(即函数F的损失函数定义)
- 如何降低函数F的损失? (见MAML算法实例)
定义一套学习步骤(神经网络为例)
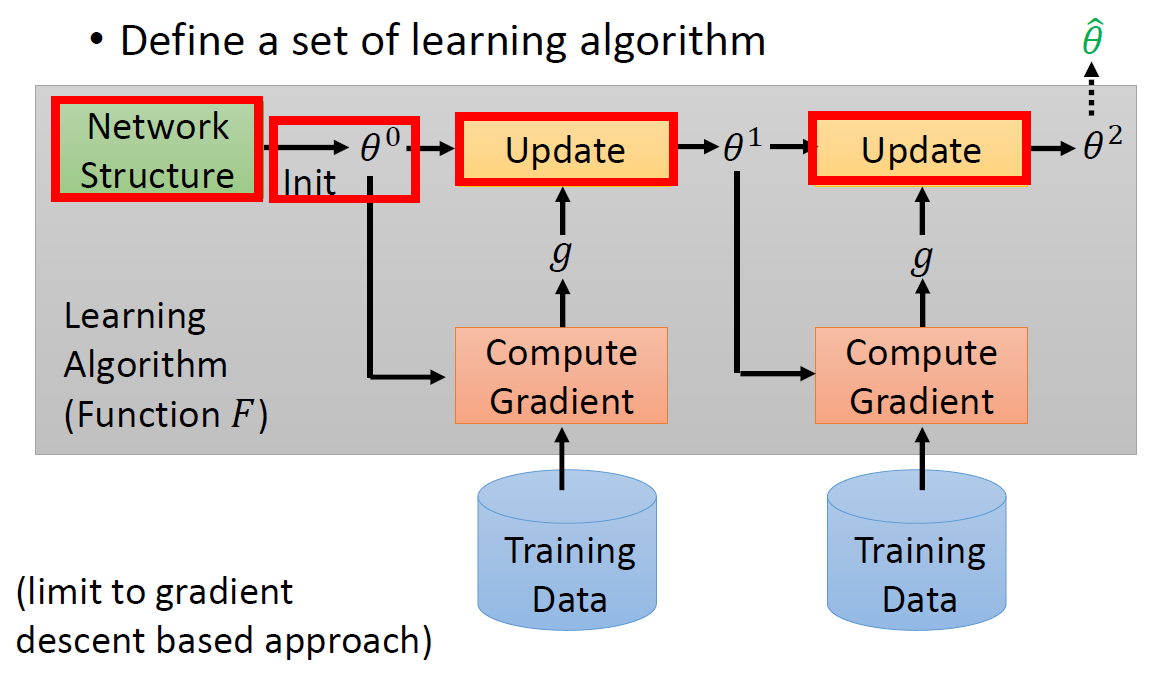
流程简述为:
设计一个网络架构 -> 参数初始化 -> 读入训练数据批次 -> 计算梯度 -> 基于梯度(每一步的gradient g不一样)更新参数 -> 进入下一轮训练 -> ……。
对于每个具体任务来说,它的全部算法流程构成了一个$f^$. **上图中红色方框内任意一个不同时,就是一个新的$f^$**。 所以,针对梯度下降算法来说,Meta Learning的最终学习成果是在给定训练资料的条件下,机器能够找到针对这笔资料的SGD最佳训练流程($f^_{best}$)。前面提到的Meta Learning准备的$f^$,实际上是 由包含尽量多和丰富的组合方式的不同训练流程组成的。
定义函数F的损失函数
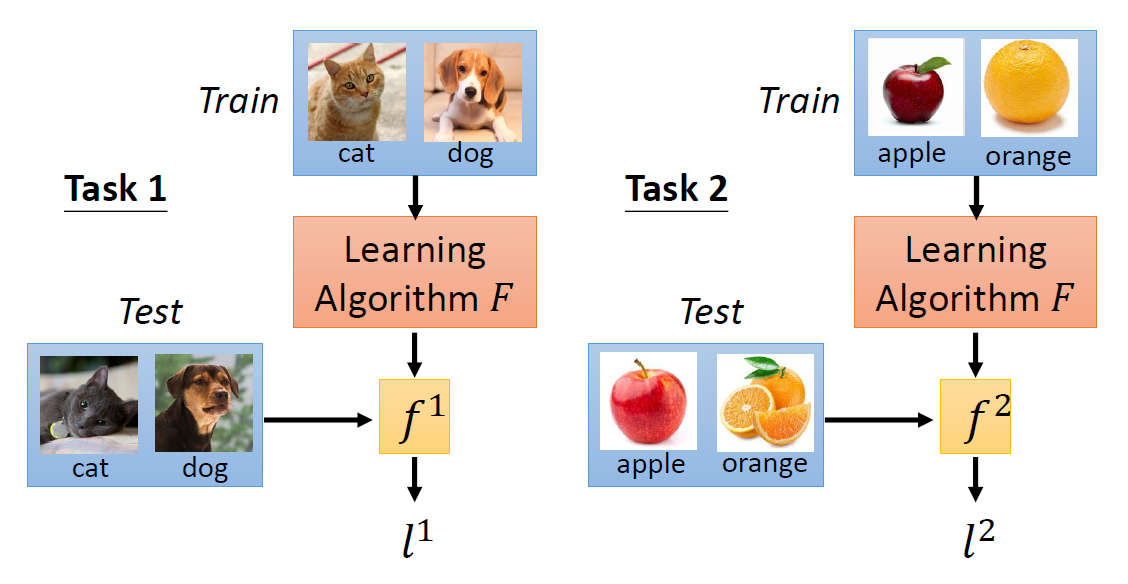
如上图所示,在Task1中,函数F学习到的训练算法是 $f^1$,而Task1中的测试集在$f^1$的测试结果被记作在Task1上的损失值$l^1$(注意测试结果不仅仅可以是分类任务中的分类损失,也可以定义为损失下降的速率等等,取决于我们希望F学习到什么样的算法效果);同理,在Task2中的测试集在$f^2$上的测试结果记作在Task2上的损失值$l^2$。最终,函数F的损失函数就定义为所有Task上的损失的总和:
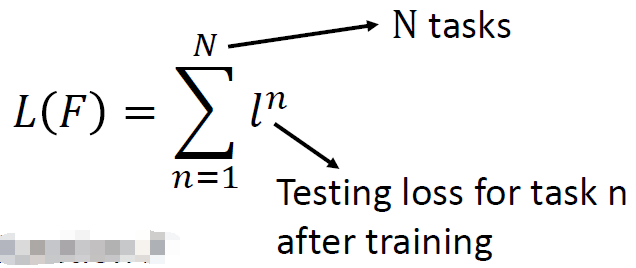
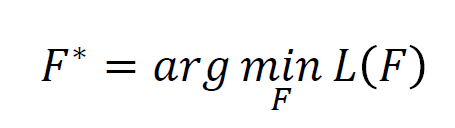
说明:
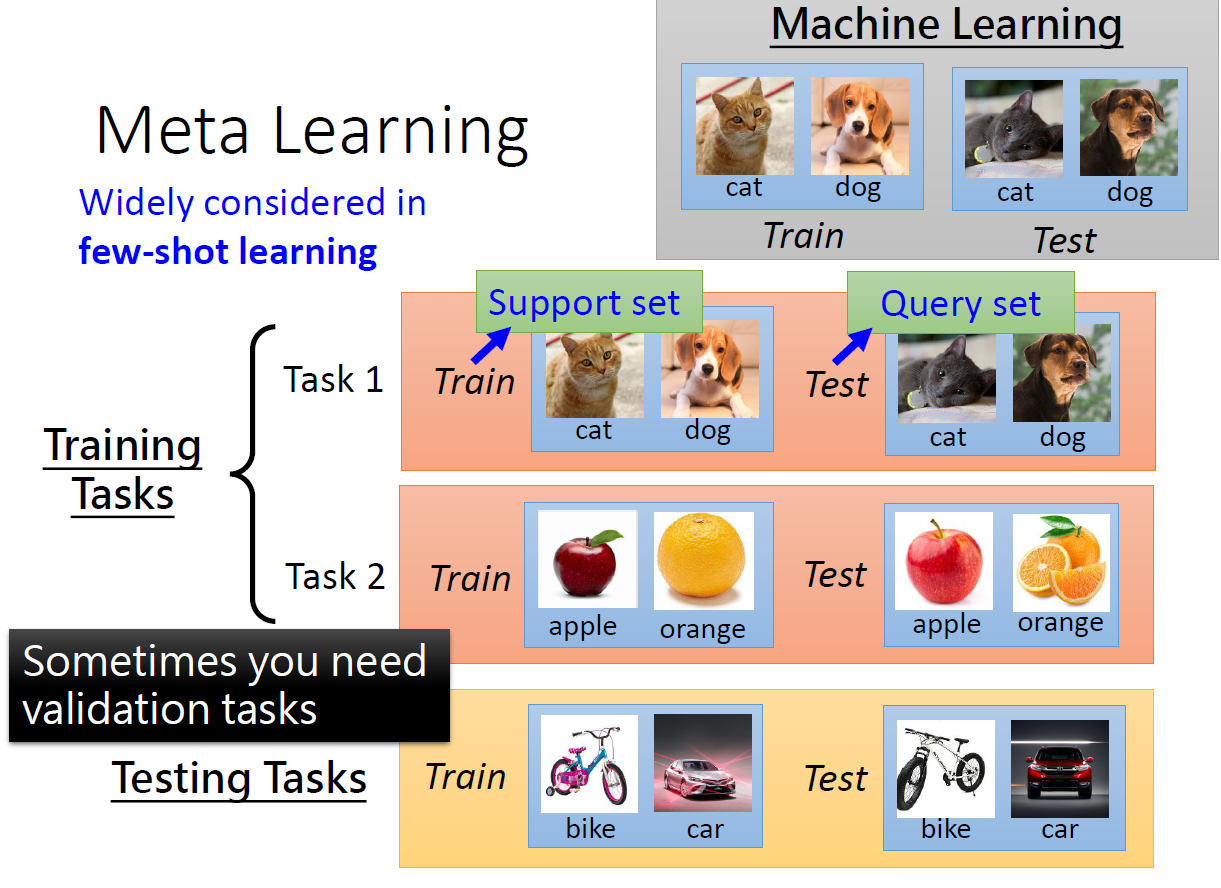
- 元学习中有多个任务,如果每个任务有很多数据,那么训练时间会很长。元学习每个任务的数据不多,而在few-shot learning中通常一个类别只有很少的样本,因此元学习通常与小样本学习搭配使用。
- 为了
和机器学习区分开方便写论文,在meta learning任务中,训练和测试数据分别称为Support Set和Query Set。 - 和机器学习一样,当元学习的训练任务很多的时候,可以把其中一部分切分出来作为验证集来调整参数获取更小的loss值。
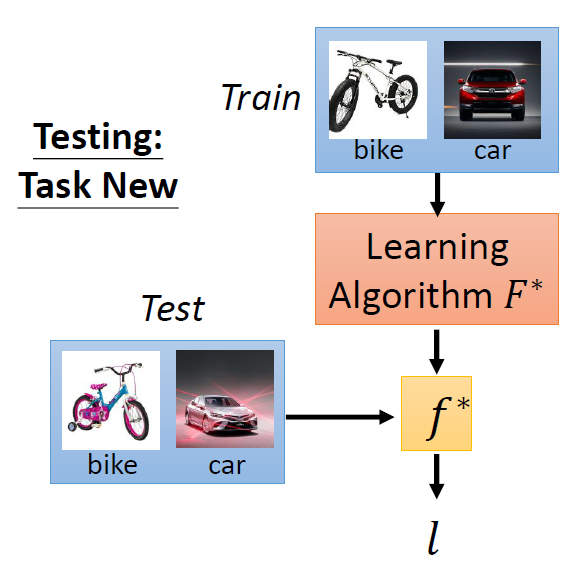
- 元学习中的testing task可以和training task一样,也可以不一样。
Omniglot


N-ways N个类别,K-shot K个样本
Meta learning实例:MAML

MAML:模型无关的元学习
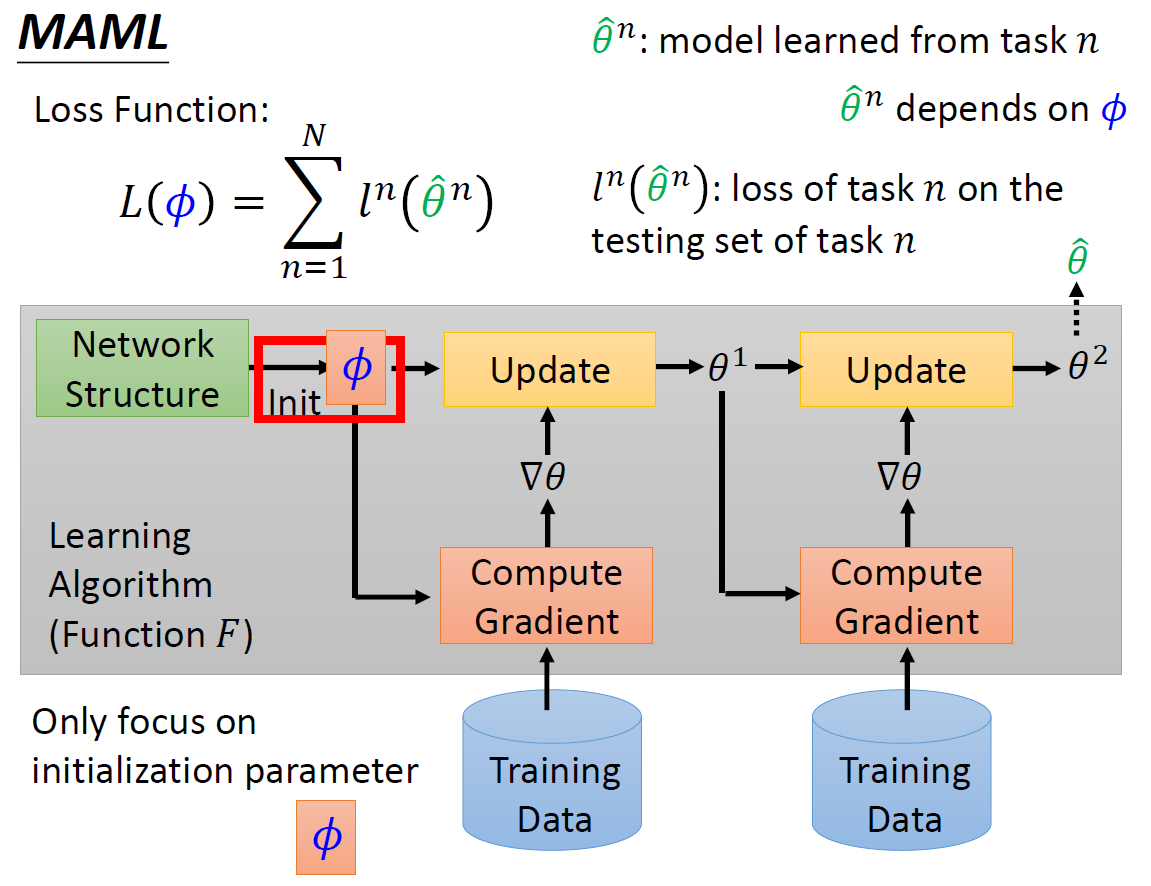
MAML 学一个最好的Initial Parameter。如何知道Initial Parameter的效果呢? 在不同的task中去训练,看最终学出来的model是否一样。
损失函数L(ϕ) 的值为任务1-N的测试集上的损失值之和。
最小化损失函数,则用梯度下降法。


在迁移学习中广泛使用Model Pr-traing,其损失值函数是使用现有的模型去计算loss(看模型当前的表现),而MAML是用ϕ 训练之后的模型来计算loss(看模型的潜力)。
具体示例
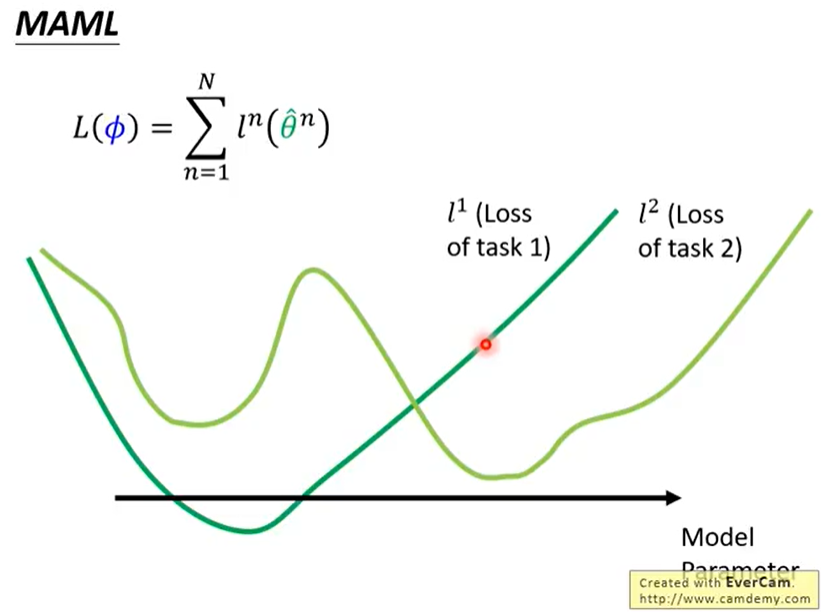
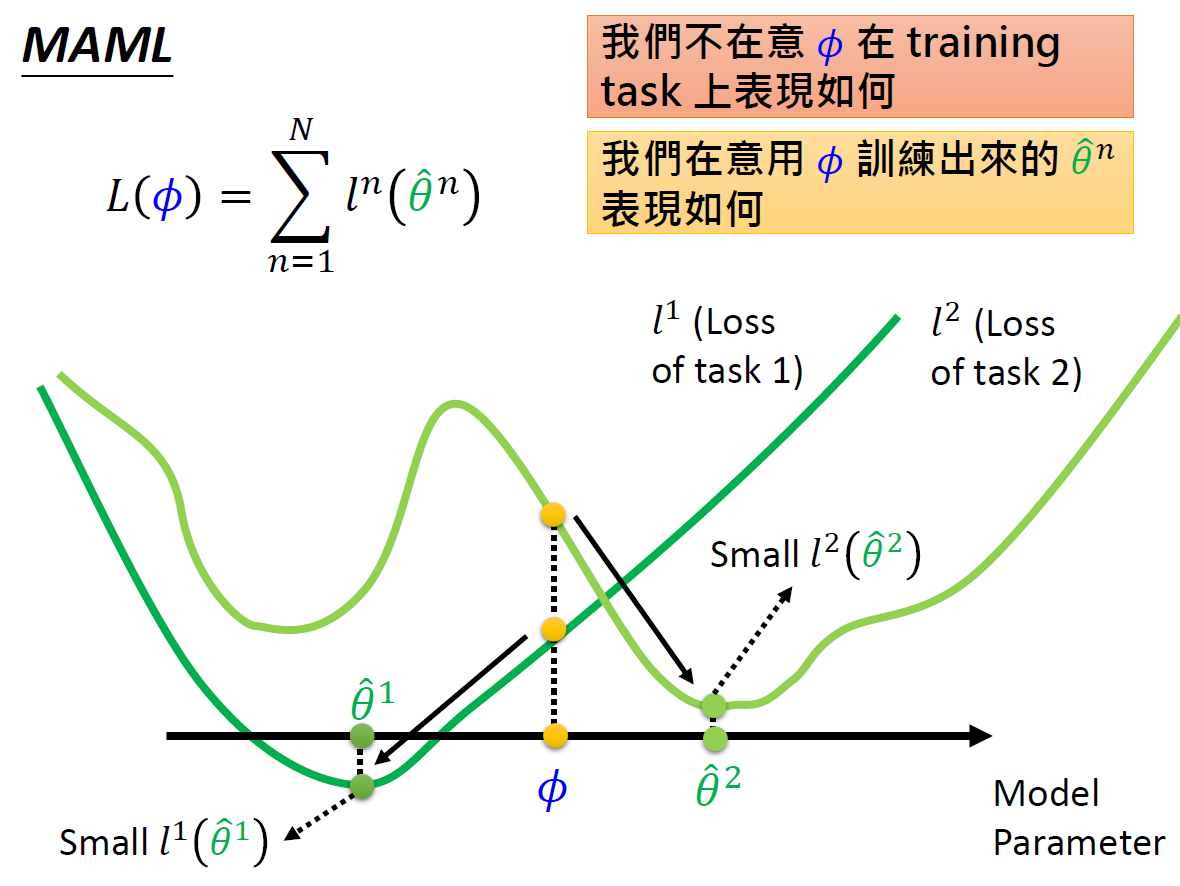

MAML与Model Pre-training

Model Pre-training看的是现在的model表现如何
MAML看的是训练之后的Model表现如何(潜力)
举例:当你即将毕业时,是准备工作还是读博?工作–Model Pre-training,读博–MAML
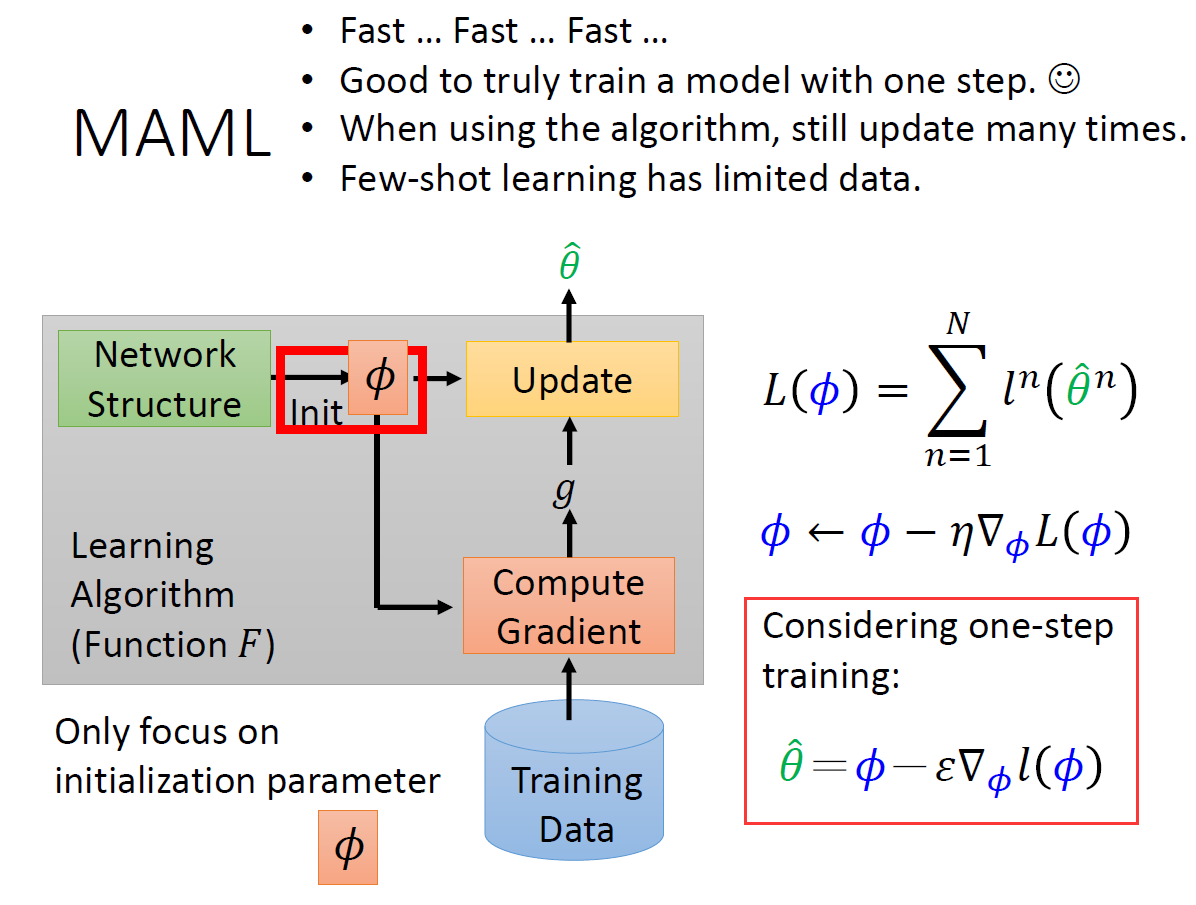
在上面讲的MAML更新参数的过程中,一般只会更新一次。
数学部分见slides及参考文献
MAML应用:Translation
Meta-Learning for Low-Resource Neural Machine Translation
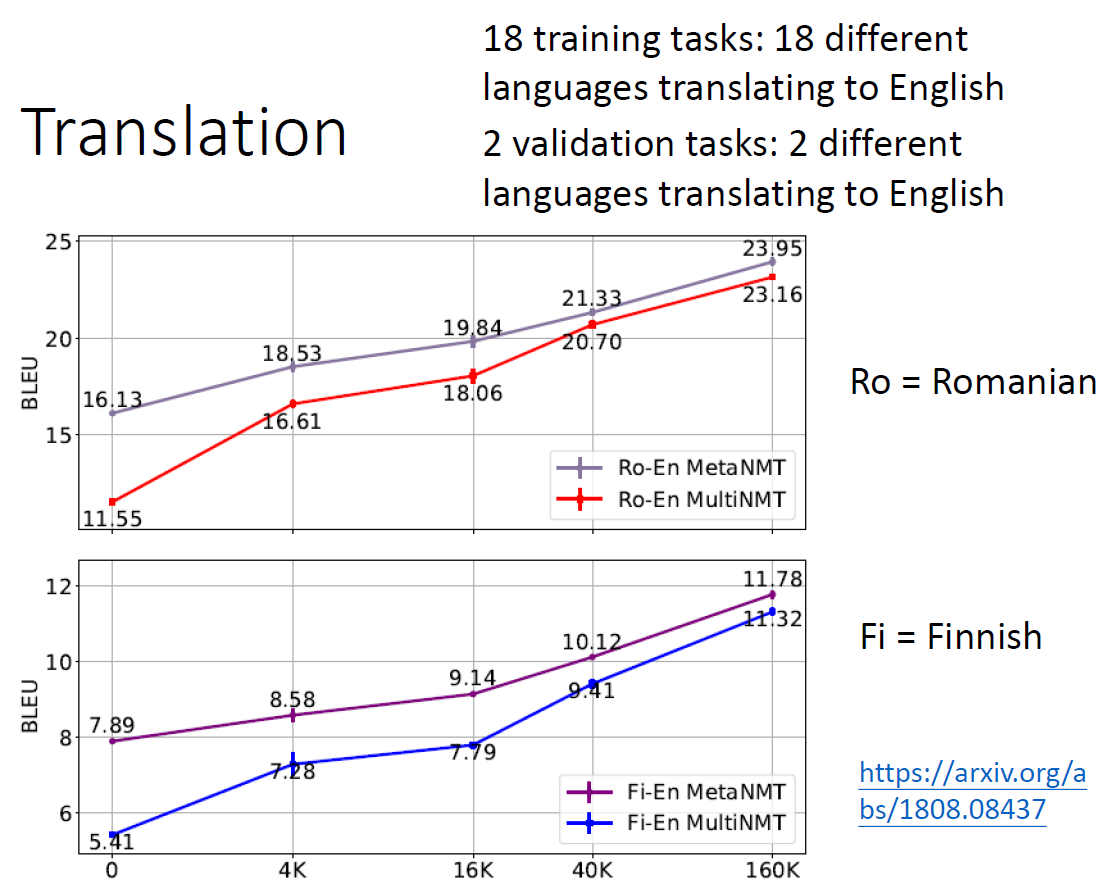
实验结果中用的是BLEU来做评估,横轴是数据量,当然数据量越大效果越好。 Baseline是多任务学习。 验证集结果(上图),罗马语翻译为英文
测试任务结果(下图),法语翻译英文
More about Meta Learning
上面讲的MAML和Reptile都是关于用Meta Learning来找初始化参数这个事情,那我们在介绍Meta Learning的时候还有很多红色框框,这些也是可以用Meta Learning来进行研究如何学习的。 不过弹幕提示:只有初始化参数这里可以用GD 下图是用network来设计Architecture & Activation,以及如何更新参数。
下面套娃预警: We learn the initialization parameter ϕ \phiϕ by gradient descent. What is the initialization parameter ϕ 0 \phi^0ϕ0 for initialization parameter ϕ \phiϕ?
How about learning algorithm beyond gradient descent?
参考文献
文章作者 fzhiy
上次更新 2020-10-22